Article
富文本编辑器开发学习笔记:Carota模型
Carota是比较早的用Canvas来实现的富文本编辑器的开源项目。尽管快10年了,但文档模型和绘制渲染依然值得用来学习和参考借鉴。
DEMO: https://earwicker.com/carota/
文档中提到为什么要重新写一个富文本编辑器:
-
contenteditable功能过于强大,掌握困难。
-
不同浏览器表现不一。
-
完全控制困难,自定义功能受限。
所以作者在Canvas上编写了一个简化版,但是完全自主控制的富文本编辑器。
为了方便阅读、分析和调试,我把原本的 Javascript版本 改写成了使用 Typescript+Webpack 来实现,这样阅读代码的时刻可以跟踪、Ctrl点击进去。查看源代码点击最后的原文链接。
# 数据流
在上一篇中,我们学习了腾讯的编辑器架构:
用户输入 -> 解析为数据模型 -> 然后排版引擎测量布局形成视图模型 -> 最终渲染引擎绘制到画布上。
Carota整体结构跟它类似,也是由这四大部分构成,且实现的相对简单,是用来入门学习的不二之选。
本文主要聚焦它的 数据模型 和 视图模型,以及其数据流的处理。下一篇我们再研究它的 用户交互 和 绘制渲染 。
# 存储模型
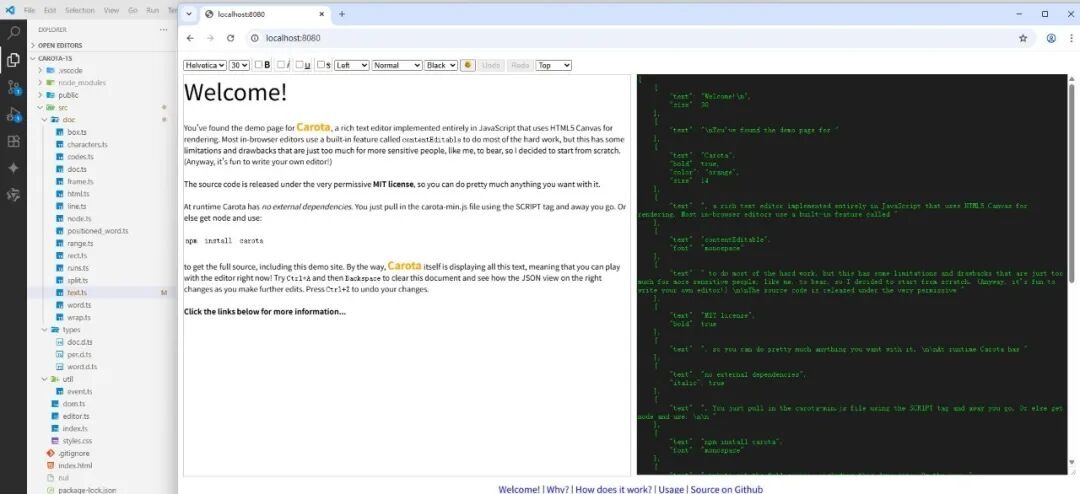
在富文本编辑器中,相同样式的一段文本,我们把它叫做TextRun。Carota的核心数据就是一个 Run[] 数组。
Run由两部分组成:一个text的文本(字符串或者内嵌对象),以及可选的文本样式(如:bold、italic等)。参见下图右边的黑色编辑框中的内容:
# 数据模型
首先编辑器对存储数据进行提取、拆分,再经过断行处理,形成编辑器需要的内部模型。
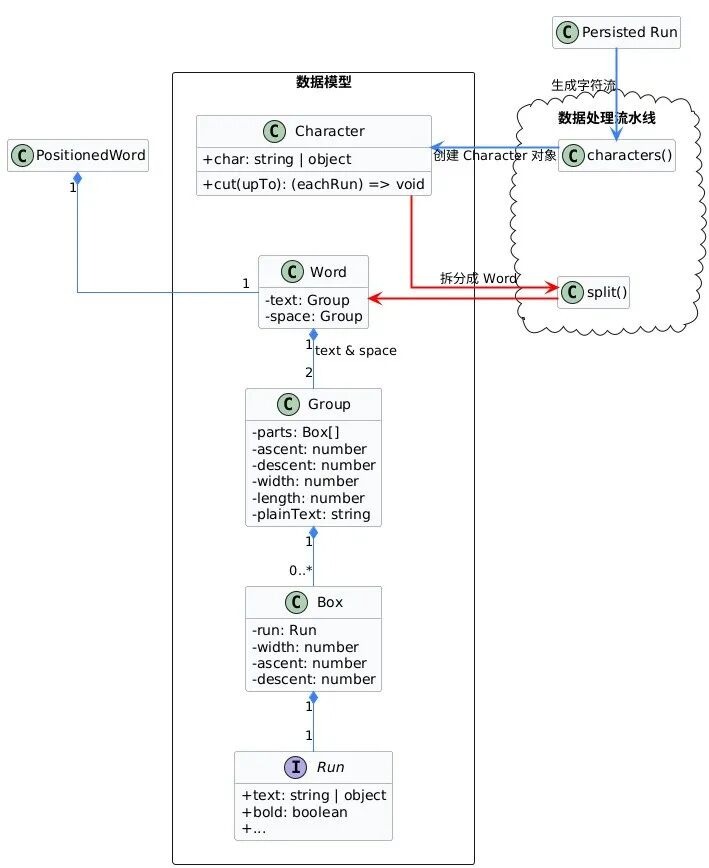
characters() 方法从存储数据 Run[] 中提取出字素 Character 。其包括了引用原始数据 _runs 和它的索引偏移量 _run 、 _offset,方便后续精确地获取整个单词。注:对于emoji和多字节字符并没有涉及处理。

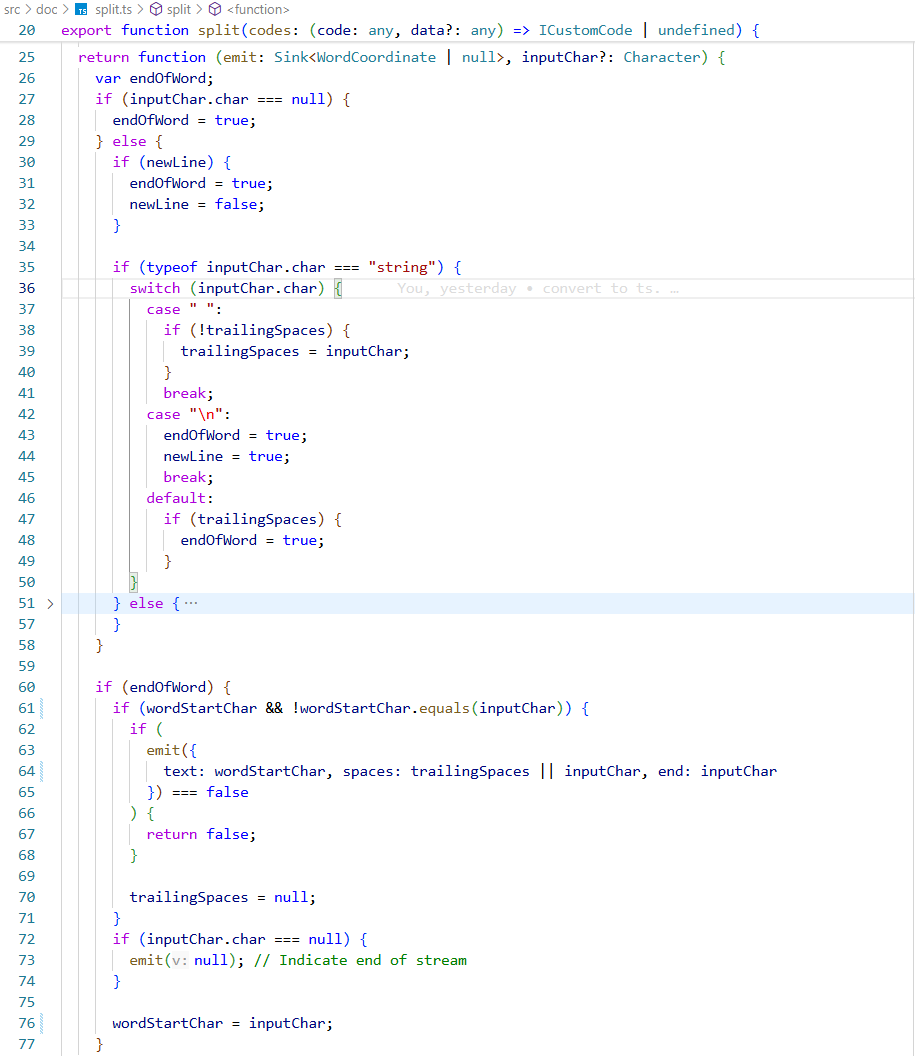
然后 split() 方法将文本分词拆分为Word对象。
使用空格和换行符来拆分单词和段落,记录单词的开始字符 wordStartChar 、空格字符和结束字符 供后续构建Word实例使用。
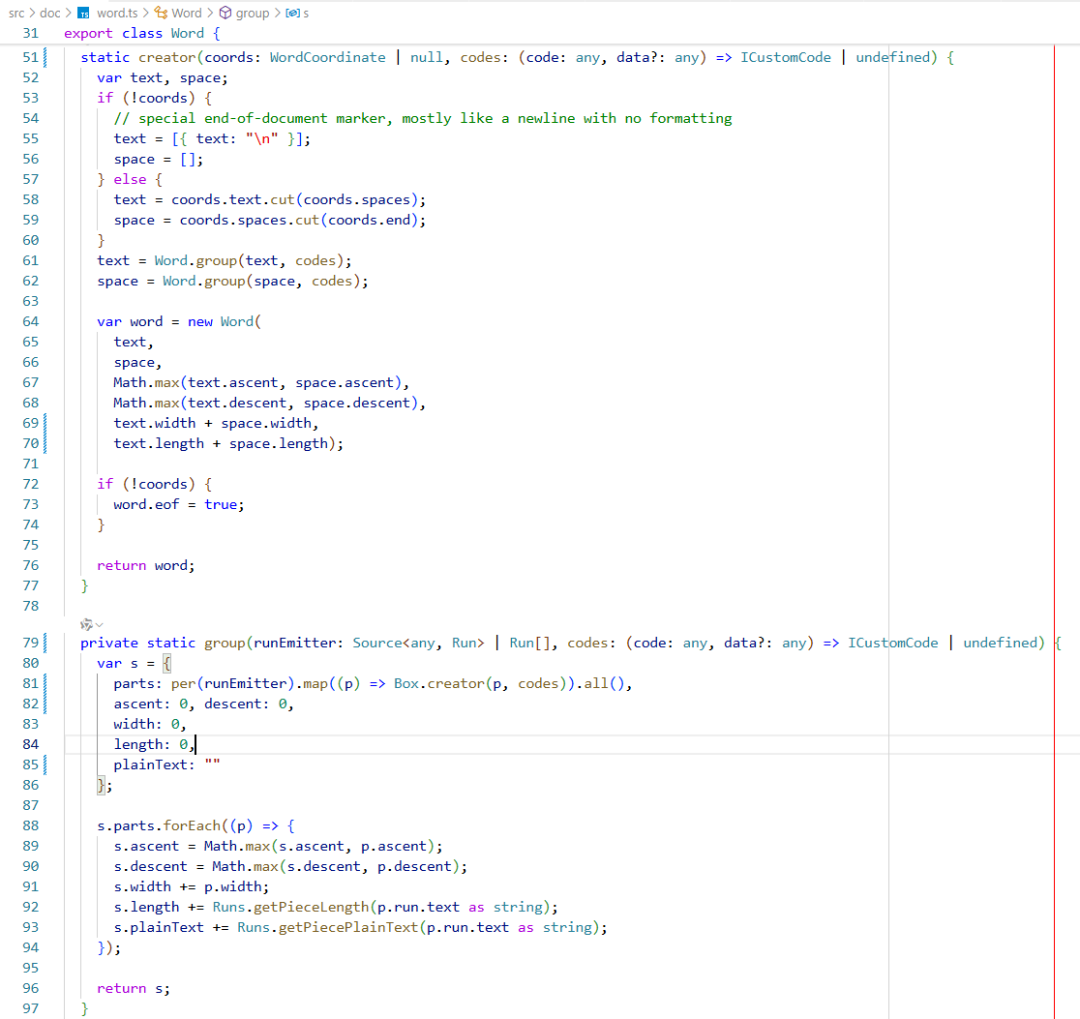
一个单词可以包含不同格式的文本区域,比如单词World,按样式拆分成若干Run段,text.cut 方法会把区间的Run提取出来,并测量每个Run的宽、高、基线信息保存为Box对象,这些Box集合又组成一个Group。空格也组成一个Group。就形成了Word类的结构,后面的光标定位、绘制渲染都要经由它来处理。
# 视图模型
前面已经拆分好了单词Word,以及测量的每个Run宽、高、基线。wrap() 主要处理断行,依次计算传入的Word单词,根据页面宽度对文本进行排版断行,根据行内单词计算得到行的最大上升Ascent、最大下降Descent,得出行高。
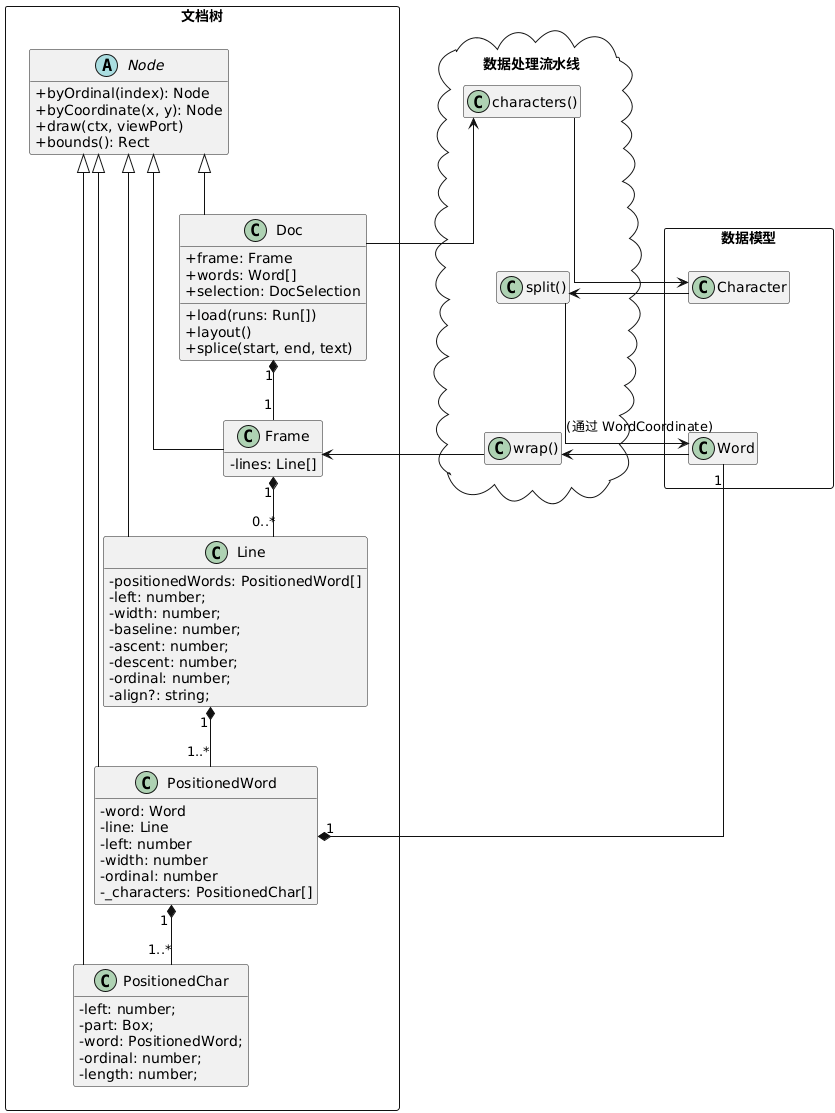
Line 对象包含若干 PositionedWord 对象列表,每个 PositionedWord 对象又包含一个 PositionedChar 对象列表。这些对象构成一个统一的节点层次结构,根节点是 Doc。
此时,所有内容节点坐标都已计算好,后面只需要按顺序遍历绘制到画布上,非常容易且高效。
注意:到这一步只是测量了每个Word的Run的宽度。每个字符PositionedChar真正的测量是在显示光标位置时才处理的。
# 小结
Carota的数据模型和视图模型的设计思路可以总结为:
从 Run -> Character -> Word -> Group -> Box 形成了清晰的数据流处理链。
在 wrap 阶段完成排版形成行Line,得出可以直接绘制渲染的视图模型。
下一篇,我们将分析 用户交互和渲染阶段,看看Carota是如何处理鼠标点击、键盘定位、光标与用户输入,并最终在画布上绘制富文本的。
Related
Related posts
-
从使用者到创造者:用 AI 构建你的专属 VS Code 工具链
2026-02-27
-
深入解析 Nano Banana:Google 技术博客四篇精华翻译
2025-08-30
-
富文本编辑器开发学习笔记:Carota输入输出-交互与渲染
2025-08-20
-
Cursor Agent 编程小小心得
2026-06-11