[hadoop@cu2 elasticsearch-2.2.0]$ bin/plugin install file:///home/hadoop/elasticsearch-head-master.zip
-> Installing from file:/home/hadoop/elasticsearch-head-master.zip...
Trying file:/home/hadoop/elasticsearch-head-master.zip ...
Downloading .........DONE
Verifying file:/home/hadoop/elasticsearch-head-master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed head into /home/hadoop/elasticsearch-2.2.0/plugins/head
# Find the java binary
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ `command -v java` ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
2016-05-05 19:22:22,674 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.lang.RuntimeException: Cannot start datanode because the configured max locked memory size (dfs.datanode.max.locked.memory) of 134217728 bytes is more than the datanode's available RLIMIT_MEMLOCK ulimit of 65536 bytes.
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:1067)
at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:417)
2 添加RAM_DISK
123456789101112
vi hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/bigdata/hadoop/dfs/data,[RAM_DISK]/dev/shm/dfs/data</value>
</property>
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>134217728</value>
</property>
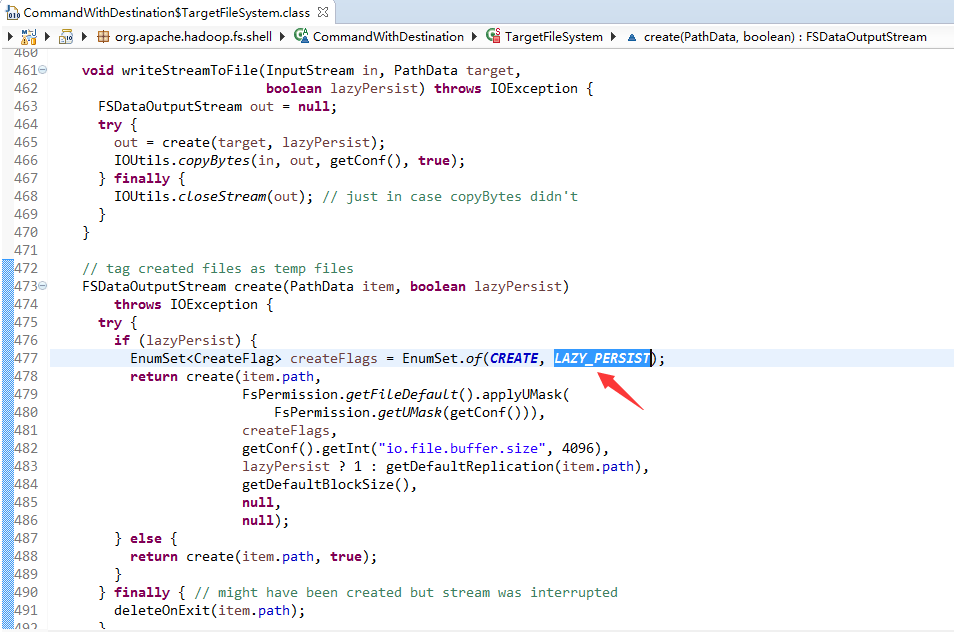
# 添加 -l 参数,后台代码会加上 LAZY_PERSIST 标识。
[hadoop@cu2 hadoop-2.6.3]$ hdfs dfs -help put
-put [-f] [-p] [-l] <localsrc> ... <dst> :
Copy files from the local file system into fs. Copying fails if the file already
exists, unless the -f flag is given.
Flags:
-p Preserves access and modification times, ownership and the mode.
-f Overwrites the destination if it already exists.
-l Allow DataNode to lazily persist the file to disk. Forces
replication factor of 1. This flag will result in reduced
durability. Use with care.
1234567891011121314151617181920212223242526
# -l 参数会把 replication 强制设置成数字1 !
[hadoop@cu2 hadoop-2.6.3]$ hdfs dfs -put -l README.txt /tmp/readme.txt2
# 查看namenode的日志,可以看到文件写入到 RAM_DISK 类型的存储
[hadoop@cu2 hadoop-2.6.3]$ less logs/hadoop-hadoop-namenode-cu2.log
2016-05-05 20:38:36,465 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* allocateBlock: /tmp/readme.txt2._COPYING_. BP-1108852639-192.168.0.148-1452322889531 blk_1073752578_11780{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-dcb2673f-3297-4bd7-af1c-ac0ee3eebaf9:NORMAL:192.168.0.30:50010|RBW]]}
2016-05-05 20:38:36,592 INFO BlockStateChange: BLOCK* addStoredBlock: blockMap updated: 192.168.0.30:50010 is added to blk_1073752578_11780{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[RAM_DISK]DS-bf1ab64f-7eb3-41e0-8466-43287de9893d:NORMAL:192.168.0.30:50010|FINALIZED]]} size 0
2016-05-05 20:38:36,594 INFO org.apache.hadoop.hdfs.StateChange: DIR* completeFile: /tmp/readme.txt2._COPYING_ is closed by DFSClient_NONMAPREDUCE_-1388277364_1
# 具体的内容所在位置
[hadoop@cu4 ~]$ tree /dev/shm/dfs/data/
/dev/shm/dfs/data/
├── current
│ ├── BP-1108852639-192.168.0.148-1452322889531
│ │ ├── current
│ │ │ ├── finalized
│ │ │ │ └── subdir0
│ │ │ │ └── subdir42
│ │ │ │ ├── blk_1073752578
│ │ │ │ └── blk_1073752578_11780.meta
│ │ │ ├── rbw
│ │ │ └── VERSION
│ │ └── tmp
│ └── VERSION
└── in_use.lock