Article
SparkSQL查看调试生成代码
网站和一些书籍都有介绍SparkSQL(DataFrame)会根据相应的操作生成最终运行的语句。这里从一个简单的、低级的问题入手到最后通过查看生成的代码查找问题的根源,并简单介绍怎么来调试SparkSQL。
问题来源:
case class Access(id:String,url:String,time:String){
def compute():(String, Int)
}
Object Access {
def apply(row:Row): Option[Access]
}
# main
df.map(Access(_)).filter(!_.isEmpty).map(_.get).map(_.compute)
运行之后 compute 总是报 NullPointerException 异常。按RDD以及Scala的操作都是没法理解的,怎么就变成 Access(null,null,null) 了呢?后面尽管改成 df.flatMap(Access(_)).map(_.compute) 后运行正常了,但是还是想看看SparkSQL到底干了啥!!!
# SparkSQL干了什么
Spark RDD是在 RDD#compute 中明确定义好了操作的。而SparkSQL的操作最终转换成了LogicalPlan,看不出它做了什么东东。
其实,与数据库SQL的explain看执行计划类似,SparkSQL也有explain的方法来查看程序的执行计划。(这里代码全部贴出来了,根据情况自己去掉注释啊)
object AccessAnalyser {
def main(args: Array[String]): Unit = {
// conf
// clean
new File("target/generated-sources").listFiles().filter(_.isFile()).foreach(_.delete)
sys.props("org.codehaus.janino.source_debugging.enable") = "true"
sys.props("org.codehaus.janino.source_debugging.dir") = "target/generated-sources"
val input = "r:/match10.dat"
val output = "r:/output"
def delete(f: File): Unit = {
if (f.isDirectory) f.listFiles().foreach(delete)
f.delete()
}
delete(new File(output))
// program
val conf = new SparkConf().setAppName("DPI Analyser").setMaster("local[10]")
// fix windows path.
conf.set(/*SQLConf.WAREHOUSE_PATH*/ "spark.sql.warehouse.dir", "spark-warehouse")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
import org.apache.spark.sql.functions._
val df = sqlContext.read
.format("com.databricks.spark.csv")
.option("header", "false") // Use first line of all files as header
.option("quote", "'")
.option("escape", "'")
.option("delimiter", ",")
.load(input)
df
.flatMap(Access(_))
// .map(Access(_)).filter((t: Option[Access]) => !t.isEmpty).map(_.get) // sparksql不合适用Option
.map(_.compute)
.explain(true)
// .toDF("id", "score")
// .groupBy("id").agg(sum("score") as "score")
// .sort("score", "id")
// .repartition(1)
// .write.format("com.databricks.spark.csv").save(output)
sc.stop()
}
}
运行上面的代码,在console窗口输出了任务的执行计划:
== Parsed Logical Plan ==
'SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true], top level non-flat input object)._1, true) AS _1#20, assertnotnull(input[0, scala.Tuple2, true], top level non-flat input object)._2 AS _2#21]
+- 'MapElements <function1>, obj#19: scala.Tuple2
+- 'DeserializeToObject unresolveddeserializer(newInstance(class com.github.winse.spark.access.Access)), obj#18: com.github.winse.spark.access.Access
+- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, com.github.winse.spark.access.Access, true], top level non-flat input object).id, true) AS id#12, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, com.github.winse.spark.access.Access, true], top level non-flat input object).url, true) AS url#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, com.github.winse.spark.access.Access, true], top level non-flat input object).time, true) AS time#14]
+- MapPartitions <function1>, obj#11: com.github.winse.spark.access.Access
+- DeserializeToObject createexternalrow(_c0#0.toString, _c1#1.toString, _c2#2.toString, StructField(_c0,StringType,true), StructField(_c1,StringType,true), StructField(_c2,StringType,true)), obj#10: org.apache.spark.sql.Row
+- Relation[_c0#0,_c1#1,_c2#2] csv
== Physical Plan ==
*SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true], top level non-flat input object)._1, true) AS _1#20, assertnotnull(input[0, scala.Tuple2, true], top level non-flat input object)._2 AS _2#21]
+- *MapElements <function1>, obj#19: scala.Tuple2
+- MapPartitions <function1>, obj#11: com.github.winse.spark.access.Access
+- DeserializeToObject createexternalrow(_c0#0.toString, _c1#1.toString, _c2#2.toString, StructField(_c0,StringType,true), StructField(_c1,StringType,true), StructField(_c2,StringType,true)), obj#10: org.apache.spark.sql.Row
+- *Scan csv [_c0#0,_c1#1,_c2#2] Format: CSV, InputPaths: file:/r:/match10.dat, PushedFilters: [], ReadSchema: struct<_c0:string,_c1:string,_c2:string>
OK,看到执行计划了,那生成的代码长什么样呢?以及怎么调试这些生成的代码呢?
# Hack 源码
在进行调试之前,先改一下代码重新编译下catalyst用于调试,并替换maven下面的spark-catalyst_2.11 :
winse@Lenovo-PC ~/git/spark/sql/catalyst
$ git diff .
diff --git a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala b/sql/catalyst/ src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
index 16fb1f6..56bfbf7 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
@@ -854,7 +854,7 @@ object CodeGenerator extends Logging {
val parentClassLoader = new ParentClassLoader(Utils.getContextOrSparkClassLoader)
evaluator.setParentClassLoader(parentClassLoader)
// Cannot be under package codegen, or fail with java.lang.InstantiationException
- evaluator.setClassName("org.apache.spark.sql.catalyst.expressions.GeneratedClass")
evaluator.setDefaultImports(Array(
classOf[Platform].getName,
classOf[InternalRow].getName,
@@ -875,12 +875,14 @@ object CodeGenerator extends Logging {
logDebug({
// Only add extra debugging info to byte code when we are going to print the source code.
- evaluator.setDebuggingInformation(true, true, false)
+ evaluator.setDebuggingInformation(true, true, true)
s"\n$formatted"
})
try {
- evaluator.cook("generated.java", code.body)
+ evaluator.cook(code.body)
recordCompilationStats(evaluator)
} catch {
case e: Exception =>
E:\git\spark\sql\catalyst>mvn clean package -DskipTests -Dmaven.test.skip=true
SparkSQL生成代码用的是janino,官网文档有提供debugging的资料:http://janino-compiler.github.io/janino/#debugging 。简单说明下三处修改:
- 查看org.codehaus.janino.Scanner构造方法,如果配置了debugging以及optionalFileName==null就会把源码保存到临时文件。
- 一开始没想到要注释掉setClassName的,后面把CodeGenerator#doCompile拷贝出来慢慢和官网提供的例子对,就把setClassName换成setExtendedClass竟然成了弹出了源码页面。又看到下面就setExtendedClass就注释掉setClassName就ok了。
- 源代码里面的参数不能查看的,就是编译的时刻把这个选项去掉了。把debugVars设置为true。
# 运行调试
先做好调试准备工作:
- 在compute方法里面打一个断点然后调试运行
- 修改log4j日志级别: log4j.logger.org.apache.spark.sql.catalyst.expressions.codegen=DEBUG
- 把项目导入eclipse(IDEA弹不出源代码)
然后运行。点击Debug视图的GeneratedIterator,在弹出的代码视图点击查找源码按钮,再弹出的添加源代码对话框(Edit Source Lookup Path)添加路径target/generated-sources(注意这里要用绝对路径)!接下来就一步步的调就行了。
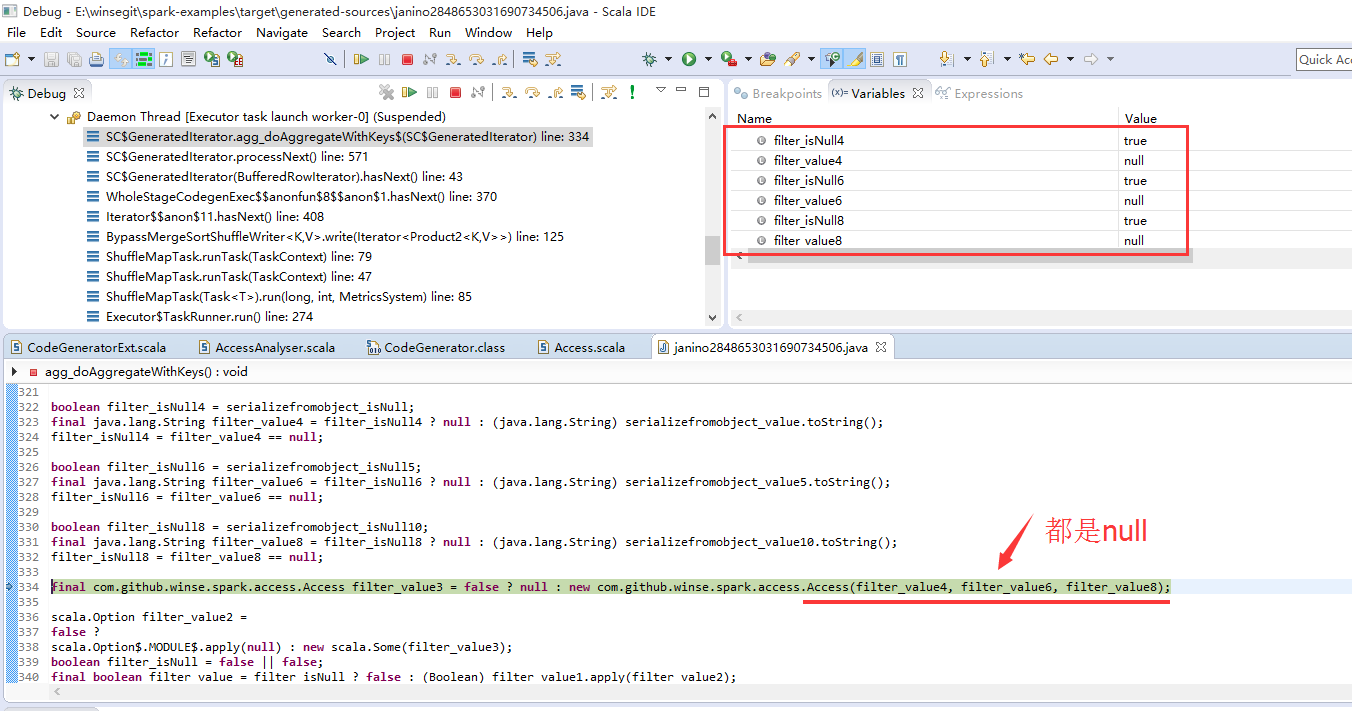
调试着生成的代码能更好的理解前面explain的执行计划。看到代码就好理解最开始的Access(null,null,null)了:对象到字段反序列化的问题。
–END
Related
Related posts
-
杀鸡焉用牛刀:DuckDB 正取代部分 Spark 场景
2026-02-16
-
基于对象存储的 Spark 数据读写实战:从末尾追加到任意更新
2025-10-28
-
jarsperreports生成PDF中文问题
2017-01-21
-
jasperreports使用小结
2016-12-01