Article
收藏夹搬家记:上万链接导入到 IMA 知识库
最近ima知识库比较热,趁着这股热自己也充实一下。在看到说可以把网页直接加入到知识库,那是不是意味着收藏夹中的网页也可以导入知识库呢?
怀着这折腾的心,开启了这段孽缘。实际是只能导入当前查看的页面,谁叫咱是工程师,就是不服,没有咋就自己燥。看似简单的事情,多了也就不易了。而且收藏夹链接多而且杂,代码最终实现还带有爬虫性质,吃了不少苦头。
先看下效果:
# 尝试接口请求
一开始的想法,是直接调接口来实现。
我先去看了网络请求,但在前台页面的开发者“网络”面板看不出有 ima 的调用。于是我转到扩展的后台页面,果不其然在后台服务里看到了对应的请求。
不过,它的请求数据相当复杂,几乎是把整个网页的内容——包括标题、图片等等——爬取一遍,然后上传到服务器。这一块要是自己提取的话,比较麻烦了。而且整个扩展它是用 React 写的,封装也很严实,外部完全拿不到内部的方法。
下面两个图是调试过程中,提取数据、提交请求的位置:
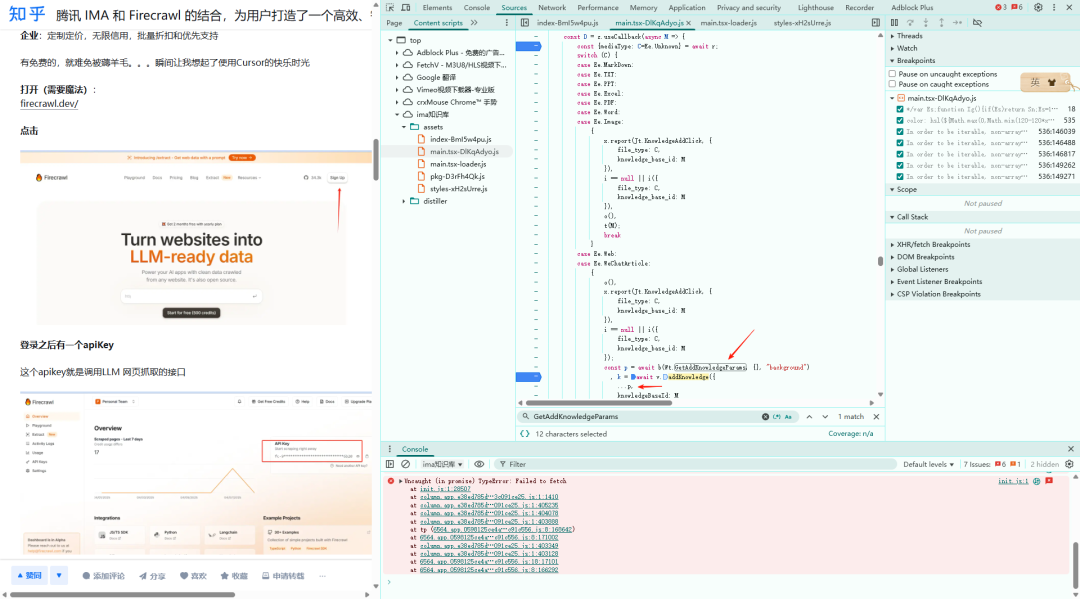
获取当前页面的知识,包括标题、图片以及网页的文本内容
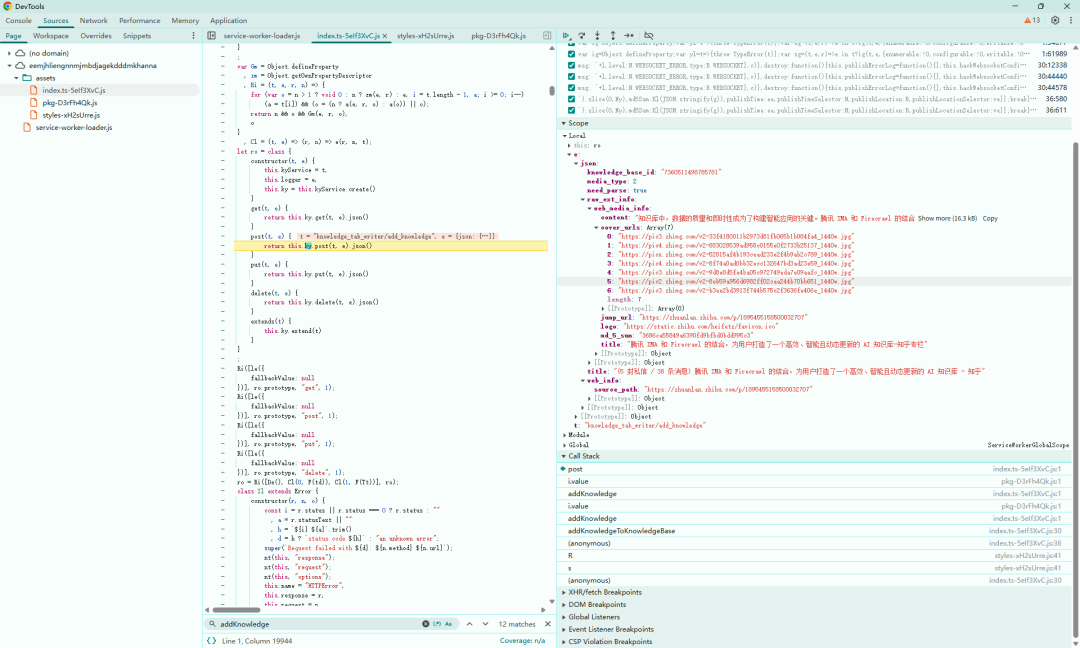
收到网页的内容后,后台线程提交服务器,把网页加入到知识库。
# 使用爬虫模拟人工操作
于是我换了个思路:能不能用类似爬虫的方式,模拟人操作 去点击鼠标,把网页加入知识库?就像手动添加一样。
有想法了,先去问问AI调研一下方法的可行性:有哪些自动化处理的库。它推荐了 Puppeteer 和 Selenium。
最后选了使用 Python 版的 Selenium。前者Puppeteer是 NodeJS 写的,相对简单新潮,但它跑的浏览器不能加载插件,就算用 user-data-dir 参数也没用。Selenium则加载扩展没问题,浏览器能直接带着 ima 插件运行。
但问题还是不少的——Selenium 只能操作页面元素,对于浏览器工具栏上的按钮却无能为力。于是又去研究浏览器的ima扩展,看怎么触发弹出面板,可惜这不属于熟悉的领域,研究一阵瞎改一通没什么效果。
这时候发现一个线索:右键里有“网页加入ima知识库”的菜单。能不能直接点它?实际还不行的,右键菜单也是系统级别的,Selenium 也点不了。
没得办法,只能用桌面自动化工具autogui 来模拟直接操控鼠标,点击工具栏上的插件按钮。为啥到最后才妥协用这种方式,是由于桌面模拟会直接控制鼠标占用机器,运行过程你就用不了电脑了。
折腾不止,生命不息。
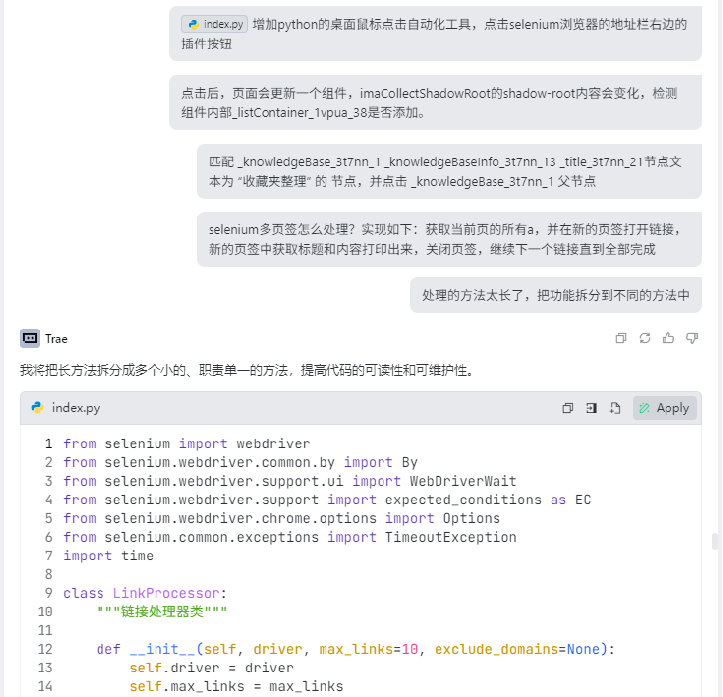
在AI加持之下,一个大几百行的 收藏夹自动导入ima知识库 的流程跑通了。具体步骤描述:
-
先新建了一个知识库,避免和已有的知识混在一起。
-
然后把常用浏览器的收藏夹 导出为 HTML 文件,用Selenium的浏览器打开它。
-
接下来就是遍历本地 HTML 页面中所有收藏的链接逐个处理:
-
在新标签页打开这个收藏的网址。
-
模拟鼠标移动到 ima 插件按钮上,点击,等待面板弹出。
-
用爬虫定位到目标知识库的按钮并点击。
-
等待“已加入该知识库”的提示后,关闭标签页。
-
继续循环处理下一个链接,直到全部处理完毕。
在自动化运行的过程中,盯了一段时间的屏幕。看到一个又一个页面被打开关闭——就如同时间得飞逝。很多收藏的链接来自 2011、2012 年,已经整整13 年过去了。那时刚参加工作,正是拼劲十足、成长迅速的阶段。
也很多页面已经无法访问了:
-
知乎、CSDN 、简书、iteye等平台的反爬限制很多;
-
天涯、百度贴吧等内容大面积消失;
-
个人网站关停的;
-
公司内部网页无法访问;
-
视频链接有直接跳转到主页。
访问不了的比例快小一半,由于模拟人工操作太耗时,报错多了可能会自动退出又得重新来,非常浪费时间。所以导入操作之前加个预处理 环节:先检测链接能否访问,404 异常的就直接过滤掉,只有正常的才进入后续流程。
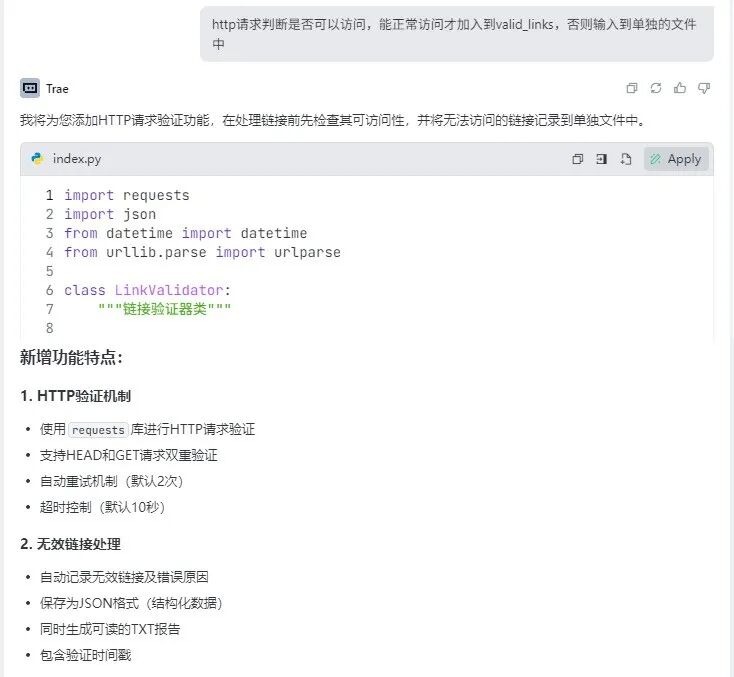
即便如此,单线程依旧太慢,于是我又加上了多线程,同时跑它 30 个线程,“呼呼”地 就快起来了,这速度终于能接受一点了。
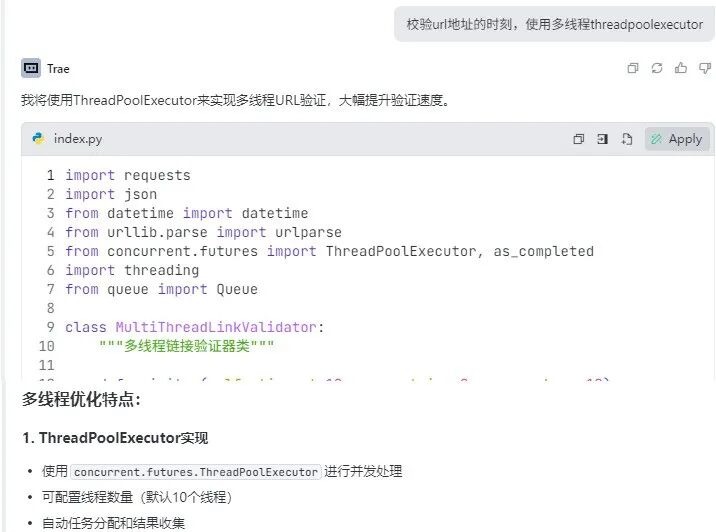
小一半的访问报错404 Not found了,能访问的就剩下7千多。但是,全部导入也很要耐心,时间还是比较久的。要问具体是多久呢?那我只能说:很久很久😂。
来感受一下自动化的效果吧:
最终:收藏夹1w3的链接,访问过滤掉后还剩7k5,导入成功的4k6。
最后的最后,不建议把 ima 当作主力浏览器去用,浏览器ima知识库插件我也不建议你常开着——它会把你的每一个操作都传回服务器。
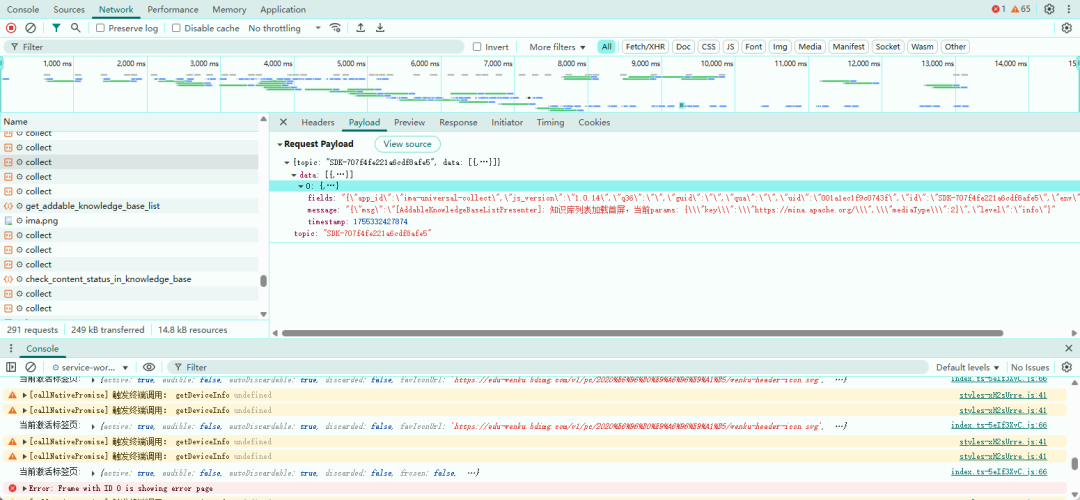
你说它是检测每个页面是不是已经加入知识库,也对。但,不觉得这很可怕,还很恶心吗?仁者见仁智者见智,但对于现在的我来说,这让我很不爽的,还不能接受!
源代码都放在gitcode了,有兴趣一起研究: https://gitcode.com/winseII/fav_ima
Related