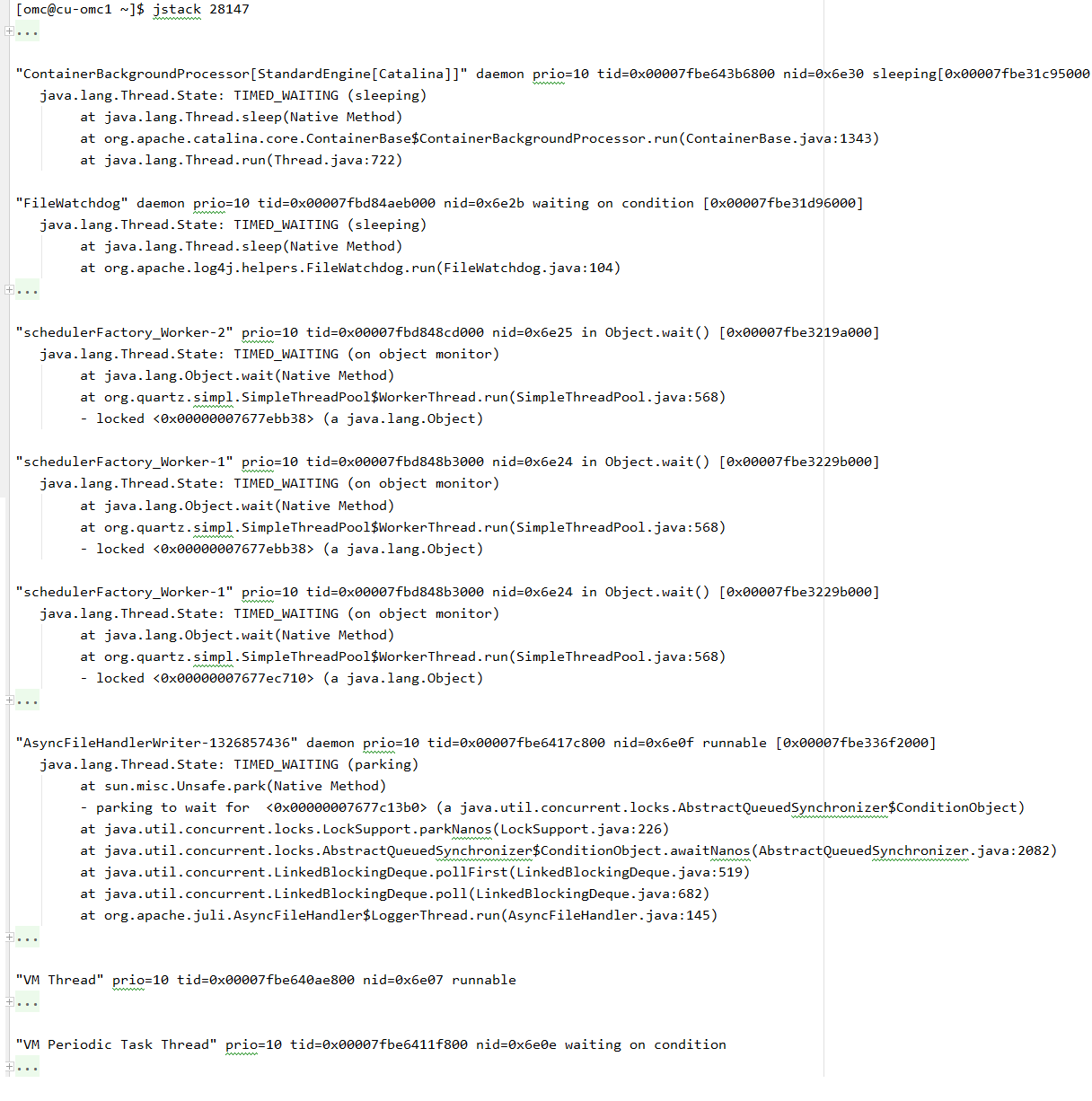
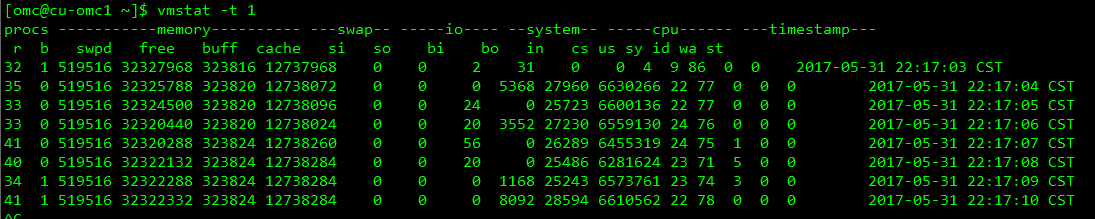
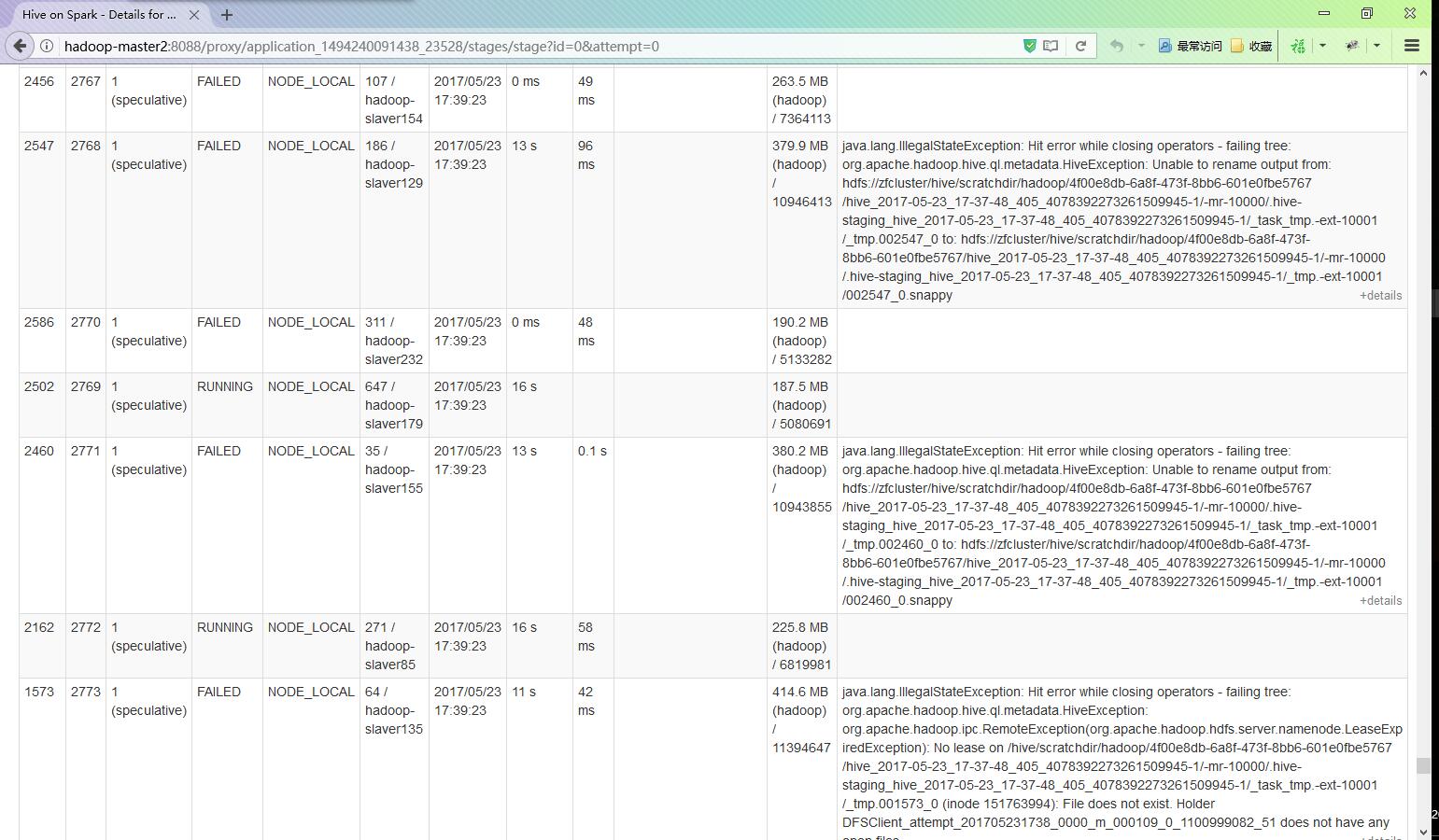
[ERROR] 14:19:56.685 [RMI TCP Connection(7)-192.168.31.11] c.e.z.h.s.BaseHiveQueryService | Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask
java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask
at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:296)
at org.apache.hive.jdbc.HiveStatement.executeQuery(HiveStatement.java:392)
at org.apache.hive.jdbc.HivePreparedStatement.executeQuery(HivePreparedStatement.java:109)
at org.apache.commons.dbcp.DelegatingPreparedStatement.executeQuery(DelegatingPreparedStatement.java:96)
at org.apache.commons.dbcp.DelegatingPreparedStatement.executeQuery(DelegatingPreparedStatement.java:96)
at com.esw.zhfx.hbase.service.BaseHiveQueryService.listIteratorInternal(BaseHiveQueryService.java:101)
at com.esw.zhfx.hbase.service.BaseHiveQueryService.listIterator(BaseHiveQueryService.java:80)
at com.esw.zhfx.hbase.QueryService.getAccessLogIterator(QueryService.java:140)
at com.esw.zhfx.hbase.QueryService$$FastClassByCGLIB$$a60bf6f7.invoke(<generated>)
at net.sf.cglib.proxy.MethodProxy.invoke(MethodProxy.java:191)
at org.springframework.aop.framework.Cglib2AopProxy$CglibMethodInvocation.invokeJoinpoint(Cglib2AopProxy.java:688)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:150)
at org.springframework.aop.framework.adapter.AfterReturningAdviceInterceptor.invoke(AfterReturningAdviceInterceptor.java:50)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.adapter.MethodBeforeAdviceInterceptor.invoke(MethodBeforeAdviceInterceptor.java:50)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:89)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.Cglib2AopProxy$DynamicAdvisedInterceptor.intercept(Cglib2AopProxy.java:621)
at com.esw.zhfx.hbase.QueryService$$EnhancerByCGLIB$$9a4ab584.getAccessLogIterator(<generated>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:309)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:183)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:150)
at org.springframework.remoting.support.RemoteInvocationTraceInterceptor.invoke(RemoteInvocationTraceInterceptor.java:77)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:172)
at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:202)
at com.sun.proxy.$Proxy22.getAccessLogIterator(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
HIVE服务日志:rename错了,但是也好像看不到啥。知道那个节点有问题了,去查节点日志
1234567891011121314151617181920212223242526272829
2017-05-23 14:19:20,509 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - 2017-05-23 14:19:20,508 WARN [task-result-getter-1] scheduler.TaskSetManager: Lost task 2199.1 in stage 2.0 (TID 4517, hadoop-slaver41): java.lang.IllegalStateException: Hit error while closing operators - failing tree: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to rename output from: hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0 to: hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_tmp.-ext-10001/002199_0.snappy
2017-05-23 14:19:20,509 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.spark.SparkMapRecordHandler.close(SparkMapRecordHandler.java:195)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.spark.HiveMapFunctionResultList.closeRecordProcessor(HiveMapFunctionResultList.java:58)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.spark.HiveBaseFunctionResultList$ResultIterator.hasNext(HiveBaseFunctionResultList.java:106)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:41)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at scala.collection.Iterator$class.foreach(Iterator.scala:727)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at scala.collection.AbstractIterator.foreach(Iterator.scala:1157)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$2.apply(AsyncRDDActions.scala:114)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$2.apply(AsyncRDDActions.scala:114)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.spark.SparkContext$$anonfun$33.apply(SparkContext.scala:1576)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.spark.SparkContext$$anonfun$33.apply(SparkContext.scala:1576)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:61)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.spark.scheduler.Task.run(Task.scala:64)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at java.lang.Thread.run(Thread.java:722)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to rename output from: hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0 to: hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_tmp.-ext-10001/002199_0.snappy
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.FileSinkOperator$FSPaths.commit(FileSinkOperator.java:237)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.FileSinkOperator$FSPaths.access$200(FileSinkOperator.java:143)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.FileSinkOperator.closeOp(FileSinkOperator.java:1051)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:616)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
2017-05-23 14:19:20,510 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
2017-05-23 14:19:20,511 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - at org.apache.hadoop.hive.ql.exec.spark.SparkMapRecordHandler.close(SparkMapRecordHandler.java:172)
2017-05-23 14:19:20,511 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) - ... 15 more
2017-05-23 14:19:20,511 INFO client.SparkClientImpl (SparkClientImpl.java:run(569)) -
17/05/23 14:19:18 INFO exec.FileSinkOperator: FS[24]: records written - 0
17/05/23 14:19:18 INFO exec.FileSinkOperator: Final Path: FS hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_tmp.-ext-10001/002199_0
17/05/23 14:19:18 INFO exec.FileSinkOperator: Writing to temp file: FS hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0
17/05/23 14:19:18 INFO exec.FileSinkOperator: New Final Path: FS hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_tmp.-ext-10001/002199_0.snappy
17/05/23 14:19:19 INFO compress.CodecPool: Got brand-new compressor [.snappy]
org.apache.hadoop.hive.ql.metadata.HiveException: Unable to rename output from: hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0 to: hdfs://zfcluster/hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_tmp.-ext-10001/002199_0.snappy
at org.apache.hadoop.hive.ql.exec.FileSinkOperator$FSPaths.commit(FileSinkOperator.java:237)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator$FSPaths.access$200(FileSinkOperator.java:143)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.closeOp(FileSinkOperator.java:1051)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:616)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:630)
at org.apache.hadoop.hive.ql.exec.spark.SparkMapRecordHandler.close(SparkMapRecordHandler.java:172)
at org.apache.hadoop.hive.ql.exec.spark.HiveMapFunctionResultList.closeRecordProcessor(HiveMapFunctionResultList.java:58)
at org.apache.hadoop.hive.ql.exec.spark.HiveBaseFunctionResultList$ResultIterator.hasNext(HiveBaseFunctionResultList.java:106)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:41)
at scala.collection.Iterator$class.foreach(Iterator.scala:727)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1157)
at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$2.apply(AsyncRDDActions.scala:114)
at org.apache.spark.rdd.AsyncRDDActions$$anonfun$foreachAsync$2.apply(AsyncRDDActions.scala:114)
at org.apache.spark.SparkContext$$anonfun$33.apply(SparkContext.scala:1576)
at org.apache.spark.SparkContext$$anonfun$33.apply(SparkContext.scala:1576)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:61)
at org.apache.spark.scheduler.Task.run(Task.scala:64)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:722)
Namenode日志:有点点线索了,分配了两次,导致了第二个任务写入的时刻报错!
123456
[hadoop@hadoop-master2 ~]$ grep '_tmp.002199' hadoop/logs/hadoop-hadoop-namenode-hadoop-master2.log.1
2017-05-23 14:19:01,591 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* allocateBlock: /hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0. BP-1414312971-192.168.32.11-1392479369615 blk_1219124858_145508182{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-ad2eac59-1e38-4019-a5ac-64c465366186:NORMAL:192.168.32.93:50010|RBW], ReplicaUnderConstruction[[DISK]DS-90c8cbe3-fd70-4ad7-938a-4248b4435df7:NORMAL:192.168.32.136:50010|RBW], ReplicaUnderConstruction[[DISK]DS-9da76df9-47f0-4e25-b375-e1bf32f4cf52:NORMAL:192.168.36.58:50010|RBW]]}
2017-05-23 14:19:14,939 INFO org.apache.hadoop.hdfs.StateChange: DIR* completeFile: /hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0 is closed by DFSClient_attempt_201705231411_0000_m_001585_0_1316598676_51
2017-05-23 14:19:20,368 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* allocateBlock: /hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0. BP-1414312971-192.168.32.11-1392479369615 blk_1219125517_145508841{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-4d4c90f0-1ddf-4800-b33a-e776e58dc744:NORMAL:192.168.32.61:50010|RBW], ReplicaUnderConstruction[[DISK]DS-948cd823-5a4c-4673-8ace-99f02a26522b:NORMAL:192.168.32.52:50010|RBW], ReplicaUnderConstruction[[DISK]DS-7818addb-3881-446e-abb3-2c178be6bb63:NORMAL:192.168.32.176:50010|RBW]]}
2017-05-23 14:19:20,478 INFO org.apache.hadoop.hdfs.StateChange: DIR* completeFile: /hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0 is closed by DFSClient_attempt_201705231411_0000_m_001345_1_1292482540_51
2017-05-23 14:19:20,480 WARN org.apache.hadoop.hdfs.StateChange: DIR* FSDirectory.unprotectedRenameTo: failed to rename /hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_task_tmp.-ext-10001/_tmp.002199_0 to /hive/scratchdir/hadoop/64801461-94aa-4e17-afee-494e77b49998/hive_2017-05-23_14-18-38_278_4858034238266422677-2/-mr-10000/.hive-staging_hive_2017-05-23_14-18-38_278_4858034238266422677-2/_tmp.-ext-10001/002199_0.snappy because destination exists
好了,看到这里,驴脑袋还没怀疑到是预测性执行导致的问题。当时想为啥会出现同一个文件名呢:SPARK ON HIVE多个stage执行导致的? 但是重启后报一样的错误,002199是哪里产生,怎么产生的?
[hadoop@hadoop-master2 hive]$ DEBUG=true bin/hive
Listening for transport dt_socket at address: 8000
Logging initialized using configuration in file:/home/hadoop/apache-hive-1.2.1-bin/conf/hive-log4j.properties
hive> set hive.execution.engine=spark; '查询之前需要设置下引擎,故障得先处理。搞成默认的mr跑是成功的
hive> 'SQLSQLSQL...执行刚报错的SQL
Query ID = hadoop_20170523173748_7660d9fb-9683-4792-8315-a51f6dcc270b
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Spark Job = 48a8668b-1c59-4cbf-b1e2-e19612ee77d0
Query Hive on Spark job[0] stages:
0
Status: Running (Hive on Spark job[0])
Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount [StageCost]
2017-05-23 17:38:15,730 Stage-0_0: 0/2609
2017-05-23 17:38:16,739 Stage-0_0: 0(+159)/2609
...
2017-05-23 17:39:23,182 Stage-0_0: 2162(+447)/2609
2017-05-23 17:39:24,188 Stage-0_0: 2167(+608)/2609
2017-05-23 17:39:25,195 Stage-0_0: 2201(+836,-1)/2609
2017-05-23 17:39:26,201 Stage-0_0: 2215(+832,-2)/2609
2017-05-23 17:39:27,207 Stage-0_0: 2227(+820,-2)/2609
2017-05-23 17:39:28,213 Stage-0_0: 2250(+797,-2)/2609
2017-05-23 17:39:29,219 Stage-0_0: 2280(+767,-2)/2609
2017-05-23 17:39:30,224 Stage-0_0: 2338(+709,-2)/2609
2017-05-23 17:39:31,230 Stage-0_0: 2350(+696,-3)/2609
2017-05-23 17:39:32,236 Stage-0_0: 2359(+684,-6)/2609
2017-05-23 17:39:33,243 Stage-0_0: 2363(+676,-10)/2609
2017-05-23 17:39:34,249 Stage-0_0: 2365(+673,-12)/2609
...
[hadoop@hadoop-slaver200 ~]$ ssh hadoop-slaver202
The authenticity of host 'hadoop-slaver202 (192.168.36.59)' can't be established.
RSA key fingerprint is fe:7e:26:c4:56:ea:f4:21:61:82:6d:9b:4a:72:93:a4.
Are you sure you want to continue connecting (yes/no)?
2017-04-09 07:22:06,920 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* registerDatanode: from DatanodeRegistration(10.1.98.0, datanodeUuid=5086c549-f3bb-4ef6-8f56-05b1f7adb7d3, infoPort=50075, ipcPort=50020, storageInfo=lv=-56;cid=CID-522174fa-6e7b-4c3f-ae99-23c3018e35d7;nsid=1613705851;c=0) storage 5086c549-f3bb-4ef6-8f56-05b1f7adb7d3
2017-04-09 07:22:06,920 INFO org.apache.hadoop.net.NetworkTopology: Removing a node: /default-rack/10.1.98.0:50010
2017-04-09 07:22:06,921 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/10.1.98.0:50010
# yum安装flanneld后停止 https://kubernetes.io/docs/getting-started-guides/scratch/
ip link set flannel.1 down
ip link delete flannel.1
route -n
rm /usr/lib/systemd/system/docker.service.d/flannel.conf