alluxio就是原来的tachyon。老大是华人,文档自然就有福利,把en改成cn就可以查看中文版的文档了。
http://alluxio.org/documentation/master/cn/Architecture.html
注意:docker暂时不能部署alluxio: mount: permission denied
首先介绍alluxio的编译,然后进行本地和集群两种方式的部署,同时介绍HDFS底层存储系统配置和一些常用命令行的使用,最后通过代码和spark读写Alluxio数据,以及升级到V1.1查看系统的Metrics指标来了解存储系统使用情况。
回头看:Alluxio启动时会挂载一个Mem内存盘,其实可以把内存盘路径指定到 /dev/shm 。其他操作就很简单了,也不需要root权限。
编译
1
2
3
4
5
6
| # 下载官网打包的bin.tar.gz。不推荐去github下v1.0.1,编译时findbug检查server有两个bug
http://alluxio.org/downloads/files/1.0.1/alluxio-1.0.1-bin.tar.gz
[hadoop@cu2 ~]$ cd ~/sources/alluxio-1.0.1/
[hadoop@cu2 alluxio-1.0.1]$ export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
[hadoop@cu2 alluxio-1.0.1]$ mvn clean package assembly:single -Phadoop-2.6 -Dhadoop.version=2.6.3 -Pyarn,spark -Dmaven.test.skip=true -Dmaven.javadoc.skip=true
|
编译成功后会生成 assembly/target/alluxio-1.0.1.tar.gz 文件。部署的时刻直接用编译好的 tar.gz 就行了,内容比较简洁和清晰。
还有一个问题,不要加Profile compileJsp ,编译没问题但是部署后访问网页抛 ClassNotFound 异常。
windows alluxio-1.1-snapshot 编译需要注意下。打包 assembly 的时刻换行符没有格式化,还有 mvn 编译时需要用到 test 项目(改成skipTests)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| $ git diff assembly/src/main/assembly/alluxio-dist.xml
diff --git a/assembly/src/main/assembly/alluxio-dist.xml b/assembly/src/main/assembly/alluxio-dist.xml
index 14ecd19..06ddd51 100644
--- a/assembly/src/main/assembly/alluxio-dist.xml
+++ b/assembly/src/main/assembly/alluxio-dist.xml
@@ -11,6 +11,7 @@
<outputDirectory>/bin</outputDirectory>
<fileMode>0755</fileMode>
<directoryMode>0755</directoryMode>
+ <lineEnding>unix</lineEnding>
</fileSet>
<fileSet>
<directory>${basedir}/../conf</directory>
@@ -19,6 +20,7 @@
<fileSet>
<directory>${basedir}/../libexec</directory>
<outputDirectory>/libexec</outputDirectory>
+ <lineEnding>unix</lineEnding>
</fileSet>
<fileSet>
<directory>${basedir}/..</directory>
E:\git\alluxio>set MAVEN_OPTS="-Xmx2g"
E:\git\alluxio>mvn clean package assembly:single -Phadoop-2.6 -Dhadoop.version=2.6.3 -Pyarn,spark -DskipTests -Dmaven.javadoc.skip=true
|
Local部署配置
http://alluxio.org/documentation/master/cn/Running-Alluxio-Locally.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| [hadoop@hadoop-master2 ~]$ tar zxf alluxio-1.0.1.tar.gz
[hadoop@hadoop-master2 ~]$ cd alluxio-1.0.1/conf/
[hadoop@hadoop-master2 conf]$ cp alluxio-env.sh.template alluxio-env.sh
[hadoop@hadoop-master2 conf]$ vi alluxio-env.sh
...
JAVA_HOME=/opt/jdk1.7.0_60
ALLUXIO_UNDERFS_ADDRESS=/home/hadoop/tmp
[hadoop@hadoop-master2 conf]$ cd ..
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio format
Connecting to localhost as hadoop...
Formatting Alluxio Worker @ hadoop-master2
Connection to localhost closed.
Formatting Alluxio Master @ localhost
[hadoop@hadoop-master2 alluxio-1.0.1]$
# 把hadoop用户加入sudo
[root@hadoop-master2 ~]# visudo
...
hadoop ALL=(ALL) NOPASSWD: ALL
# 机器原来部署过hadoop,localhost已经可以无密钥登录。
# 启动
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio-start.sh local
Killed 0 processes on hadoop-master2
Killed 0 processes on hadoop-master2
Connecting to localhost as hadoop...
Killed 0 processes on hadoop-master2
Connection to localhost closed.
Formatting RamFS: /mnt/ramdisk (1gb)
Starting master @ localhost. Logging to /home/hadoop/alluxio-1.0.1/logs
Starting worker @ hadoop-master2. Logging to /home/hadoop/alluxio-1.0.1/logs
[hadoop@hadoop-master2 alluxio-1.0.1]$
[hadoop@hadoop-master2 alluxio-1.0.1]$ jps
3780 AlluxioMaster
3845 Jps
3807 AlluxioWorker
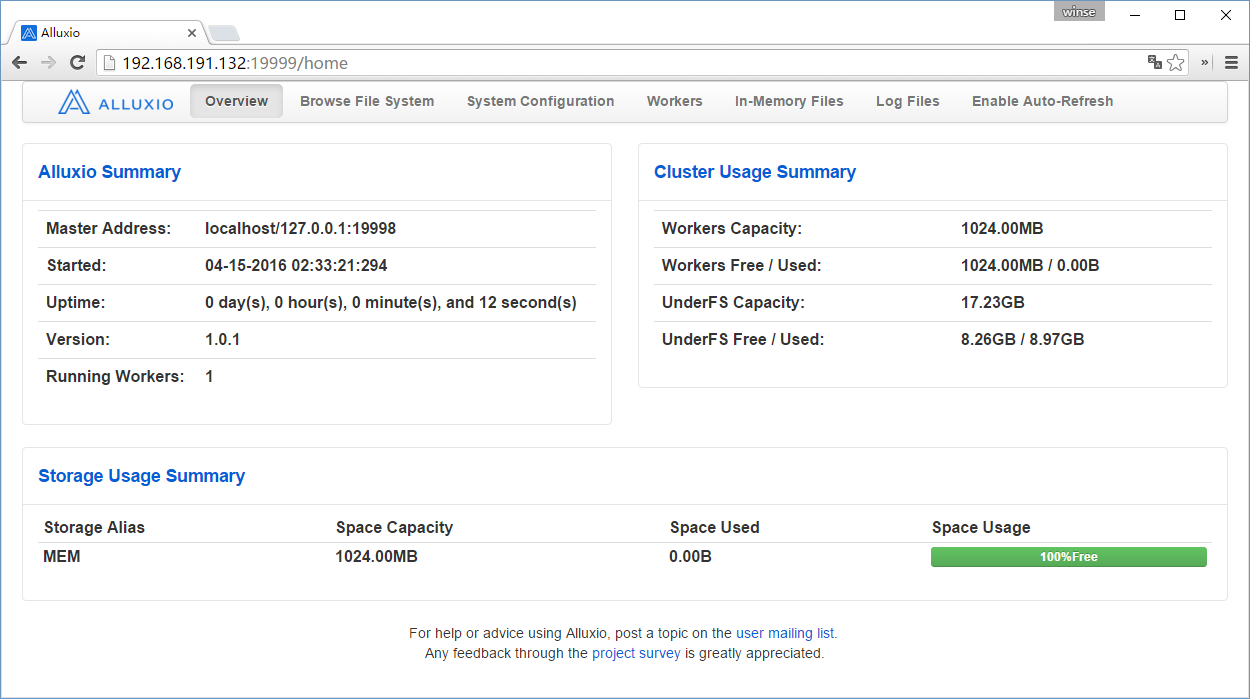
# localhost:19999 通过web页查看集群状态
# 关闭
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio-stop.sh all
Killed 1 processes on hadoop-master2
Killed 1 processes on hadoop-master2
Connecting to localhost as hadoop...
Killed 0 processes on hadoop-master2
Connection to localhost closed.
|
这里完全安装官网的步骤来弄,正式环境的时刻可以用 root 来 mount 内存盘。下面集群部署再介绍。
集群部署
步骤和Local类似。把程序部署到workers节点,所有workers节点都 mount 内存盘,然后调用 start.sh 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| # master 和 workers 的无密钥登录。部署过apache-hadoop的肯定都已经弄过了
# 修改配置
[hadoop@hadoop-master2 alluxio-1.0.1]$ vi conf/workers
bigdata1
[hadoop@hadoop-master2 alluxio-1.0.1]$ vi conf/alluxio-env.sh
ALLUXIO_MASTER_ADDRESS=hadoop-master2
# 部署程序
# bin/alluxio copyDir <dirname> 慎用,会把logs目录也同步过去的,
# 当然可以修改alluxio的脚本,反正要知道脚本的作用
[hadoop@hadoop-master2 ~]$ rsync -az alluxio-1.0.1 bigdata1:~/ --exclude=logs --exclude=/*/src --exclude=underfs --exclude=journal
# 使用root用户挂载(workers)节点的内存盘
# 当然还有最简单的方式,直接把 ALLUXIO_RAM_FOLDER=/dev/shm 指定到系统的tmpfs,系统的tmpfs其实也主要用的是内存。
# 变量 ALLUXIO_WORKER_MEMORY_SIZE=512MB 修改内存盘的大小,小于 /dev/shm 的空间大小。
[root@hadoop-master2 ~]# cd /home/hadoop/alluxio-1.0.1
[root@hadoop-master2 alluxio-1.0.1]# bin/alluxio-mount.sh Mount workers
Connecting to bigdata1 as root...
Warning: Permanently added 'bigdata1,192.168.191.133' (RSA) to the list of known hosts.
Formatting RamFS: /mnt/ramdisk (1gb)
Connection to bigdata1 closed.
# worker节点确认
[hadoop@bigdata1 ~]$ mount
/dev/mapper/VolGroup-lv_root on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0")
/dev/sda1 on /boot type ext4 (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
ramfs on /mnt/ramdisk type ramfs (rw,size=1gb)
# 格式化:主要是清理/创建JOURNAL目录,清理workers本地缓存(tiered-storage)目录数据
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio format
Connecting to bigdata1 as hadoop...
Formatting Alluxio Worker @ bigdata1
Connection to bigdata1 closed.
Formatting Alluxio Master @ localhost
# 启动
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio-start.sh all NoMount
Killed 1 processes on hadoop-master2
Killed 1 processes on hadoop-master2
Connecting to bigdata1 as hadoop...
Killed 0 processes on bigdata1
Connection to bigdata1 closed.
Starting master @ localhost. Logging to /home/hadoop/alluxio-1.0.1/logs
Connecting to bigdata1 as hadoop...
Starting worker @ bigdata1. Logging to /home/hadoop/alluxio-1.0.1/logs
Connection to bigdata1 closed.
[hadoop@hadoop-master2 alluxio-1.0.1]$ jps
5164 AlluxioMaster
5219 Jps
[hadoop@bigdata1 alluxio-1.0.1]$ jps
1849 Jps
1829 AlluxioWorker
|
通过网页查看,如果 Running Workers 为 0 ,到workers节点 alluxio-1.0.1/logs 下面去看日志然后定位问题。防火墙没开放?还是其他配置不正确,如hosts等等。
命令行HelloWorld
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| [hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs copyFromLocal conf/alluxio-env.sh /
Copied conf/alluxio-env.sh to /
# worker节点查看内容(当前只有这一个文件啊,查看方便),block-id可以通过网页或者 fs fileInfo查看
[hadoop@bigdata1 alluxio-1.0.1]$ tail -1 /mnt/ramdisk/alluxioworker/117440512
export ALLUXIO_WORKER_JAVA_OPTS="${ALLUXIO_JAVA_OPTS}"
# 在master机器上调用 persist ,在worker节点没找到对应的数据。竟然直接存储在执行命令的节点了,囧!!!
# alluxio.client.file.FileSystemUtils#persistFile
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs persist /alluxio-env.sh
persisted file /alluxio-env.sh with size 5493
[hadoop@hadoop-master2 alluxio-1.0.1]$ ll /home/hadoop/tmp/
total 28
-rwxrwxrwx 1 hadoop hadoop 5493 Apr 15 03:33 alluxio-env.sh
[hadoop@bigdata1 alluxio-1.0.1]$ bin/alluxio fs persist /alluxio-env.sh
/alluxio-env.sh is already persisted
[hadoop@bigdata1 alluxio-1.0.1]$ ll /home/hadoop/tmp
总用量 0
|
在master调用 persist 后,再在worker节点调用 persist 竟然提示 already persisted 了。如果在分布式的情况下,本地磁盘 不适合 用于做 underfs !!官网也是说 单节点 本地文件系统。
Alluxio提供了通用接口以简化插入不同的底层存储系统。目前我们支持Amazon S3,OpenStack Swift,Apache HDFS,GlusterFS以及单节点本地文件系统
使用HDFS作为底层存储
http://alluxio.org/documentation/master/en/Configuring-Alluxio-with-HDFS.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| [hadoop@hadoop-master2 alluxio-1.0.1]$ vi conf/alluxio-env.sh
...
JAVA_HOME=/opt/jdk1.7.0_60
HADOOP_HOME=/home/hadoop/hadoop-2.6.3
# source $HADOOP_HOME/libexec/hadoop-config.sh
JAVA_LIBRARY_PATH="$HADOOP_HOME/lib/native"
ALLUXIO_JAVA_OPTS="$ALLUXIO_JAVA_OPTS -Djava.library.path=$JAVA_LIBRARY_PATH"
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$JAVA_LIBRARY_PATH
ALLUXIO_CLASSPATH=$HADOOP_HOME/etc/hadoop:$ALLUXIO_CLASSPATH
ALLUXIO_UNDERFS_ADDRESS=hdfs:///alluxio # 配置一个alluxio子路径比较好管理
ALLUXIO_MASTER_ADDRESS=hadoop-master2
# 清理/创建元数据目录和workers节点本地缓冲存储的数据
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio format
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio-start.sh master
# master启动正常后,启动workers节点
# 上面已经用root mount了内存盘了,没有的用root执行 bin/alluxio-mount.sh Mount workers
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio-start.sh workers NoMount
|
http://alluxio.org/documentation/master/en/Command-Line-Interface.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| [hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs copyFromLocal ~/hadoop-2.6.3/README.txt /
Copied /home/hadoop/hadoop-2.6.3/README.txt to /
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs ls /
1366.00B 04-15-2016 09:30:45:829 In Memory /README.txt
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs location /README.txt
/README.txt with file id 33554431 is on nodes:
bigdata1
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs persist /README.txt
/README.txt is already persisted
# 默认文件只写到 Cache ,可以修改配置来进行修改
# alluxio.client.WriteType
[hadoop@hadoop-master2 alluxio]$ export ALLUXIO_JAVA_OPTS="-Dalluxio.user.file.writetype.default=CACHE_THROUGH"
[hadoop@hadoop-master2 alluxio]$ bin/alluxio fs copyFromLocal ~/hadoop-2.6.3/README.txt /
Copied /home/hadoop/hadoop-2.6.3/README.txt to /
[hadoop@hadoop-master2 alluxio]$ bin/alluxio fs fileInfo /README.txt
FileInfo{fileId=452984831, name=README.txt, path=/README.txt, ufsPath=hdfs:///alluxio/README.txt, length=1366, blockSizeBytes=536870912, creationTimeMs=1460765370996, completed=true, folder=false, pinned=false, cacheable=true, persisted=true, blockIds=[436207616], inMemoryPercentage=100, lastModificationTimesMs=1460765372423, ttl=-1, userName=, groupName=, permission=0, persistenceState=PERSISTED, mountPoint=false}
Containing the following blocks:
BlockInfo{id=436207616, length=1366, locations=[BlockLocation{workerId=1, address=WorkerNetAddress{host=bigdata1, rpcPort=29998, dataPort=29999, webPort=30000}, tierAlias=MEM}]}
# Creates a 0 byte file. The file will be written to the under file system.
# For example, touch can be used to create a file signifying the compeletion of analysis on a directory.
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs touch /1234.txt
/1234.txt has been created
# 已经persist的文件,重命名后,hdfs上面的文件也立即改变了
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs mv /1234.txt /4321.txt
Renamed /1234.txt to /4321.txt
# 空文件没有分配实际的存储,只有元数据
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs location /4321.txt
/4321.txt with file id 67108863 is on nodes:
# free掉memory,然后删掉underfs目录下的文件
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs free /
/ was successfully freed from memory.
[hadoop@hadoop-master2 hadoop-2.6.3]$ bin/hdfs dfs -rmr /alluxio/*
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs ls /
1366.00B 04-15-2016 09:30:45:829 Not In Memory /README.txt
0.00B 04-15-2016 09:37:48:971 In Memory /4321.txt
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs tail /README.txt
File does not exist: /alluxio/README.txt
at org.apache.hadoop.hdfs.server.namenode.INodeFile.valueOf(INodeFile.java:66)
at org.apache.hadoop.hdfs.server.namenode.INodeFile.valueOf(INodeFile.java:56)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocationsUpdateTimes(FSNamesystem.java:1893)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocationsInt(FSNamesystem.java:1834)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocations(FSNamesystem.java:1814)
# 按照文件名把 README.txt 放到 underfs 目录下面
[hadoop@hadoop-master2 hadoop-2.6.3]$ bin/hdfs dfs -put *.txt /alluxio/
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs tail /README.txt
...
software:
Hadoop Core uses the SSL libraries from the Jetty project written
by mortbay.org.
# 数据载入内存
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs load /
/README.txt loaded
/ loaded
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs ls /
1366.00B 04-15-2016 09:30:45:829 In Memory /README.txt
0.00B 04-15-2016 09:37:48:971 In Memory /4321.txt
# 载入underfs的目录结构
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio loadufs / hdfs:///alluxio
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs ls /
1366.00B 04-15-2016 09:30:45:829 In Memory /README.txt
0.00B 04-15-2016 09:37:48:971 In Memory /4321.txt
15.07KB 04-15-2016 10:12:33:176 Not In Memory /LICENSE.txt
101.00B 04-15-2016 10:12:33:190 Not In Memory /NOTICE.txt
# 通过 fileInfo 查看信息; fileId, ufsPath, 和分区blocks信息
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs fileInfo /README.txt
# 通配符要这么写,也是醉鸟
[hadoop@hadoop-master2 alluxio-1.1.0-SNAPSHOT]$ bin/alluxio fs rm /\\*
/4321.txt has been removed
/LICENSE.txt has been removed
/NOTICE.txt has been removed
/README.md has been removed
/README.txt has been removed
# alluxio系统中没有的文件,但是underfs包括的文件,读取一遍后元数据会载入alluxio
[hadoop@hadoop-master2 ~]$ alluxio fs ls /
1366.00B 04-16-2016 08:09:30:996 In Memory /README.txt
[hadoop@hadoop-master2 ~]$ alluxio fs cat /LICENSE.txt
[hadoop@hadoop-master2 ~]$ alluxio fs ls /
1366.00B 04-16-2016 08:09:30:996 In Memory /README.txt
15.07KB 04-16-2016 08:26:22:495 Not In Memory /LICENSE.txt
|
文件结构大概搞明白了,从 underfs 加载目录结构(loadufs),文件载入alluxio内存(fs load),alluxio文件持久化(fs persist)都有对应的命令。
理解 mount 和linux的mount类似,把 underfs 当做一个硬盘设备去理解。
但是好像没有修改文件的API,难道不支持修改??暂时好像没有(2016-4-15 23:06:20 v1.1)
http://alluxio.org/documentation/master/en/Key-Value-System-API.html
Like files in Alluxio filesystem, the semantics of key-value system are also write-once
FileSystem API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| # scala
object App {
def using[A <: {def close() : Unit}, B](resource: A)(f: A => B): B =
try { f(resource) } finally { resource.close() }
def main(args: Array[String]) {
// @see alluxio.Configuration.Configuration(boolean)
System.setProperty(Constants.MASTER_HOSTNAME, "192.168.191.132")
System.setProperty("HADOOP_USER_NAME", "hadoop")
val fs = FileSystem.Factory.get();
val path = new AlluxioURI("/README.md");
using(fs.createFile(path, CreateFileOptions.defaults().setWriteType(WriteType.THROUGH))){ out =>
val content =
"""FileSystem API Write.
-------------------------
Hello World!
"""
out.write(content.getBytes)
}
using(fs.openFile(path)) { in =>
val buffer = new Array[Byte](1024)
val size = in.read(buffer)
System.out.println(new String(buffer, 0, size))
}
}
}
# THROUGH 仅写入到underfs
[hadoop@hadoop-master2 alluxio-1.0.1]$ bin/alluxio fs ls /README.md
115.00B 04-15-2016 20:36:57:345 Not In Memory /README.md
[hadoop@hadoop-master2 alluxio-1.0.1]$ ~/hadoop-2.6.3/bin/hadoop fs -cat /alluxio/README.md
FileSystem API Write.
-------------------------
Hello World!
[hadoop@hadoop-master2 alluxio-1.0.1]$
|
程序在win10系统运行,需要把 core-site.xml 加到 src/main/resources 下面(前面配置为了省事直接写 hdfs:///alluxio, 不加载配置的话程序不知道namenode)
如果把WriteType设置为 CACHE_THROUGH ,写 underfs 的同时也会写本地缓存。提交成功后,文件的状态为:
1
2
3
4
5
6
7
8
9
10
11
| [hadoop@hadoop-master2 alluxio-1.1.0-SNAPSHOT]$ bin/alluxio fs ls /README.md
115.00B 04-15-2016 23:48:33:749 In Memory /README.md
[hadoop@hadoop-master2 alluxio-1.1.0-SNAPSHOT]$ bin/alluxio fs fileInfo /README.md
FileInfo{fileId=318767103, name=README.md, path=/README.md, ufsPath=hdfs:///alluxio/README.md, length=115, blockSizeBytes=536870912, creationTimeMs=1460735313749, completed=true, folder=false, pinned=false, cacheable=true, persisted=true, blockIds=[301989888], inMemoryPercentage=100, lastModificationTimesMs=1460735315749, ttl=-1, userName=, groupName=, permission=0, persistenceState=PERSISTED, mountPoint=false}
Containing the following blocks:
BlockInfo{id=301989888, length=115, locations=[BlockLocation{workerId=1, address=WorkerNetAddress{host=bigdata1, rpcPort=29998, dataPort=29999, webPort=30000}, tierAlias=MEM}]}
[hadoop@hadoop-master2 alluxio-1.1.0-SNAPSHOT]$ ~/hadoop-2.6.3/bin/hadoop fs -ls /alluxio/
Found 4 items
-rw-r--r-- 1 hadoop supergroup 15429 2016-04-15 09:57 /alluxio/LICENSE.txt
-rw-r--r-- 1 hadoop supergroup 101 2016-04-15 09:57 /alluxio/NOTICE.txt
-rwxrwxrwx 1 hadoop supergroup 115 2016-04-15 23:48 /alluxio/README.md
|
大数据程序中使用Alluxio
hadoop2通过 org.apache.hadoop.fs.FileSystem services获取绑定的对象,所以不需要在core-site.xml里面配置 fs.alluxio.impl 和 fs.alluxio-ft.impl
其实都是通过 Hadoop FileSystem API 来访问Alluxio的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| # .bash_profile加环境变量
[hadoop@hadoop-master2 ~]$ vi ~/.bash_profile
...
HADOOP_HOME=~/hadoop
SPARK_HOME=~/spark
ALLUXIO_HOME=~/alluxio
PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$ALLUXIO_HOME/bin:$MAVEN_HOME/bin:$ANT_HOME/bin:$PATH
# 这里没有 export HADOOP_HOME SPARK_HOME
# 因为在hadoop/spark的启动脚本也定义了这些变量。如果export,也需要把软链接同步到slaves节点
export PATH ANT_HOME MAVEN_HOME
[hadoop@hadoop-master2 ~]$ ln -s hadoop-2.6.3 hadoop
[hadoop@hadoop-master2 ~]$ ln -s alluxio-1.1.0-SNAPSHOT alluxio
[hadoop@hadoop-master2 ~]$ ln -s spark-1.6.0-bin-2.6.3 spark
[hadoop@hadoop-master2 ~]$ . .bash_profile
[hadoop@hadoop-master2 ~]$ export SPARK_CLASSPATH=\
> ~/alluxio/core/client/target/alluxio-core-client-1.1.0-SNAPSHOT-jar-with-dependencies.jar
[hadoop@hadoop-master2 ~]$
[hadoop@hadoop-master2 ~]$ spark-shell --master local
scala> val file=sc.textFile("alluxio://hadoop-master2:19998/README.txt")
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:27
scala> file.count()
res0: Long = 31
scala> file.take(2)
res1: Array[String] = Array(For the latest information about Hadoop, please visit our website at:, "")
# wordcount
scala> val op = file.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
# word sort asc
scala> op.sortByKey().take(10)
# count sort desc
scala> op.map(kv => (kv._2, kv._1)).sortByKey(false).map(kv => (kv._2, kv._1)).take(10)
scala> op.map(kv => (kv._2, kv._1)).sortByKey(false).map(kv => (kv._2, kv._1)).saveAsTextFile("alluxio://hadoop-master2:19998/output/")
[hadoop@hadoop-master2 ~]$ alluxio fs cat /output/*
(,18)
(the,8)
(and,6)
(of,5)
(The,4)
(this,3)
(encryption,3)
(for,3)
...
|
如果运行在集群,在slave的节点也需要与主节点一样的目录结构。 或者按照官网的教程操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
| # spark_classpath 会被带到 task 的启动环境变量里面
[hadoop@hadoop-master2 ~]$ rsync -az alluxio bigdata1:~/
[hadoop@hadoop-master2 ~]$ export SPARK_CLASSPATH=\
> ~/alluxio/core/client/target/alluxio-core-client-1.1.0-SNAPSHOT-jar-with-dependencies.jar
[hadoop@hadoop-master2 ~]$ spark-shell --master spark://hadoop-master2:7077
scala> val file=sc.textFile("alluxio://hadoop-master2:19998/README.txt")
file: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:27
scala> val op = file.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
op: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:29
scala> op.map(kv => (kv._2, kv._1)).sortByKey(false).map(kv => (kv._2, kv._1)).saveAsTextFile("alluxio://hadoop-master2:19998/output2/")
|
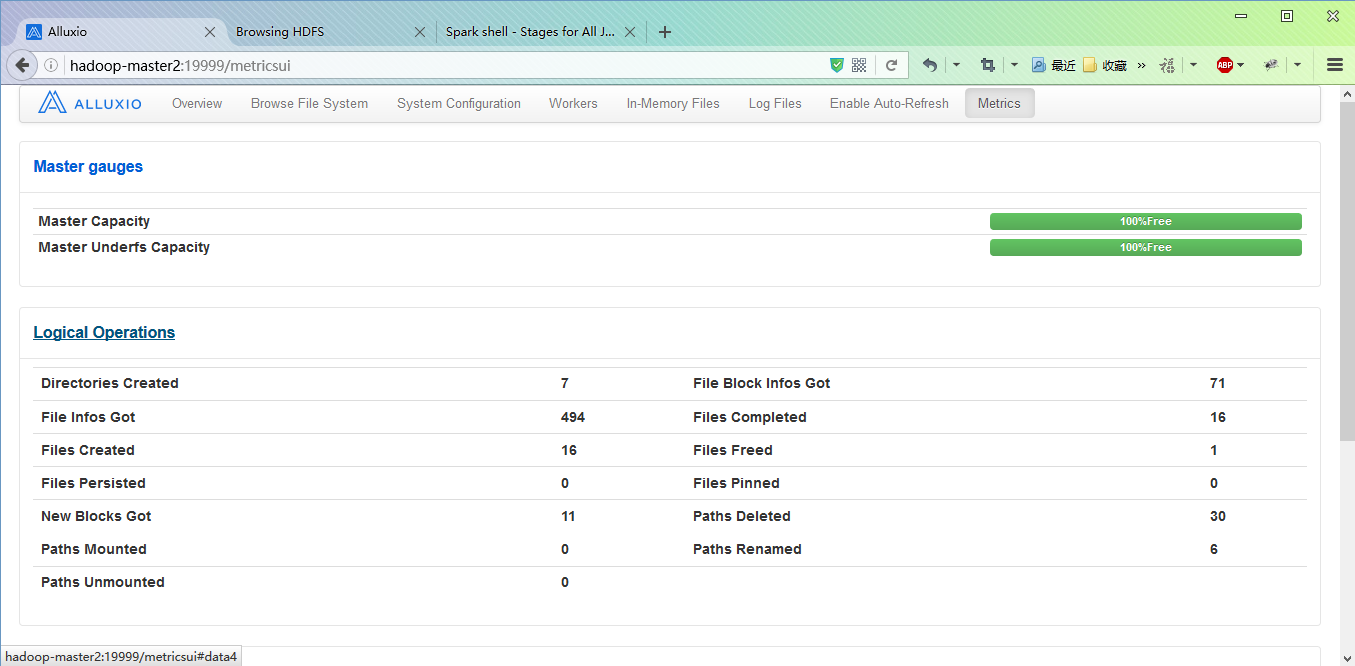
Metrics
http://www.alluxio.org/documentation/master/cn/Metrics-System.html
v1.0.1有对应的api,可以通过 http://hadoop-master2:19999/metrics/json/ 查看。当前master主干分支v1.1.0可以在网页上面查看这些指标。
1
2
3
4
5
6
7
8
9
10
11
| # 拷贝配置
[hadoop@hadoop-master2 alluxio-1.1.0-SNAPSHOT]$ cd conf
[hadoop@hadoop-master2 conf]$ cp ~/alluxio-1.0.1/conf/alluxio-env.sh ./
[hadoop@hadoop-master2 conf]$ cp ~/alluxio-1.0.1/conf/log4j.properties ./
[hadoop@hadoop-master2 conf]$ cp ~/alluxio-1.0.1/conf/workers ./
# 启动master(使用原来的元数据)
# 共享元数据,在 alluxio-env.sh 修改环境变量 ALLUXIO_JAVA_OPTS
# 添加 -Dalluxio.master.journal.folder=${ALLUXIO_JOURNAL_FOLDER} / ALLUXIO_JOURNAL_FOLDER=/home/hadoop/journal
[hadoop@hadoop-master2 alluxio-1.1.0-SNAPSHOT]$ bin/alluxio-start.sh master
Starting master @ hadoop-master2. Logging to /home/hadoop/alluxio-1.1.0-SNAPSHOT/logs
|
v1.1.0 页面多了 Metrics 页签:
其他文档
–END