Article
杀鸡焉用牛刀:DuckDB 正取代部分 Spark 场景

在数据处理领域,Apache Spark 几乎成了“标准答案”。
日志分析?Spark
离线计算?Spark
数据清洗?Spark
OLAP?还是 Spark
仿佛只要谈“数据处理”,不用 Spark 就显得不够专业。
但很多时候,我们其实忽略了一个关键的问题:
你的业务规模,真的需要用到 Spark 吗?
在大量的 几百 MB ~ 几 GB 级的数据场景 下,Spark 往往就是典型的“杀鸡用牛刀”——复杂、沉重、而且性价比并不高。过去没得选,只能硬上;但现在有了 DuckDB 这样的 单机分析型数据库,在这些小场景中,它通常 更快、更轻,也更合适。
# 一、Spark 很强,但它的设计初衷就不是为“中小业务”
Spark 是为解决 分布式大数据 而生的,这也决定它的强大是建立在天然复杂系统之上:
•集群管理(YARN / K8s)•任务调度与DAG构建•Shuffle 网络通信•JVM 冷启动•Executor 资源分配等等
这些能力,在 TB 级甚至 PB 级数据 规模下是优势; 但在 几百 MB ~ 几 GB 规模 下,反而变成了负担:
80% 的时间在准备干活,20% 的时间在真正计算。
很多中小团队,真实的数据规模往往只是:
•每天新增:几百 MB•全量数据:1~5 GB•行数:百万 ~ 千万级
却依然要维护:
•Spark 集群•Yarn 队列•K8s 资源池•监控告警系统
工程复杂度,远远大于业务复杂度。
# 二、DuckDB:为“单机分析”而生的现代 OLAP 引擎
如果说 SQLite 是 事务型数据库的极致简化, 那 DuckDB 就是 分析型数据库的极致简化(简便易用和进程内嵌入)。
你可以把它理解成:
一个能跑在本地的 Spark SQL 执行引擎。
它具备现代 OLAP 引擎的核心特性:
•单文件、零依赖•无服务端、嵌入式•列式存储 + 向量化执行•可直接查询 CSV / Parquet / Avro / JSON / Arrow•支持 Java / Node.js / Go / Python 等多种语言
一句话总结:
极低复杂度,极高性能。
# 三、为什么几 GB 级数据,DuckDB 往往比 Spark 更快?
# 1、没有分布式系统开销
Spark 一次任务至少要经历:
•构建 DAG•申请资源•启动 Executor•建立网络连接
而 DuckDB:
直接进程内执行,没有任何调度成本。
在 几 GB 数据小规模 下, Spark 的 系统开销 远远大于 计算本身, 而 DuckDB 的 几乎全部时间都花在计算上。
# 2、列存 + 向量化 + SIMD,CPU 利用率极高
DuckDB 采用了现代 OLAP 执行引擎架构:
•列式存储•向量化执行•批量算子流水线•SIMD(Single Instruction, Multiple Data,单指令多数据流) 指令加速
在:
•聚合•Join•过滤•排序
这些场景下,对 几百万 ~ 千万级数据,依然可以做到 亚秒级 ~ 秒级响应。
# 3、本地 I/O + 内存映射,避免网络瓶颈
Spark 的瓶颈常常来自:
网络 + Shuffle
DuckDB 的数据通路是:
本地 SSD → 内存映射 → 向量计算(columnar-vectorized query execution engine)
在 几 GB 级数据 下,本地 I/O 往往远快于任何分布式通信。
# 四、迁移成本极低:从 Spark SQL 到 DuckDB SQL,几乎零成本
这是整个迁移过程中 最惊喜的一点。
# 1、SQL 兼容度极高
绝大多数的 Spark SQL:
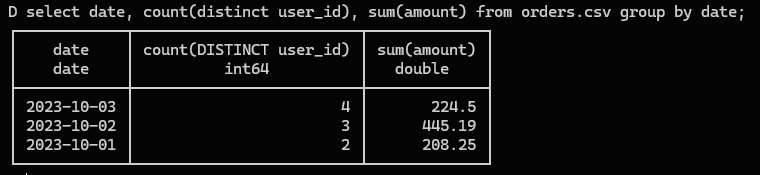
select
可以 直接拷贝到 DuckDB 执行,几乎不需要改。
# 2、不再需要建表 + 导入
Spark:
chcp 65001
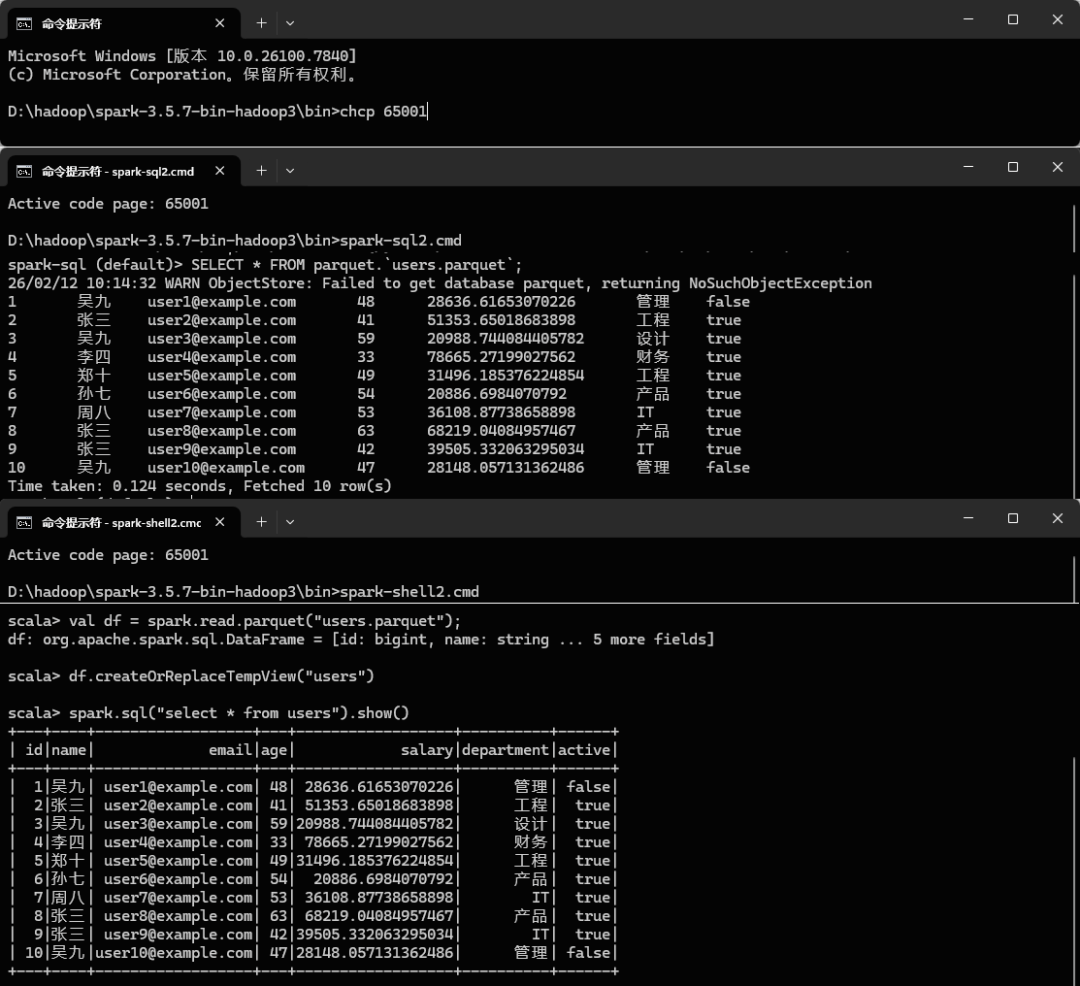
DuckDB:
select * from 'users.parquet';
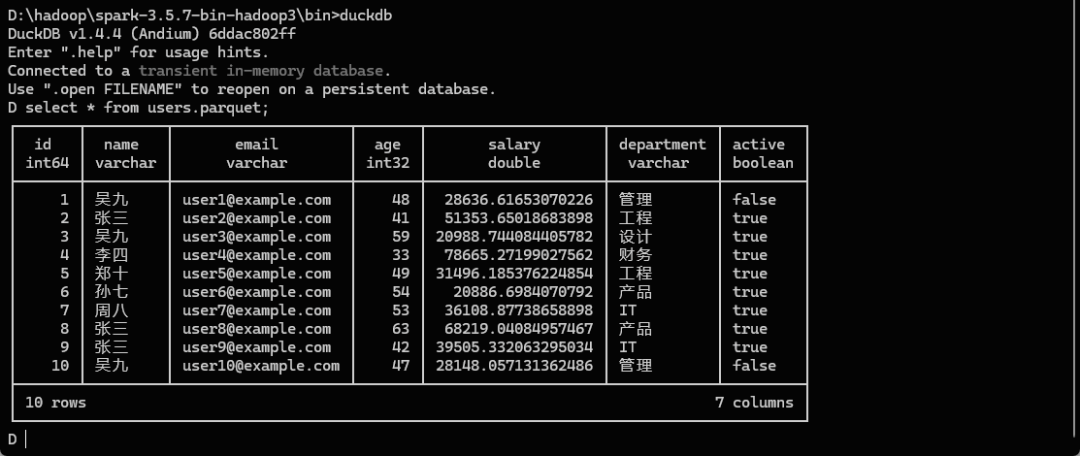
文件即表,极大简化数据流。
# 3、Spark SQL 的 UDF,如何迁移到 DuckDB?
先说结论:
90% 的 Spark SQL UDF,都不该“直接翻译”,而应该被“消灭”。
因为大部分 UDF 的存在,本质是:
Spark SQL 表达力不够 + 旧习惯遗留 + 业务逻辑混入 SQL。
而 DuckDB 的 SQL 表达力,比 Spark SQL 强很多。
# 第一层:用 DuckDB SQL 直接替换 Spark UDF(优先级最高)
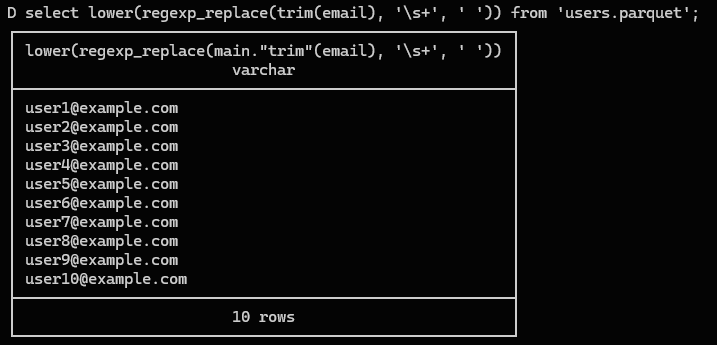
示例 1:字符串处理类 UDF
DuckDB 里可以直接:
lower(regexp_replace(trim(x), '\s+', ' '))
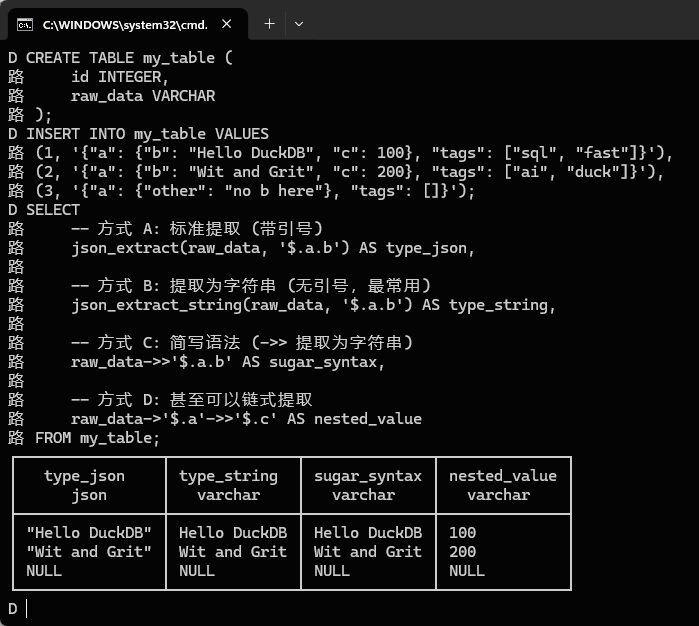
示例 2:JSON 解析
DuckDB:
json_extract(str, '$.a.b')
或:
json_extract_string(str, '$.a.b')
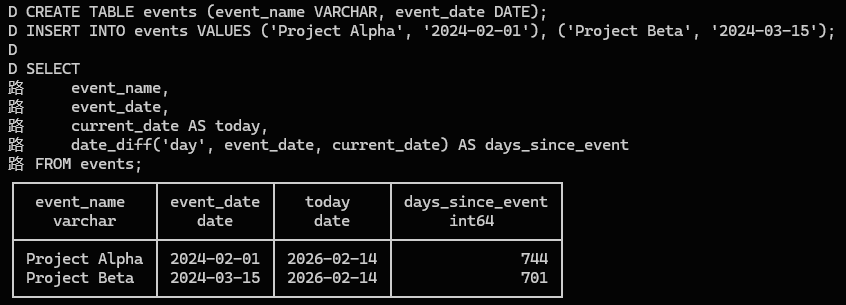
示例 3:时间计算
DuckDB:
date_diff('day', t1, t2)
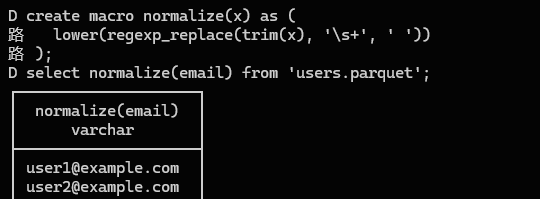
# 第二层:DuckDB 宏(Macro)替代简单 UDF
如果逻辑较复杂,但本质仍是 SQL 拼装,可以用 Macro。
# 示例:逻辑封装
create macro normalize(x) as (
使用:
select normalize(name) from users;
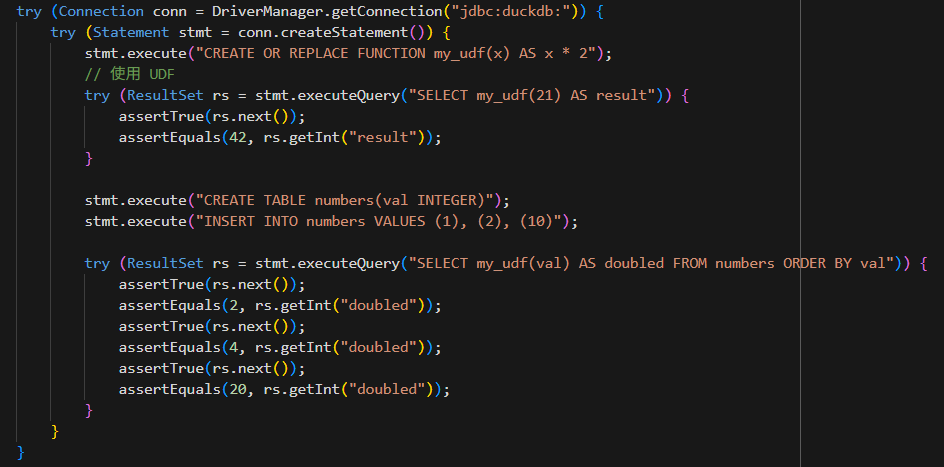
# 第三层:Java / Node.js 注册 UDF(真正需要时)
只有当逻辑:
•高度定制•复杂计算•特殊算法•第三方库依赖
才建议使用 DuckDB 原生的 UDF 接口。
1)Java 注册 UDF 示例
stmt.execute("""
或使用原生 API 绑定 Java 函数。
2)Node.js 注册 UDF 示例
db.register('my_udf', x => x * 2);
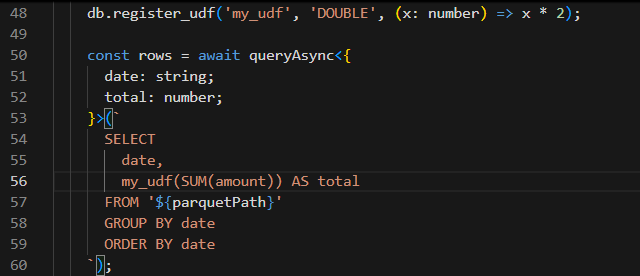
UDF 不是迁移问题,而是架构清理的最佳契机。 借机干掉 90% 历史包袱,让系统变简单。
# 五、DuckDB 实战体验
1)Java 直接查询 Parquet 文件
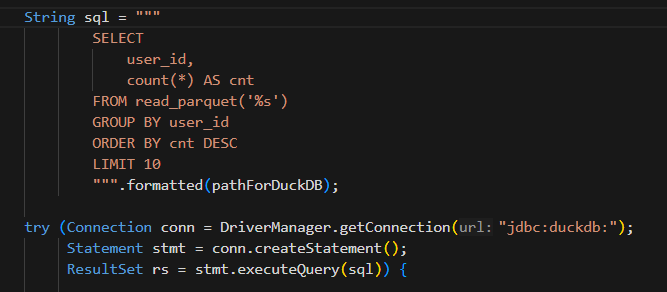
•无需建表•无需导入•无需部署•直接读取文件
这就是 DuckDB 最大的工程优势:极简。
2)Node.js 的内嵌 OLAP 引擎
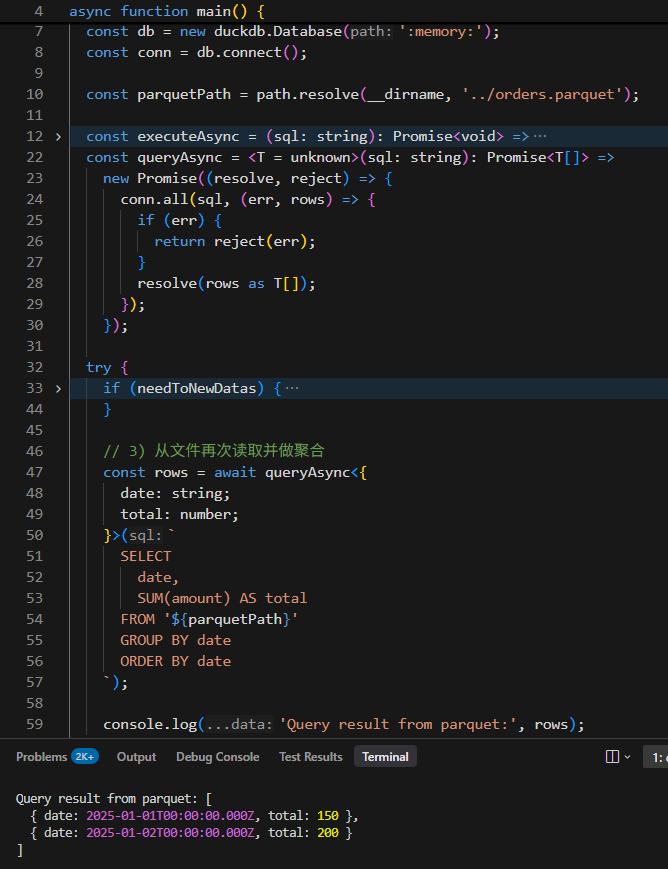
你可以把 DuckDB 当成:
Node.js 进程内的分析型数据库。
# 六、什么时候该用 DuckDB?什么时候该用 Spark?
# DuckDB 适合:
•数据量:几百 MB ~ 几 GB•单机可承载•报表 / BI 分析、即席查询•中小团队•本地调试 / 数据探索
# Spark 适合:
•数据量:几十 GB 起步•需要横向扩展•超大规模 ETL•分布式 Join
# 七、总结:Spark 是王者,但 DuckDB 是更聪明的选择
Spark 没有错, 错的是:在不该用它的地方,用了它。
在 几 GB 级中小业务 中:
•DuckDB 更快•DuckDB 更轻•DuckDB 更简单•DuckDB 更工程友好
如果你现在的 Spark 集群:
•每天只跑几 GB 数据•却要维护一整套分布式系统
那你真的可以认真考虑一下 DuckDB。
你可能会发现:
原来数据分析,还可以这么轻。
Related
Related posts
-
基于对象存储的 Spark 数据读写实战:从末尾追加到任意更新
2025-10-28
-
RPM打包
2016-04-04
-
Windows下部署/配置/调试hadoop2
2014-04-21
-
n8n 终于还是部署到 Docker 了,经验就是要反反复复地去验证:要想少走弯路,就按官方推荐的最佳实践
2025-12-29