Article
基于对象存储的 Spark 数据读写实战:从末尾追加到任意更新
很久没有碰 Spark 大数据这一块的东西了,最近需要做一些数据转换的工作,又重新捡了起来,Hadoop已经到了3.4,Spark最新的版本都4.0了。
现在流行对象存储了,Hadoop的分布式存储HDFS确实设计精妙、安全而且高效,但在灵活性和使用成本上稍显笨重。对象存储是从亚马逊AWS的 S3 来的,后面它就成了一种事实的行业标准,有点类似 OpenAI 的接口大家都去适配它。
HDFS 缺点是不适合小文件、集群运维复杂、不支持HTTP访问,而 FTP 没有容错、没有扩展能力、而且不支持随机访问。S3 可以做到无限的扩展,REST API 访问方便,支持版本控制,还带生命周期管理。
MinIO 是当前最流行的开源实现,服务使用也很便捷。国人写的Rust版本rustfs,也可以作为备选之一。
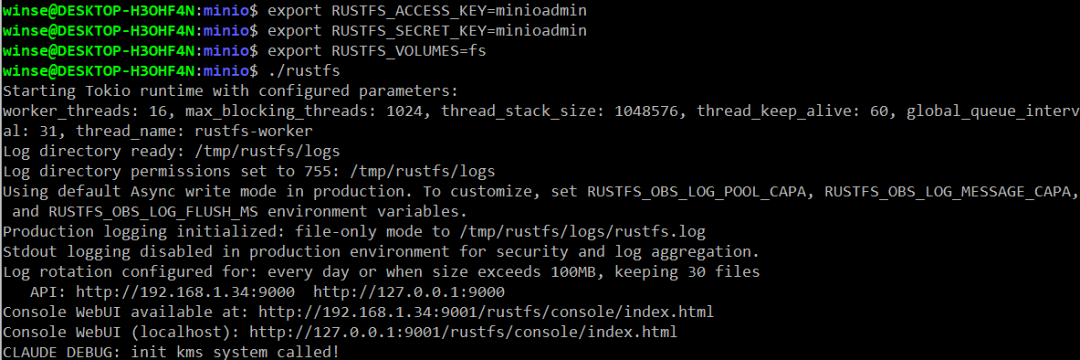
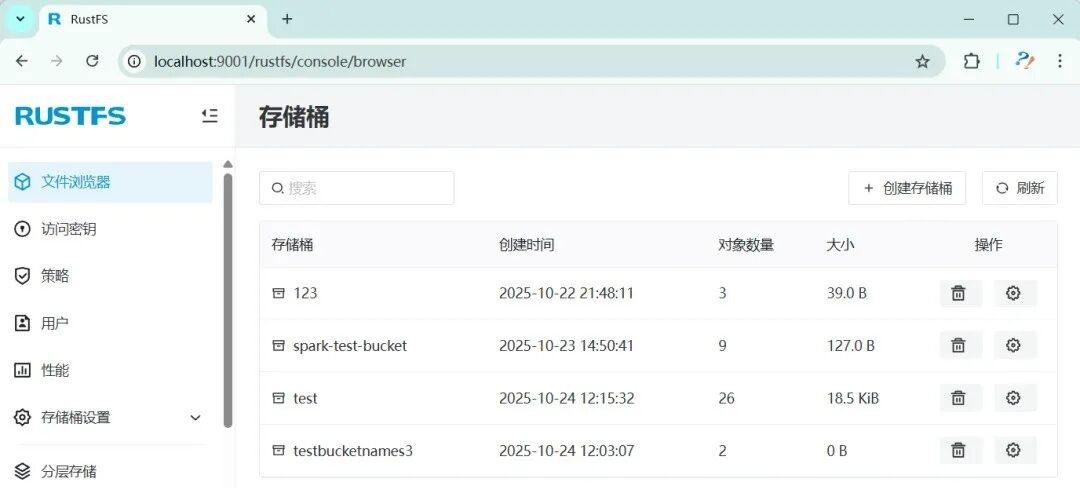
Spark 计算框架默认通过 Hadoop FileSystem 接口去访问存储,访问 S3 对象存储的 s3a 协议就是它的一个实现。Hadoop的文件系统FileSystem还是很厉害。相比Java NIO FileSystem,Hadoop 的 FileSystem 是为分布式的文件系统设计的,无需关注底层存储实现细节差异,提供容错和安全机制,并可统一访问HDFS、S3、OSS 等不同存储。
运行Spark
下载 spark-3.5.7-bin-hadoop3 版本(最终都是需要 hadoop 的依赖,直接下载附带 hadoop 的版本更直接一点)。如果是在 Windows 上运行,需要本地 Hadoop DLL 的支持,编译不是我们这关注的重点,文章最后附录部分有详细的说明。
配置 conf/spark-env.cmd,设置 HADOOP_HOME 和 PATH。然后,运行 spark-shell.cmd 脚本,即可启动交互式环境。
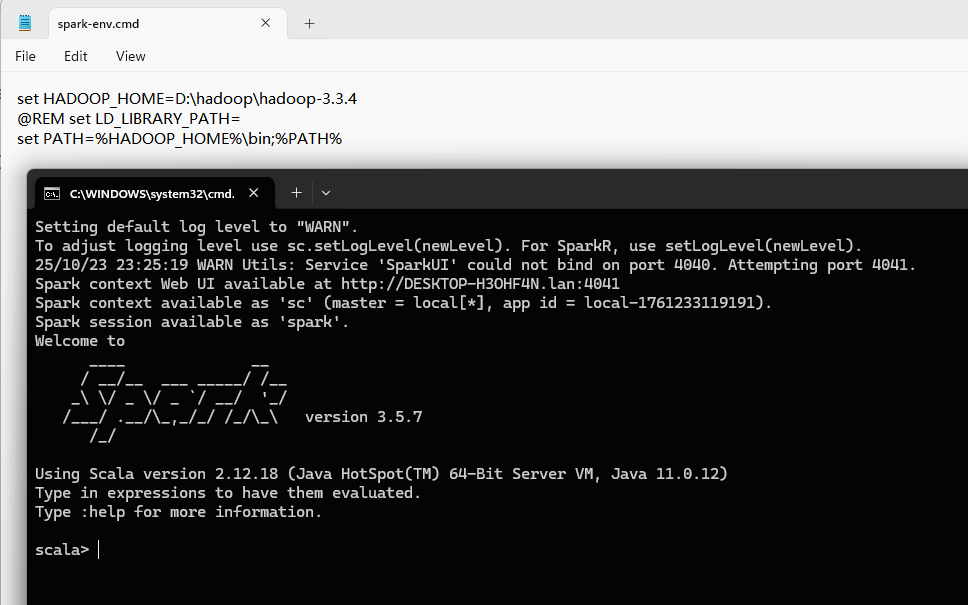
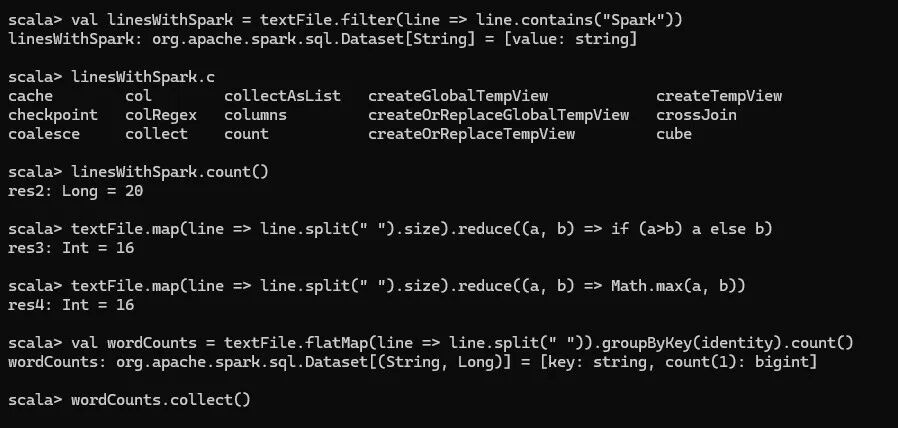
写个hello(spark-shell):

使用 spark-sql 命令执行SQL语句:
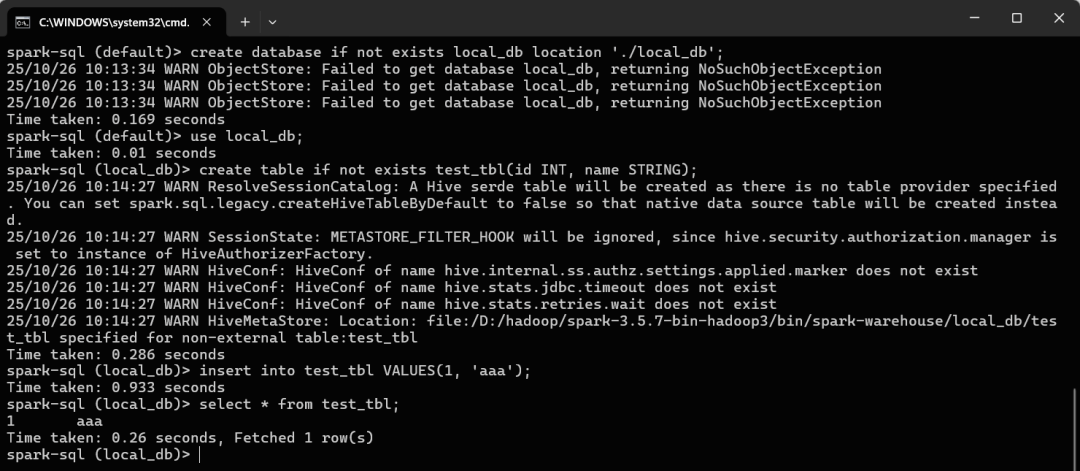
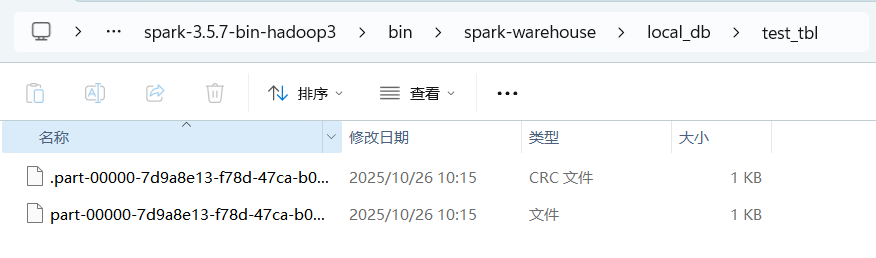
Spark 默认以 Hive 表格式保存数据,执行写入后可在文件系统中看到数据文件的效果:
数据追加:连接 S3 对象存储
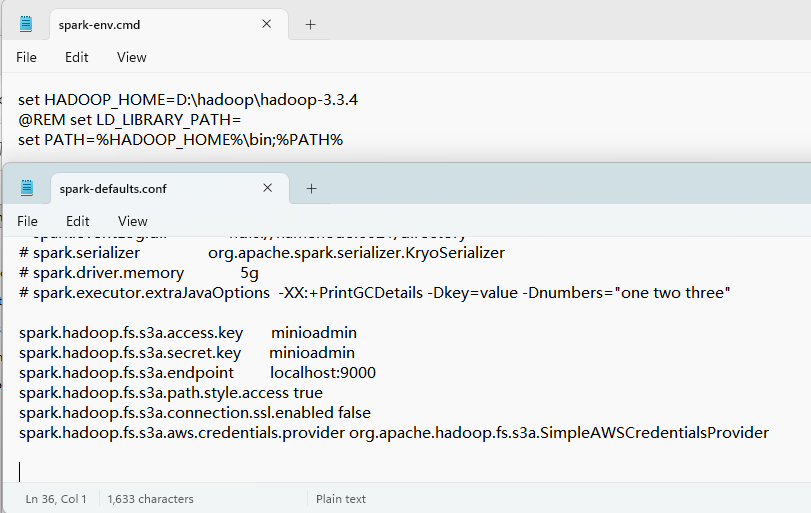
使用s3需要配置访问端点、用户和密码。最方便的方式是直接写到 conf/spark-defaults.conf 文件。
当然,启动时还需要添加 aws 的 jar 依赖包。首先,创建准备好 S3 的 bucket,创建一个 test 的存储桶,然后,使用下面的命令启动,下面操作的 建表以及插入数据 会放置到这个桶里面。
spark-sql --jars ..\..\aws-java-sdk-bundle-1.12.712.jar,..\..\hadoop-aws-3.3.4.jar
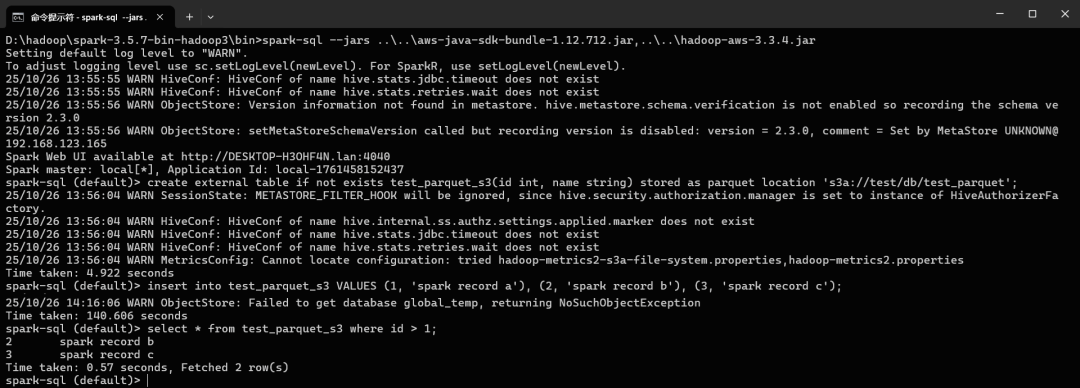
对象存储的写入记录后,结果看起来就像本地文件系统上一样。在对象存储的桶中生成了表的目录和数据文件,文件的记录列表如下:
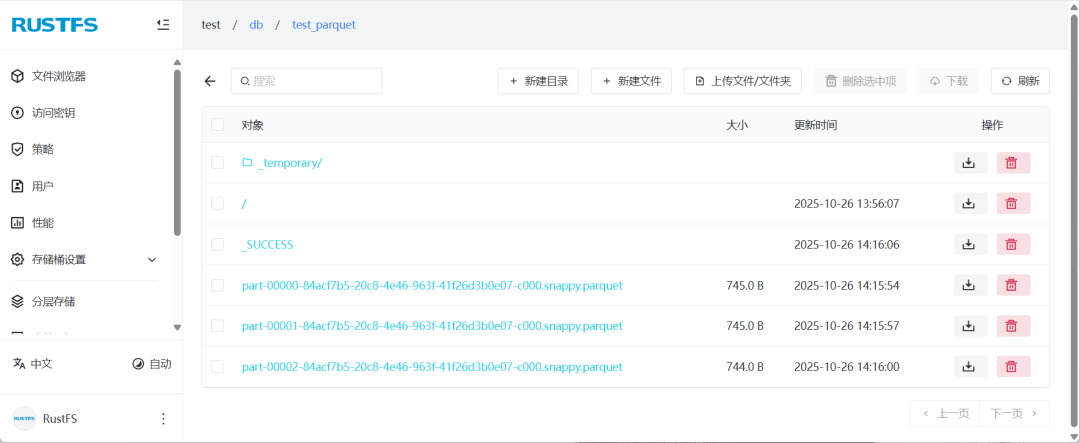
数据更新:iceberg 表管理
传统的Hive表格是不支持删除或修改操作:

如果要支持更新、删除、表结构的变更等操作,需要一种新的表管理模式:iceberg。iceberg 原理通过重新设计元数据来管理数据库的实际数据文件,通过快照的方式追踪表的版本,在对象存储上实现类数据库的操作DML、历史版本以及表模式(DDL)的修改。
参考文档:https://iceberg.apache.org/docs/nightly/spark-getting-started/#creating\-a-table。
首先,在 spark-defaults.conf 中配置iceberg:
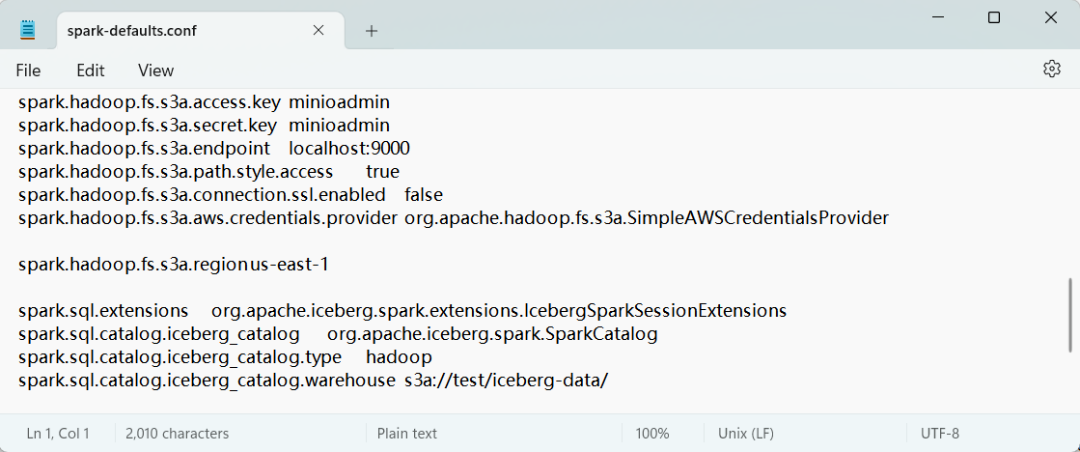
然后,运行的命令行中增加 iceberg 的 jar 依赖:
spark-sql --jars ..\..\iceberg-spark-runtime-3.5_2.12-1.10.0.jar,..\..\bundle-2.36.1.jar,..\..\aws-java-sdk-bundle-1.12.712.jar,..\..\hadoop-aws-3.3.4.jar
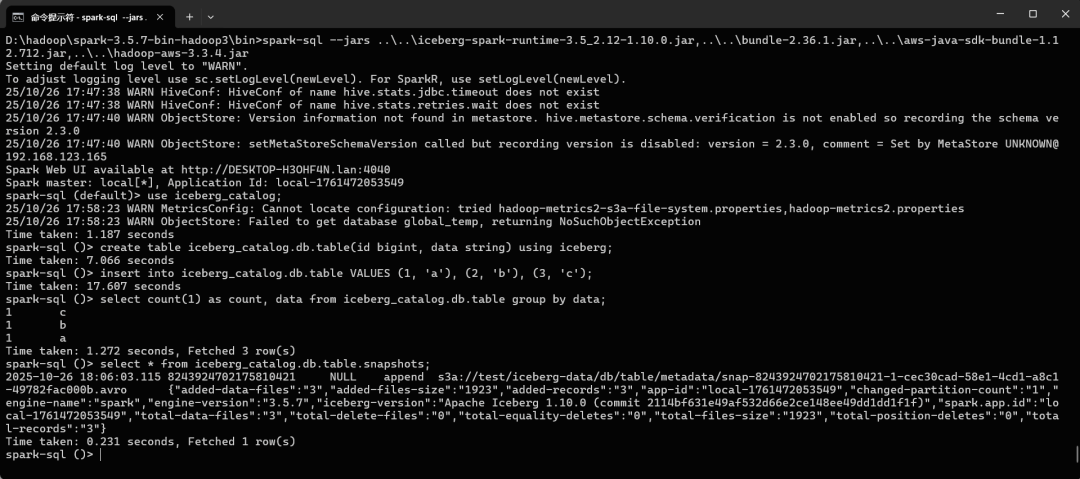
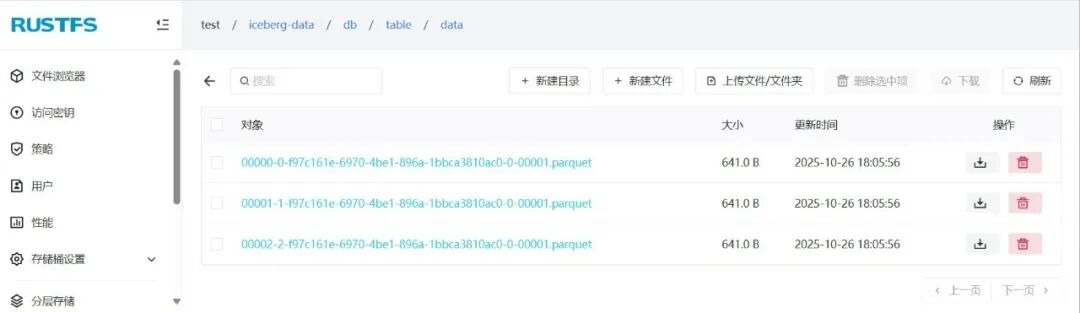
iceberg表的数据放在data目录下:
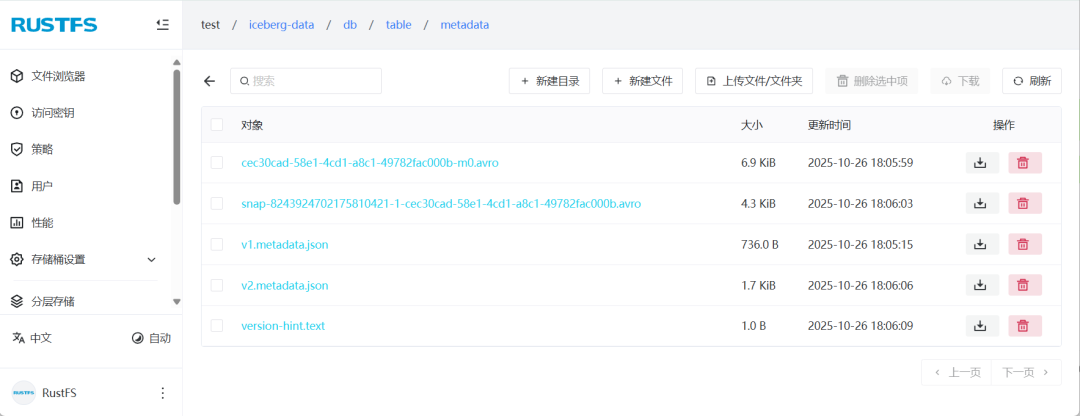
iceberg表的元数据放在metadata目录下:
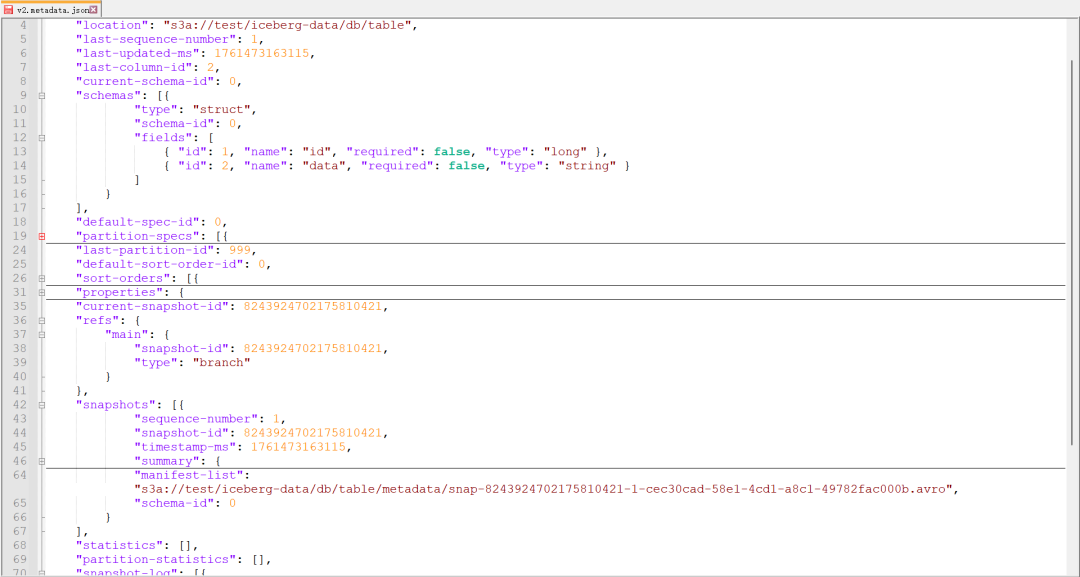
每个版本元数据记录了表的字段,以及它对应快照信息:
快照snapshot元数据的内容:
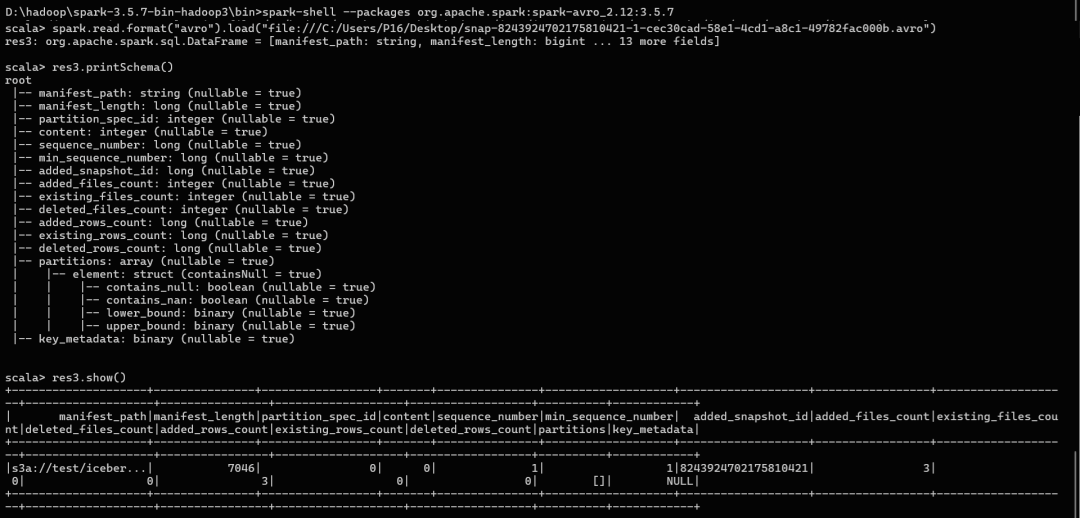
快照清单文件manifest内容:
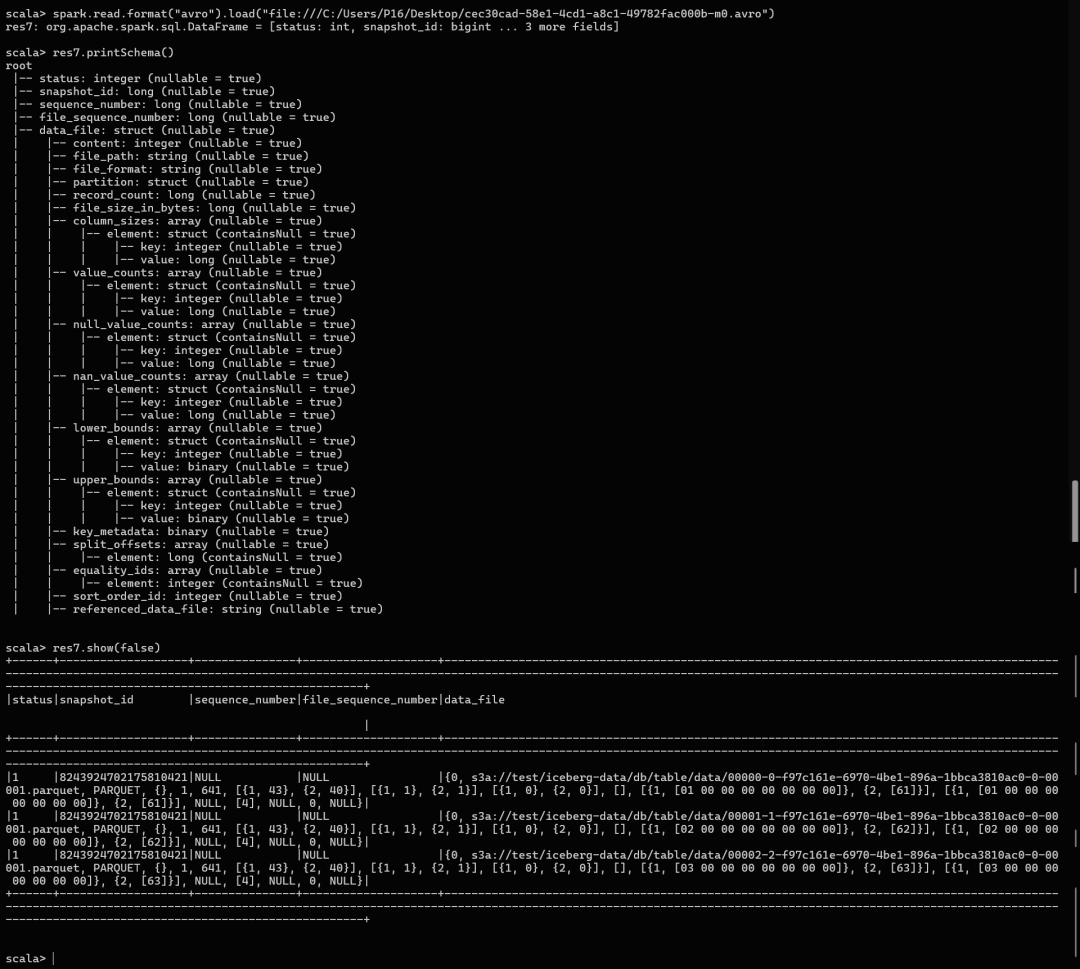
数据更新-法2:Delta Lake 表管理
Delta Lake也是实现数据修改的一个工具,主要与 Spark 集成,读写策略方面,Delta Lake在写入时合并(Merge-on-Write),写入时重写整个数据文件,这样后续读取速度更快。而 iceberg 是读取时合并(Merge-on-Read),即写入时仅追加或记录删除信息,读取的时刻再合并数据文件和删除文件,也就是说写入更快,读取稍慢一点。
入门文档:https://docs.delta.io/quick-start/
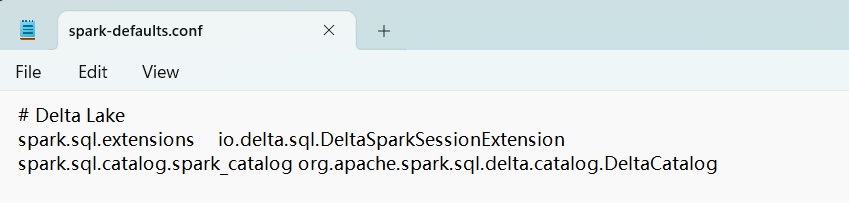
使用文件格式加路径的方式,需要指定绝对路径(使用相对路径会导致报错)。
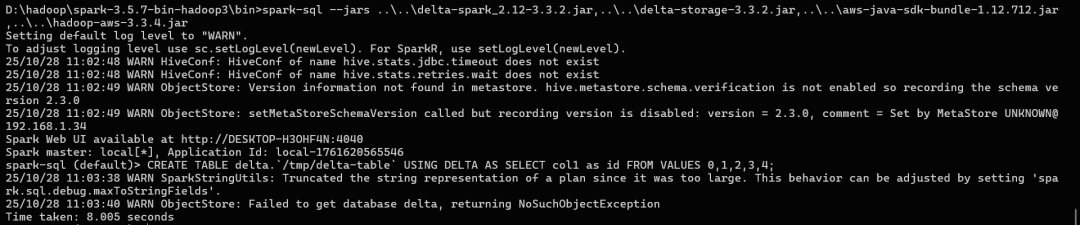
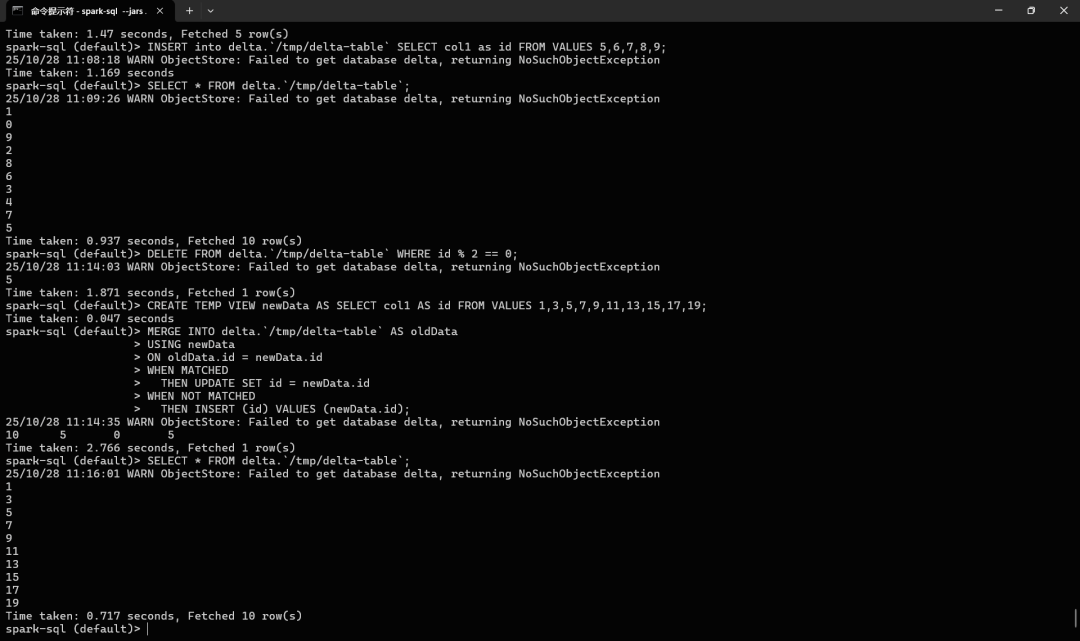
再进行一些操作:
数据目录下包括数据文件和日志:
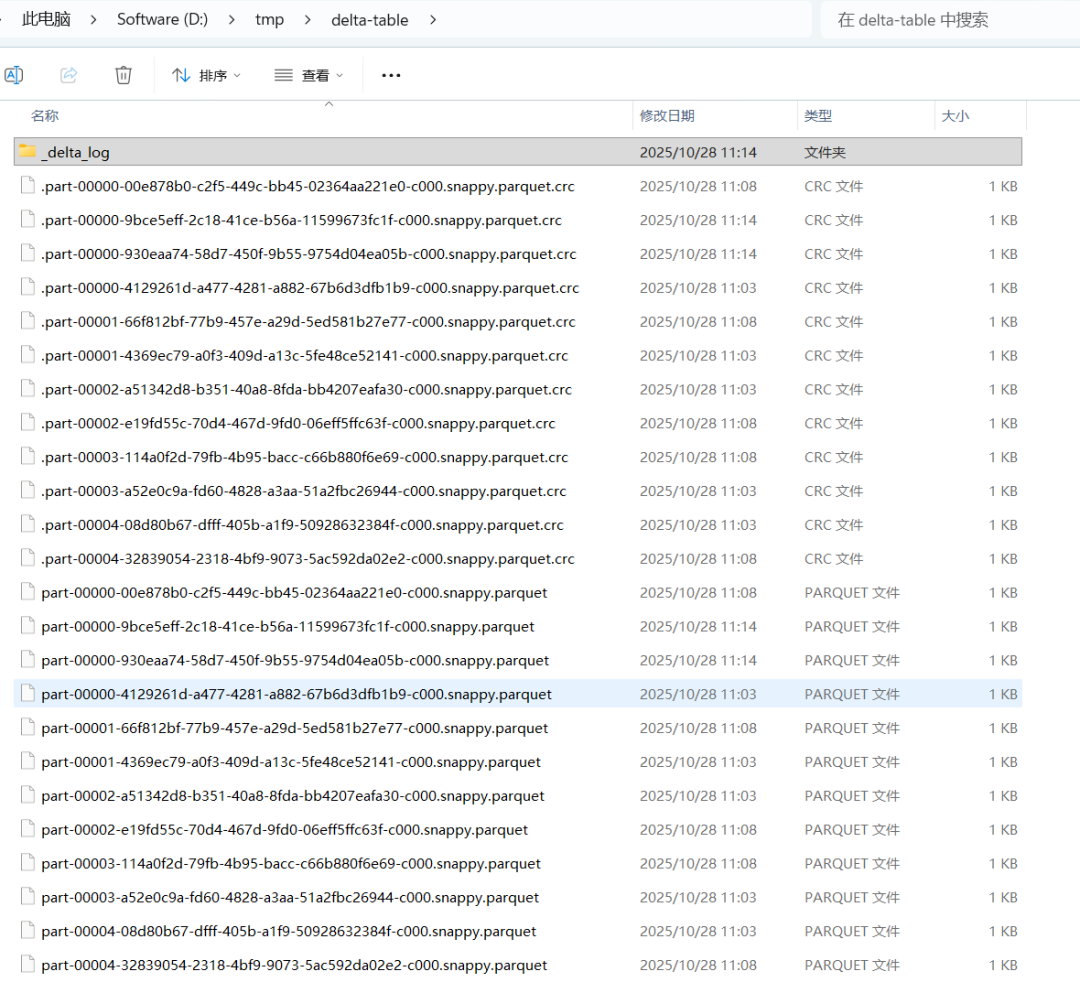
日志目录(_delta_log)保存了每次操作的事务json和当前版本元数据文件crc(Version Checksum file):
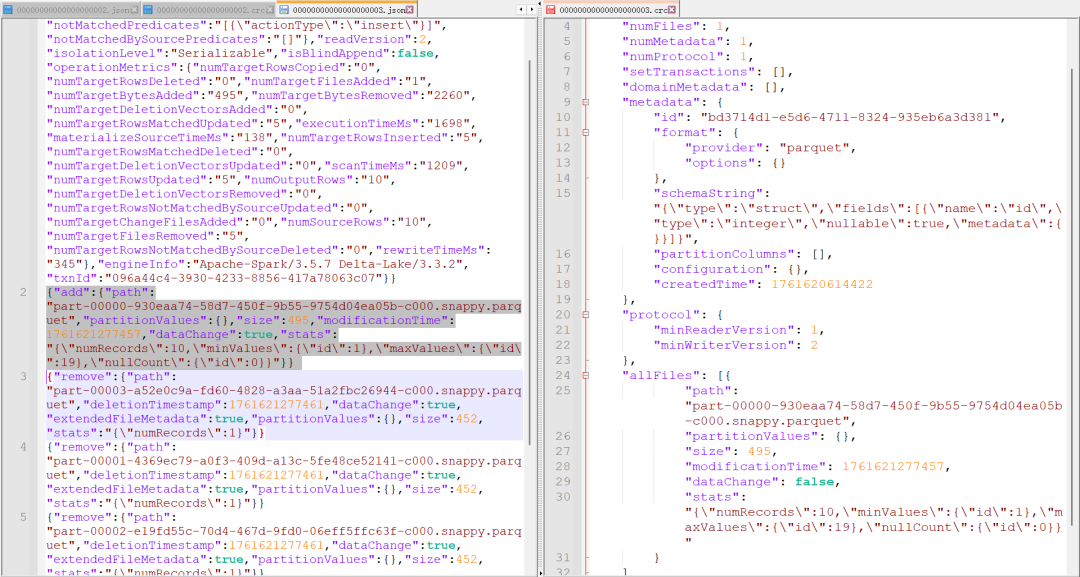
可以看到 Delta Lake 会在每次写入记录操作日志,同时合并汇聚生成了最终的数据文件。
可以通过指定版本查看历史数据 情况:

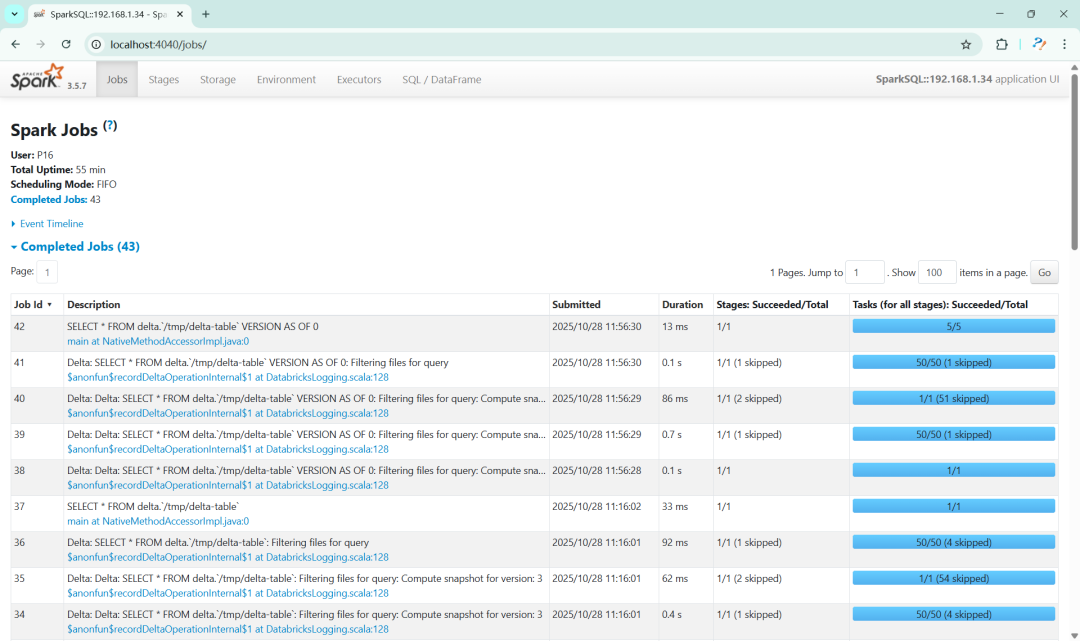
最后,看看执行的 Spark 操作的任务列表:
小结
这里我们探索了 Spark SQL 在对象存储上的应用实践,在对象存储上进行表数据的增删改查,还有历史版本数据回溯等。
1、对象存储可以理解为把文件系统扩展为了一种服务,它不仅仅是存文件的地方,而且是可扩展带权限的数据存储方法。
2、在实际使用中,Spark 使用 FileSystem接口 来统一访问各种存储系统,屏蔽了底层的实现细节差异,不管什么存储都可以统一的进行读写操作。
3、在存储系统的基础之上,叠加 Iceberg、Delta Lake表管理工具,能为数据湖提供更高层的能力:方便的实现数据的更新和删除,以及实现多版本快照,不同版本数据的切换,实现数据时光机的功能。
附:Windows编译Hadoop
下载spark-3.5.7-bin-hadoop3对应版本hadoop-3.3.4,先查看BUILDING.txt的Building on Windows部分。
安装配置好环境依赖:GIT,MAVEN3.9.11, JDK11,VS2022。
在程序菜单打开VS2022的命令行:x64 Native Tools Command Prompt for VS 2022。编译整个hadoop是一个巨大的挑战,因为我们只需要本地文件,编译hadoop-common即可。
D:\hadoop\hadoop-3.3.4-src\hadoop-common-project\hadoop-common>mvn clean package -Pdist,native-win -DskipTests -DskipDocs -Dmaven.javadoc.skip=true -Dtar -Dshell-executable=E:\local\PortableGit\bin\bash.exe

构建完成后,在target目录下生成的tar.gz包。
解压后,将文件放到我们的 HADOOP_HOME/bin 目录下即可。
Related
Related posts
-
杀鸡焉用牛刀:DuckDB 正取代部分 Spark 场景
2026-02-16
-
[读读书]Apache Spark源码剖析-Shell
2016-05-08
-
【linux 101 hacks】读后感
2015-09-13
-
cygwin兼容配置
2013-11-24