Article
hive-on-spark snappy on centos5
hive的assembly包就是一个坑货!既然是一个单独的可运行的jar放到lib包下面干嘛呢!!纯属记录工作过程总的经历,想找干货的飘过吧!!
上周支撑部门其他项目的hadoop项目,由于 hive mr 比较慢,想用spark试一试看能不能优化。但是系统使用Centos5,我们项目使用的是Centos6。按部就班的编译呗,hive-on-saprk启用SNAPPY的必要条件:
- hadoop使用snappy需要native的支持,首先当然是Centos5上编译hadoop。(现在看来可以不必要,但每次hdfs命令都提示我native的错误就很不爽)
- hive增加spark。
各程序版本信息:
- hadoop-2.6.3
- hive-1.2.1
- spark-1.3.1
- centos5.4
# 编译hadoop-snappy
- centos5手动
[root@localhost snappy-1.1.3]# ./autogen.sh
Remember to add `AC_PROG_LIBTOOL' to `configure.ac'.
You should update your `aclocal.m4' by running aclocal.
libtoolize: `config.guess' exists: use `--force' to overwrite
libtoolize: `config.sub' exists: use `--force' to overwrite
libtoolize: `ltmain.sh' exists: use `--force' to overwrite
Makefile.am:4: Libtool library used but `LIBTOOL' is undefined
Makefile.am:4:
Makefile.am:4: The usual way to define `LIBTOOL' is to add `AC_PROG_LIBTOOL'
Makefile.am:4: to `configure.ac' and run `aclocal' and `autoconf' again.
Makefile.am:20: `dist_doc_DATA' is used but `docdir' is undefined
在centos5上面手动编译搞不定,不是专业写C的,这些问题就是天书啊(查了很多资料,试了很多方法都没通)!! Snappy可以在centos6上面编译,编译好以后再centos5上面也能用,编译hadoop-snappy也是ok的 。
- centos5-rpm
这里直接用rpm安装snappy。觉得创建虚拟机麻烦的话,也可以用docker。docker不同版本的centos下载: https://github.com/CentOS/sig-cloud-instance-images/ 。然后docker共享host主机的文件: docker run -ti -v /home/hadoop:/home/hadoop -v /opt:/opt -v /data:/data centos:centos5 /bin/bash
[root@8fb11f6b3ced ~]# cat /etc/redhat-release
CentOS release 5.11 (Final)
https://www.rpmfind.net/linux/rpm2html/search.php?query=snappy
https://www.rpmfind.net/linux/rpm2html/search.php?query=snappy-devel
[root@8fb11f6b3ced hadoop-2.6.3-src]# rpm -ivh snappy-1.0.5-1.el5.x86_64.rpm
[root@8fb11f6b3ced hadoop-2.6.3-src]# rpm -ivh snappy-devel-1.0.5-1.el5.x86_64.rpm
[root@8fb11f6b3ced hadoop-2.6.3-src]# rpm -ql snappy-devel snappy
/usr/include/snappy-c.h
/usr/include/snappy-sinksource.h
/usr/include/snappy-stubs-public.h
/usr/include/snappy.h
/usr/lib64/libsnappy.so
/usr/share/doc/snappy-devel-1.0.5
/usr/share/doc/snappy-devel-1.0.5/format_description.txt
/usr/lib64/libsnappy.so.1
/usr/lib64/libsnappy.so.1.1.3
/usr/share/doc/snappy-1.0.5
/usr/share/doc/snappy-1.0.5/AUTHORS
/usr/share/doc/snappy-1.0.5/COPYING
/usr/share/doc/snappy-1.0.5/ChangeLog
/usr/share/doc/snappy-1.0.5/NEWS
/usr/share/doc/snappy-1.0.5/README
[root@8fb11f6b3ced hadoop-2.6.3-src]# export JAVA_HOME=/opt/jdk1.7.0_17
[root@8fb11f6b3ced hadoop-2.6.3-src]# export MAVEN_HOME=/opt/apache-maven-3.3.9
[root@8fb11f6b3ced hadoop-2.6.3-src]# export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$PATH
[root@8fb11f6b3ced hadoop-2.6.3-src]#
[root@8fb11f6b3ced hadoop-2.6.3-src]# yum install which gcc gcc-c++ zlib-devel make -y
[root@8fb11f6b3ced hadoop-2.6.3-src]#
[root@8fb11f6b3ced hadoop-2.6.3-src]# cd protobuf-2.5.0
[root@8fb11f6b3ced hadoop-2.6.3-src]# ./configure
[root@8fb11f6b3ced hadoop-2.6.3-src]# make && make install
[root@8fb11f6b3ced hadoop-2.6.3-src]#
[root@8fb11f6b3ced hadoop-2.6.3-src]# which protoc
[root@8fb11f6b3ced hadoop-2.6.3-src]#
[root@8fb11f6b3ced hadoop-2.6.3-src]# yum install cmake openssl openssl-devel -y
[root@8fb11f6b3ced hadoop-2.6.3-src]# cd hadoop-2.6.3-src/
# bundle.snappy和snappy.lib一起使用,可以把系统的snappy.so文件拷贝到lib/native下面(方便拷贝)
# <http://grepcode.com/file/repo1.maven.org/maven2/org.apache.hadoop/hadoop-project-dist/2.6.0/META-INF/maven/org.apache.hadoop/hadoop-project-dist/pom.xml>
[root@8fb11f6b3ced hadoop-2.6.3-src]# mvn clean package -Dmaven.javadoc.skip=true -DskipTests -Drequire.snappy=true -Dbundle.snappy=true -Dsnappy.lib=/usr/lib64 -Pdist,native
[root@8fb11f6b3ced hadoop-2.6.3-src]# ll hadoop-dist/target/hadoop-2.6.3/lib/native/
total 3808
-rw-r--r-- 1 root root 1036552 Apr 12 09:35 libhadoop.a
-rw-r--r-- 1 root root 1212600 Apr 12 09:36 libhadooppipes.a
lrwxrwxrwx 1 root root 18 Apr 12 09:35 libhadoop.so -> libhadoop.so.1.0.0
-rwxr-xr-x 1 root root 613267 Apr 12 09:35 libhadoop.so.1.0.0
-rw-r--r-- 1 root root 401836 Apr 12 09:36 libhadooputils.a
-rw-r--r-- 1 root root 364026 Apr 12 09:35 libhdfs.a
lrwxrwxrwx 1 root root 16 Apr 12 09:35 libhdfs.so -> libhdfs.so.0.0.0
-rwxr-xr-x 1 root root 229672 Apr 12 09:35 libhdfs.so.0.0.0
lrwxrwxrwx 1 root root 18 Apr 12 09:35 libsnappy.so -> libsnappy.so.1.1.3
lrwxrwxrwx 1 root root 18 Apr 12 09:35 libsnappy.so.1 -> libsnappy.so.1.1.3
-rwxr-xr-x 1 root root 21568 Apr 12 09:35 libsnappy.so.1.1.3
[root@8fb11f6b3ced hadoop-2.6.3-src]# cd hadoop-dist/target/hadoop-2.6.3/
[root@8fb11f6b3ced hadoop-2.6.3]# bin/hadoop checknative -a
16/04/12 09:38:29 WARN bzip2.Bzip2Factory: Failed to load/initialize native-bzip2 library system-native, will use pure-Java version
16/04/12 09:38:29 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /data/bigdata/sources/hadoop-2.6.3-src/hadoop-dist/target/hadoop-2.6.3/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
snappy: true /data/bigdata/sources/hadoop-2.6.3-src/hadoop-dist/target/hadoop-2.6.3/lib/native/libsnappy.so.1
lz4: true revision:99
bzip2: false
openssl: false org.apache.hadoop.crypto.OpensslCipher.initIDs()V
16/04/12 09:38:29 INFO util.ExitUtil: Exiting with status 1
把native下面的打tar包,然后替换生产的。一切都是正常的。接下来坑爹的是spark-snappy,具体的说应该是hive-assmably坑!!
# hive-on-spark snappy
spark官网也没讲使用snappy需要做什么额外的配置(默认spark.io.compression.codec默认为snappy)。部署后设置 hive.execution.engine=spark 执行spark查询,立马就报错了 ** Caused by: java.lang.UnsatisfiedLinkError: /tmp/snappy-1.0.5-libsn
appyjava.so: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.9’ not found (required by /tmp/snappy-1.0.5-libsnappyjava.so)** 从错误堆栈看与hadoop-native-snappy没关系,而是一个snappy-java的包。
[hadoop@file1 ~]$ strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
GLIBCXX_3.4
GLIBCXX_3.4.1
GLIBCXX_3.4.2
GLIBCXX_3.4.3
GLIBCXX_3.4.4
GLIBCXX_3.4.5
GLIBCXX_3.4.6
GLIBCXX_3.4.7
GLIBCXX_3.4.8
GLIBCXX_FORCE_NEW
确实缺少GLIBCXX_3.4.9,最新版本的centos5.11也是一样输出的。
spark的配置为:
spark.yarn.jar hdfs:///spark/spark-assembly-1.3.1-hadoop2.6.3.jar
spark.master yarn-client
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.minExecutors 2
spark.dynamicAllocation.maxExecutors 18
spark.driver.maxResultSize 0
spark.master=yarn-client
spark.driver.memory=5g
spark.eventLog.enabled true
spark.eventLog.compress true
spark.eventLog.dir hdfs:///spark-eventlogs
spark.yarn.historyServer.address file1:18080
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.kryoserializer.buffer.max 512m
报错的具体信息:
- 16/04/12 20:20:08 INFO storage.BlockManagerMaster: Registered BlockManager
- java.lang.reflect.InvocationTargetException
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.xerial.snappy.SnappyLoader.loadNativeLibrary(SnappyLoader.java:322)
- at org.xerial.snappy.SnappyLoader.load(SnappyLoader.java:229)
- at org.xerial.snappy.Snappy.<clinit>(Snappy.java:48)
- at org.apache.spark.io.SnappyCompressionCodec.<init>(CompressionCodec.scala:150)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
- at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
- at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
- at org.apache.spark.io.CompressionCodec$.createCodec(CompressionCodec.scala:68)
- at org.apache.spark.io.CompressionCodec$.createCodec(CompressionCodec.scala:60)
- at org.apache.spark.scheduler.EventLoggingListener.<init>(EventLoggingListener.scala:67)
- at org.apache.spark.SparkContext.<init>(SparkContext.scala:400)
- at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:61)
- at org.apache.hive.spark.client.RemoteDriver.<init>(RemoteDriver.java:169)
- at org.apache.hive.spark.client.RemoteDriver.main(RemoteDriver.java:556)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:569)
- at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:166)
- at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:189)
- at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:110)
- at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
- Caused by: java.lang.UnsatisfiedLinkError: /tmp/snappy-1.0.5-libsnappyjava.so: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.9' not found (required by /tmp/snappy-1.0.5-libs
- at java.lang.ClassLoader$NativeLibrary.load(Native Method)
- at java.lang.ClassLoader.loadLibrary1(ClassLoader.java:1965)
- at java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1890)
- at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1851)
- at java.lang.Runtime.load0(Runtime.java:795)
- at java.lang.System.load(System.java:1062)
- at org.xerial.snappy.SnappyNativeLoader.load(SnappyNativeLoader.java:39)
- ... 28 more
spark用到了snappy-java来处理snappy的解压缩。用jinfo获取SparkSubmit进程的classpath,用这个classpath跑helloworld确实是报错的,但是单独用hadoop-common下面的 snappy-java-1.0.4.1.jar 是没问题的。
[hadoop@file1 snappy-java-test]$ cat Hello.java
import org.xerial.snappy.Snappy;
public class Hello {
public static void main(String[] args) throws Exception {
String input = "Hello snappy-java!";
byte[] compressed = Snappy.compress(input.getBytes("utf-8"));
byte[] uncompressed = Snappy.uncompress(compressed);
String result = new String(uncompressed, "utf-8");
System.out.println(result);
}
}
[hadoop@file1 snappy-java-test]$ java -cp .:/home/hadoop/tools/hadoop-2.6.3/share/hadoop/common/lib/snappy-java-1.0.4.1.jar Hello
Hello snappy-java!
而而而,classpath中就只有hadoop-common和hadoop-mapreduce下面有snappy-java包,并且都是1.0.4.1,那TMD的使用SparkSubmit-classpath加载Snappy是哪个jar里面的呢?
调整后的helloworld为:
[hadoop@file1 snappy-java-test]$ cat Hello.java
import org.xerial.snappy.Snappy;
public class Hello {
public static void main(String[] args) throws Exception {
String input = "Hello snappy-java!";
System.out.println(Snappy.class.getProtectionDomain());
byte[] compressed = Snappy.compress(input.getBytes("utf-8"));
byte[] uncompressed = Snappy.uncompress(compressed);
String result = new String(uncompressed, "utf-8");
System.out.println(result);
}
}
添加getProtectionDomain查看加载类的jar。再编译跑一次,这次终于找到真凶了!!hive-assembly,assembly包还放在lib下面就tmd的是一个坑货!!hive-exec的guava已经坑了很多人了,这次换hive-jdbc了!!(我这里的环境是centos5,centos6是没有这个问题的!!)
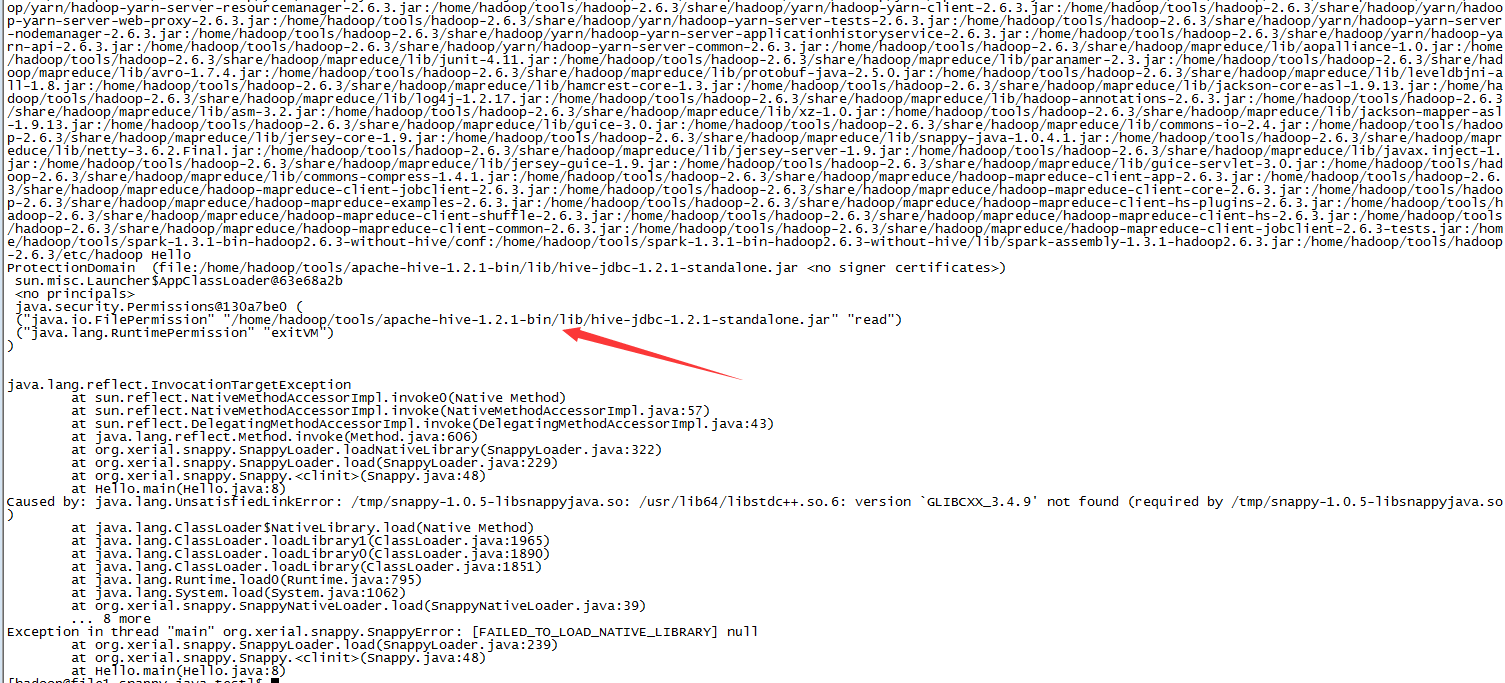
如果指定使用hadoop编译依赖的snappy.so.1.1.3动态链接库会出现版本不兼容的问题。还是干掉hive-jdbc-standalone吧。。。囧
# 查看源码SnappyLoader#loadSnappySystemProperties,可以通过配置指定使用系统动态链接库
[hadoop@file1 snappy-java-test]$ cat org-xerial-snappy.properties
org.xerial.snappy.use.systemlib=true
[hadoop@file1 snappy-java-test]$ ln -s /home/hadoop/tools/hadoop-2.6.3/lib/native/libsnappy.so libsnappyjava.so
[hadoop@file1 snappy-java-test]$ ll
总计 1240
-rw-rw-r-- 1 hadoop hadoop 854 04-08 10:11 Hello.class
-rw-rw-r-- 1 hadoop hadoop 408 04-08 10:11 Hello.java
lrwxrwxrwx 1 hadoop hadoop 55 04-12 19:37 libsnappyjava.so -> /home/hadoop/tools/hadoop-2.6.3/lib/native/libsnappy.so
-rw-rw-r-- 1 hadoop hadoop 37 04-12 19:15 org-xerial-snappy.properties
-rw-r--r-- 1 hadoop hadoop 1251514 2014-04-29 snappy-java-1.0.5.jar
[hadoop@file1 snappy-java-test]$ java -cp .:snappy-java-1.0.5.jar -Djava.library.path=. Hello
ProtectionDomain (file:/home/hadoop/snappy-java-test/snappy-java-1.0.5.jar <no signer certificates>)
sun.misc.Launcher$AppClassLoader@333cb1eb
<no principals>
java.security.Permissions@7377711 (
("java.io.FilePermission" "/home/hadoop/snappy-java-test/snappy-java-1.0.5.jar" "read")
("java.lang.RuntimePermission" "exitVM")
)
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.xerial.snappy.SnappyNative.maxCompressedLength(I)I
at org.xerial.snappy.SnappyNative.maxCompressedLength(Native Method)
at org.xerial.snappy.Snappy.maxCompressedLength(Snappy.java:320)
at org.xerial.snappy.Snappy.rawCompress(Snappy.java:333)
at org.xerial.snappy.Snappy.compress(Snappy.java:92)
at Hello.main(Hello.java:8)
删掉jdbc-standalone后,hive-on-spark就ok了。如果你无法下手删除 hive-jdbc-1.2.1-standalone.jar ,那就把 spark.io.compression.codec 改成 lz4 等压缩也是可以的。
[hadoop@file1 ~]$ hive
Logging initialized using configuration in file:/home/hadoop/tools/apache-hive-1.2.1-bin/conf/hive-log4j.properties
hive> set hive.execution.engine=spark;
hive> select count(*) from t_info where edate=20160411;
Query ID = hadoop_20160412205338_2c95c5fd-af50-42ba-8681-e154e4b74cb1
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Spark Job = 69afc030-fa1f-4fdf-81ef-12bdca411a4f
Query Hive on Spark job[0] stages:
0
1
Status: Running (Hive on Spark job[0])
Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount [StageCost]
2016-04-12 20:54:11,367 Stage-0_0: 0(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:14,421 Stage-0_0: 0(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:17,457 Stage-0_0: 0(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:19,486 Stage-0_0: 2(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:20,497 Stage-0_0: 3(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:21,509 Stage-0_0: 5(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:22,520 Stage-0_0: 6(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:23,532 Stage-0_0: 7(+2)/234 Stage-1_0: 0/1
# 小结
第一,hive的assembly的包太tmd的坑了。第二,以后找java具体加载那个类,可以通过 class.getProtectionDomain 来获取了。第三,又多尝试一个环境部署hadoop。呵呵
–END
Related
Related posts
-
基于对象存储的 Spark 数据读写实战:从末尾追加到任意更新
2025-10-28
-
科学上网(续)
2018-06-09
-
使用Sphinx生成/管理文档
2017-11-16
-
windows run ubuntu
2017-10-29