处理方法很简单,解决后,对于ssh机器之间多次跳转的文件传输操作会方便很多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
zmoden还是有比较多的限制。sftp还是不能少啊!!
参考
–END
处理方法很简单,解决后,对于ssh机器之间多次跳转的文件传输操作会方便很多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
zmoden还是有比较多的限制。sftp还是不能少啊!!
–END
本书讲了linux维护和管理过程中常用的命令。
分12个章节,分别将了目录切换、日期、SSH远程登录、常用linux命令、PS1-4操作提示符、解压缩、命令历史记录、系统管理、容器服务器Apache、脚本环境变量、性能监控等。
介绍的命令有:cd, dirs, pushd, popd, cdpath, alias, mkdir, eval, date, hwclock, ssh, grep, find, 输出重定向, join, tr, xargs, sort, uniq, cut, stat, diff, ac, ps1, ps2, ps3, ps4, PROMPT_COMMAND, zip, unzip, tar, gzip, bzip2, HISTTIMEFORMAT, HISTSIZE, HISTIGNORE, fdisk, mke2fsk, mount, tune2fs, useradd, adduser, passwd, groupadd, id, ssh-copy-id, ssh-agent, crontab, apachectl, httpd, .bash_rc, .bash_profile, 单引号, 双引号, free, top, ps, df, kill, du, lsof, sar, vmstat, netstat, sysctl, nice, renice等等。
下面结合工作中的一些实践,谈一谈
不管是正式环境还是云端的测试环境,一般提供给我们访问的只有一个入口(也就是常说的跳板机),登录跳板机后然后才能连接其他服务器。常用的工具有【SecureCRT】和【Xshell】,它们的使用方式基本相同。
最佳实践:连接跳板机的同时,建立自己机器和内网机器之间的隧道,即可以方便浏览器的访问,同时也可以使用sftp直接传输文件到内网机器。
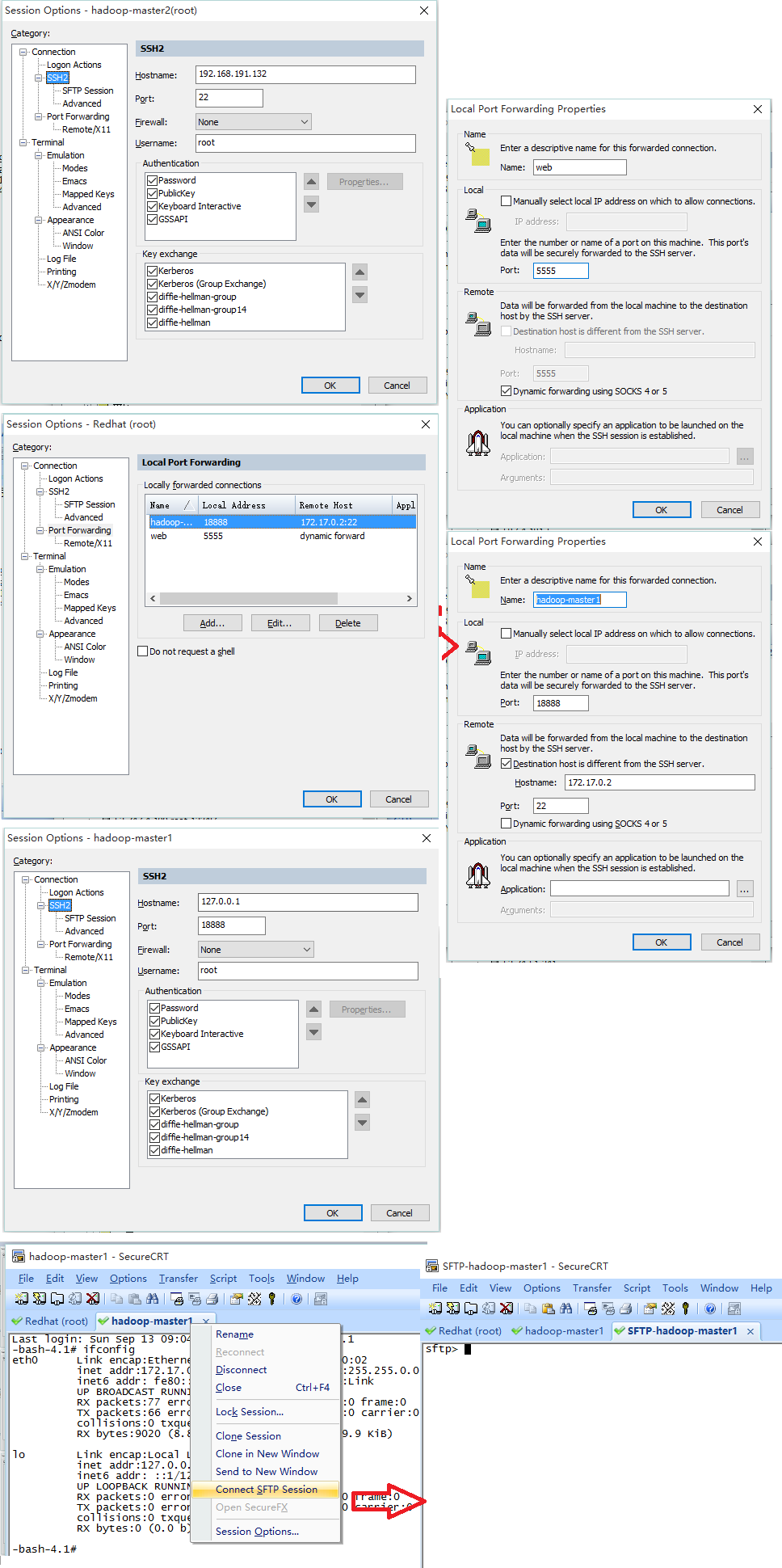
想不通,现在的教程都使用【复制-添加-修改权限】公钥的方式来进行无密钥登录配置。
1 2 3 4 5 6 7 8 9 10 11 | |
处理一个ssh无密钥登录搞N多的步骤,还不一定能成功!其实使用ssh-copy-id的命令就行了,不知道各类书籍上面都使用老旧的方法,都是抄来的吗?!
1 2 3 4 5 6 7 8 9 10 11 | |
碰到不认识的人,我们都会上下打量。机器也一样,首先要了解机器,才能充分的发挥自己的性能。存储不够要么删点,要么加磁盘等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
一个命令的结果直接输出给另一个命令。就像水从一个结头通过管子直接流向下一个结头一样。中间不需要落地,直接立即用于下一个命令,直到结果输出。
1
| |
shell的命令那么多,简单功能的材料都准备好了,就像堆积木一样,叠加后总能实现你想得到的效果。
在进行一次性文件拷贝时,如果文件数量过多,可以先打包然后传到远程机器再解压:
1
| |
写java的没看过开源项目不要说自己会java,写shell没用过man不要说自己会shell!
1 2 3 4 5 | |
总有一款适合你,带着实践和问题的目的去学/写,能更好的把握它。(shell的命令太多,不要寄希望于看一个宝典就能写好!实践出真知,真正用到的才是实用的)
Shell脚本/命令在执行前会对变量进行解析、处理。查看最终执行的命令,能让我们了解到脚本不正确的地方,然后及时进行更正。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
调试脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
历史如足迹。如果你要学习前辈的经验,理着他的足迹,一步步的走!
很多书上说的,CTRL+R, !!, !-1, CTRL+P, ![CMD], !!:$, !^, ![CMD]:2, ![CMD]:$用于获取以后执行的命令或者参数,多半好看不实用。会写的也就前面1-2个命令重复用一下,上下方向键就可以了,不会写的用history查看全部慢慢学更实际点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
这些就不是看看man就能上手的,细嚼慢咽找几本书翻翻!!
推荐两本书: [sed与awk(第二版)], [Shell脚本学习指南]
传入用户(与ssh的用户一致)密码,进行SSH无密钥认证:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
传入新用户名称和密码,新建用户:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
当然还有很多命令,xargs, if等需要在实践中慢慢积累,shell博大精深继续码字!cdpath眼前一亮,alias还可以这么用!!
在linux把xml转成properties键值对形式的命令,觉得也挺有意思的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
–END
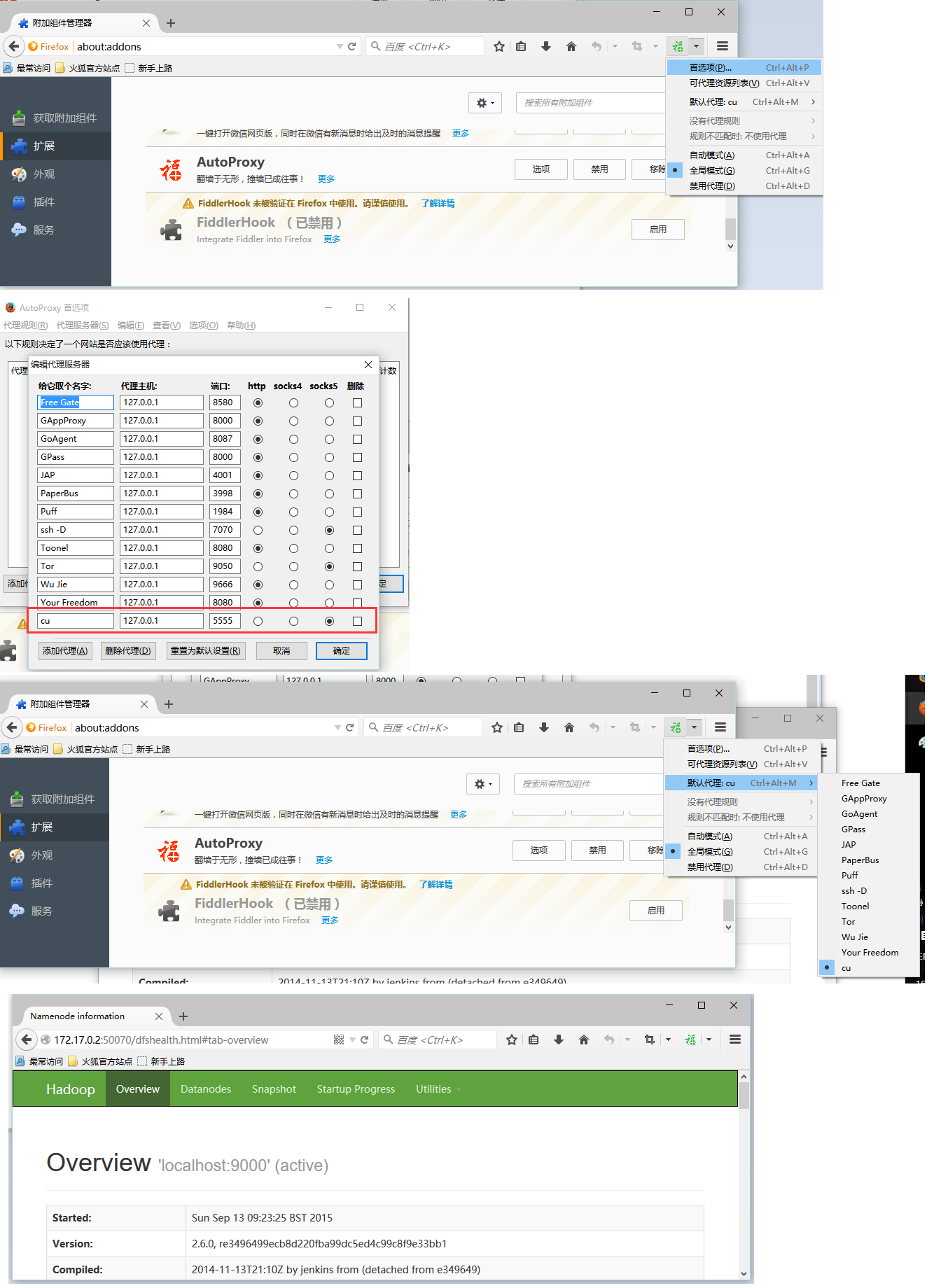
说明:cu2就是hadoop-master2
1 2 3 4 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 3 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 3 4 5 6 7 8 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | |
http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-common/ClusterSetup.html
–END
1 2 3 4 5 6 7 8 9 10 11 | |
或者:
1 2 | |
改下squid.conf的配置:
1 2 3 | |
在浏览器中设置Http代理。端口为3128
–END
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | |
supervisor使用ini的方式配置其实挺讨厌的,但有一点好的就是它不需要配置为boot进程(process id 1)。
下载 https://pypi.python.org/pypi/supervisor ,并安装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
安装官网的版本下载: Installing To A System Without Internet Access
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
ctl命令查看状态:
网页管理:
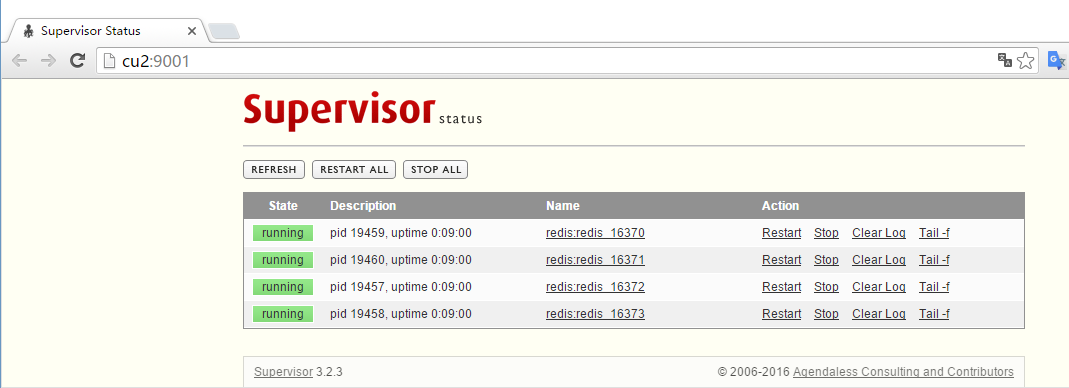
http://supervisord.org/configuration.html
默认server(supervisord)-client(supervisorctl)通过 unix domain socket 文件的方式来通信,为了方便网页查看同时开启web配置 inet_http_server。
program区域的配置要细读,主要配置工作都在这个上面。被管理的程序 不能后台运行 (例如:java程序不要加 nohup 以及 & )!!
Controlled programs should themselves not be daemons, as supervisord assumes it is responsible for daemonizing its subprocesses
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | |
1 2 3 4 5 6 7 8 9 10 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
其他的安装方式参考官网文章:
生成配置文件: http://supervisord.org/installing.html#creating-a-configuration-file
you can place it in the current directory (echo_supervisord_conf > supervisord.conf) and start supervisord with the -c flag in order to specify the configuration file location. For example, supervisord -c supervisord.conf
1 2 3 4 5 6 7 8 9 | |
已服务的方式启动(centos6): http://supervisord.org/running.html#running-supervisord-automatically-on-startup
1 2 3 4 5 6 7 | |
编写配置管理服务:
1 2 3 4 5 6 7 8 | |
command 字段设置的是后台守护应用的启动命令, 注意: 该命令必须是在前台执行的, 即会独占控制台, 否则会导致 supervisor 无法获得标准输出, 并失去进程的控制权.
1 2 3 4 5 | |
–END