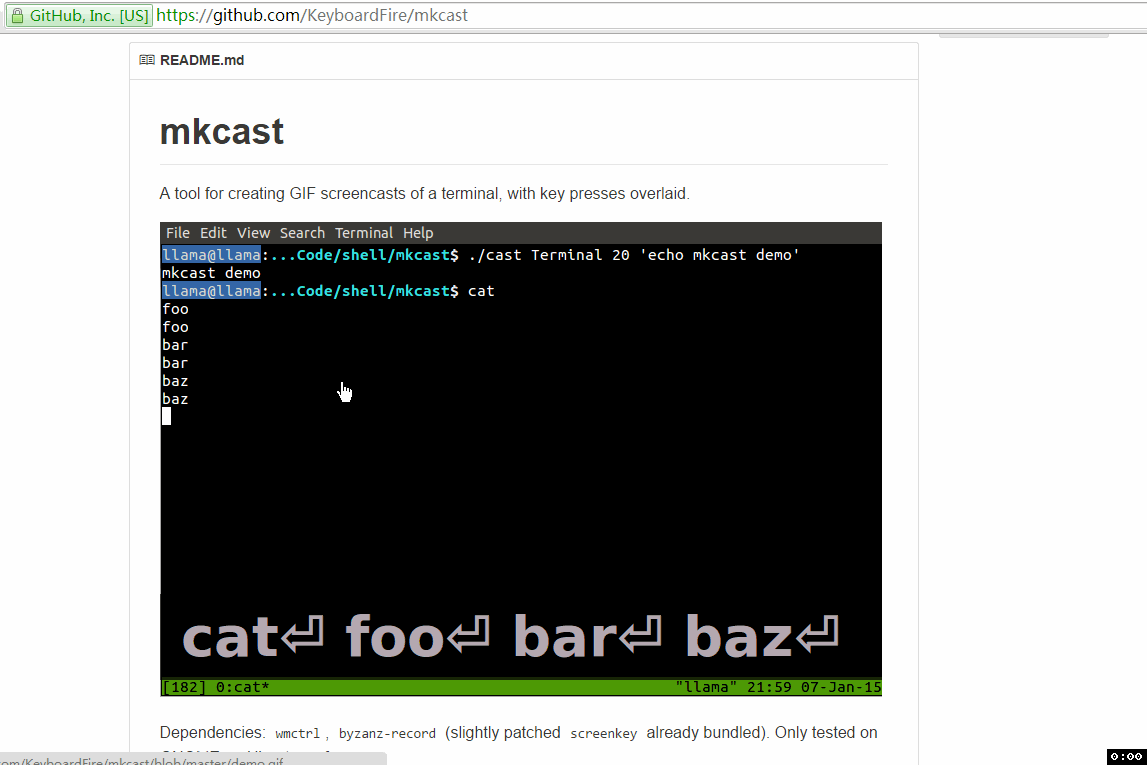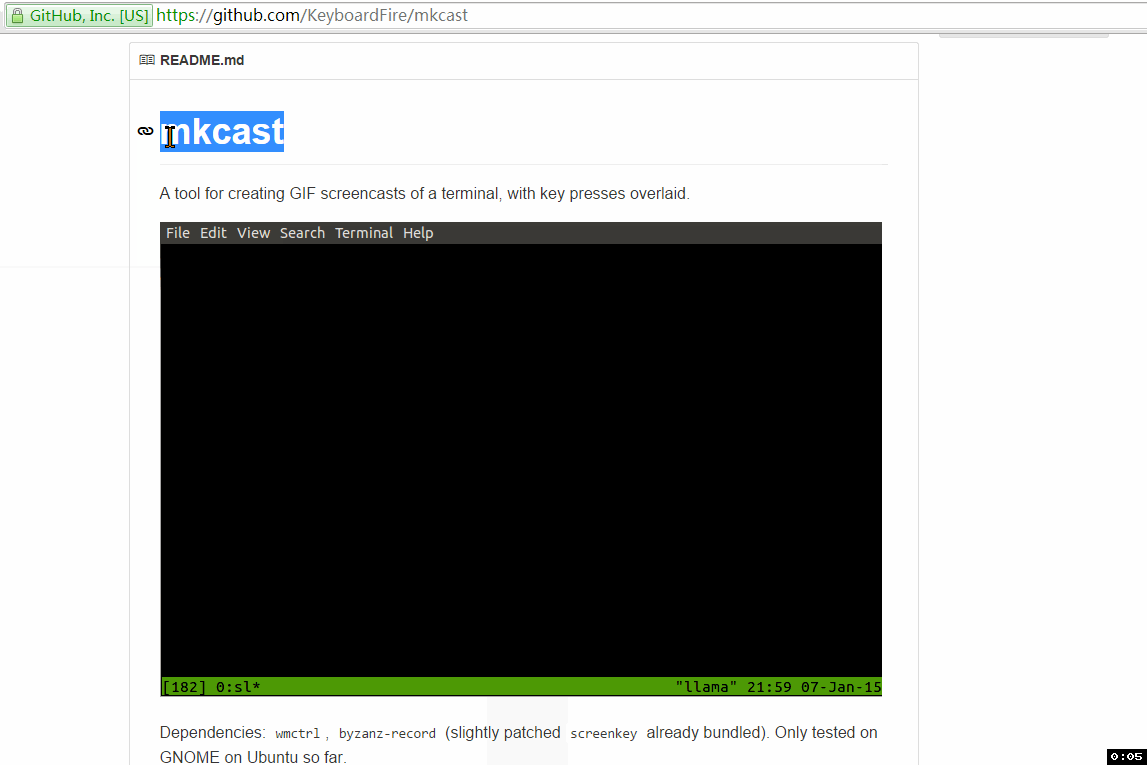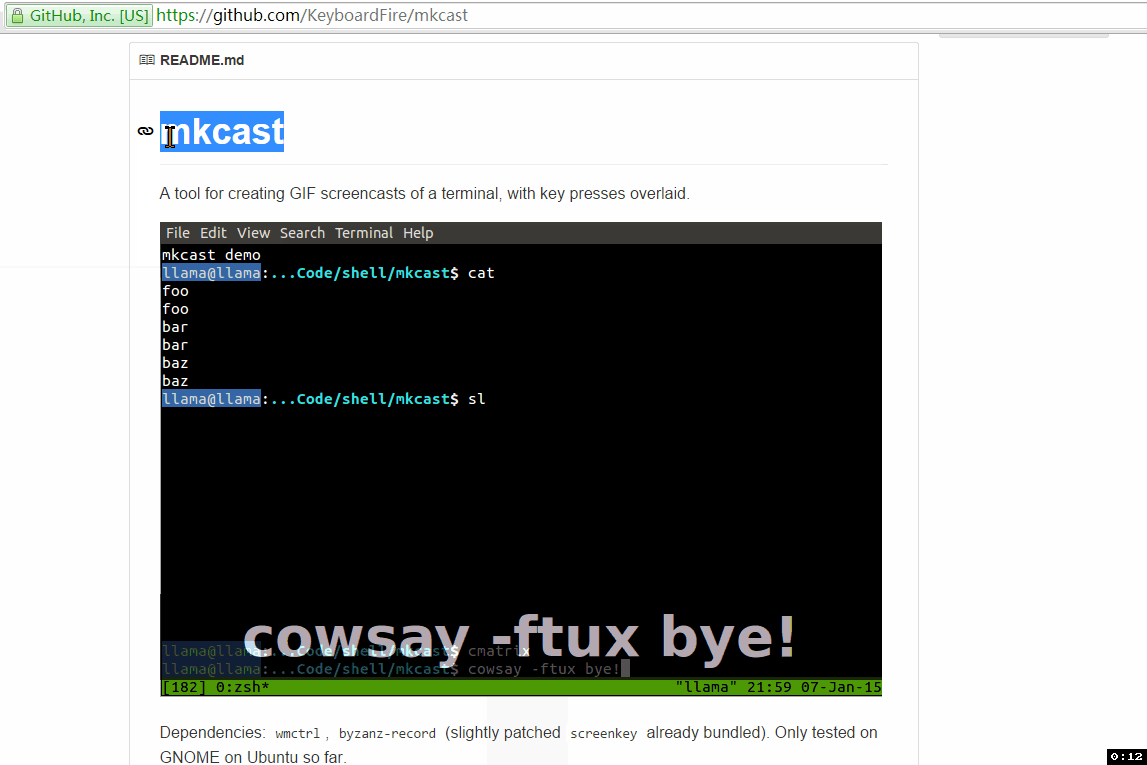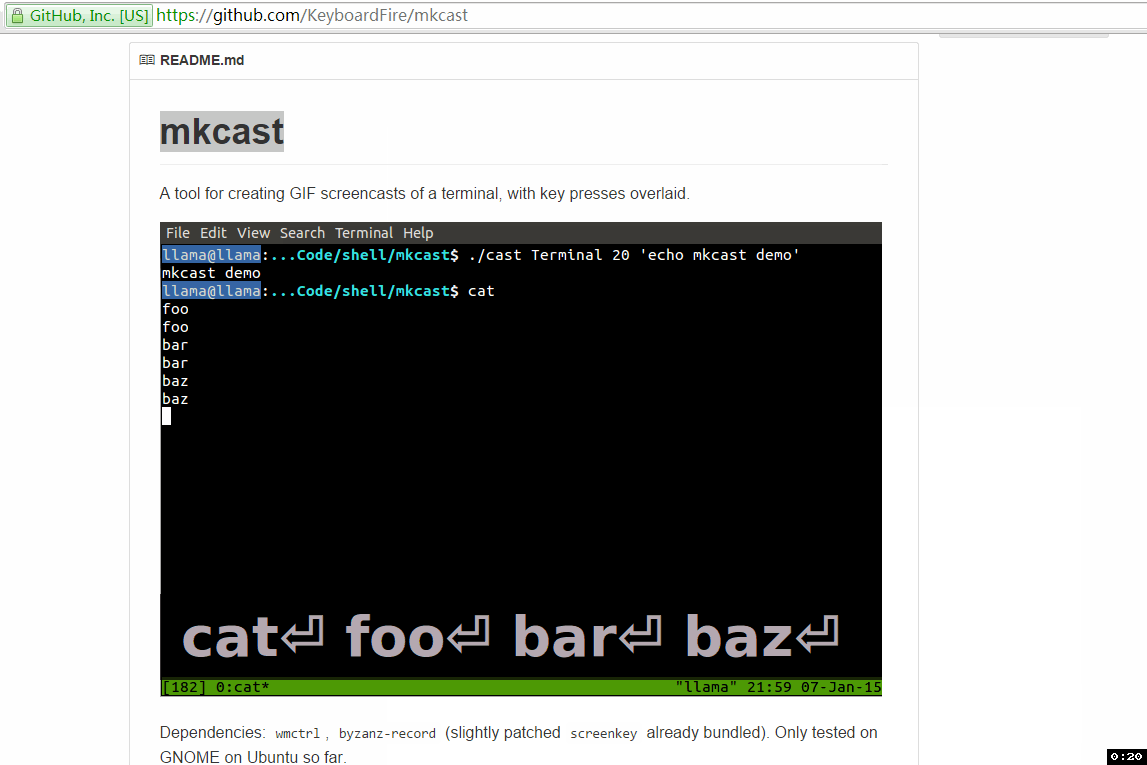
// import all BTrace annotations
import com.sun.btrace.annotations.*;
// import statics from BTraceUtils class
import static com.sun.btrace.BTraceUtils.*;
// @BTrace annotation tells that this is a BTrace program
@BTrace
public class HelloWorld {
// @OnMethod annotation tells where to probe.
// In this example, we are interested in entry
// into the Thread.start() method.
@OnMethod(
clazz="java.lang.Thread",
method="start"
)
public static void func() {
// println is defined in BTraceUtils
// you can only call the static methods of BTraceUtils
println("about to start a thread!");
}
}
public class HelloTest {
@Test
public void test() throws Exception {
testNewThread();
}
public void testNewThread() throws InterruptedException {
Thread.sleep(20 * 1000); // 最佳方式就是使用Scanner,手动输入一个操作后执行后面的操作。scanner.nextLine()
for (int i = 0; i < 100; i++) {
final int index = i;
new Thread(//
new Runnable() {
public void run() {
System.out.println("my order: " + index);
}
} //
).start();
}
}
}
然后,启动btrace程序:
1234567891011
cd src\test\script
#下面的内容是一个批处理文件
set PATH=%PATH%;C:\cygwin\bin;C:\cygwin\usr\local\bin
set BTRACE_HOME=E:\local\opt\btrace-bin
set CUR_ROOT=%cd%\..\..\..
set SCRIPT=%CUR_ROOT%\src\main\java\com\github\winse\btrace\HelloWorld.java
set SCRIPT=%CUR_ROOT%\target\classes\com\github\winse\btrace\HelloWorld.class
jps -m | findstr HelloTest | gawk '{print $1}' | xargs -I {} %BTRACE_HOME%\bin\btrace.bat {} %SCRIPT%
cd libunwind-0.99-beta
./configure
make && make install
cd /home/hadoop/gperftools-2.4
./configure
make && make install
cd redis-2.8.13
make MALLOC=tcmalloc
如果出现./libtool: line 1125: g++: command not found的错误,缺少编译环境;
redis-ser 1716 hadoop mem REG 253,0 2201976 936349 /usr/local/lib/libtcmalloc.so.4.2.6
修改配置文件找到daemonize,将后面的no改为yes,让其可以以服务方式运行。
普通用户安装
考虑到可以各台机器上面复制,指定编译目录这种方式会比较方便。
12345678910
cd libunwind-0.99-beta
CFLAGS=-fPIC ./configure --prefix=/home/hadoop/redis
make && make install
cd gperftools-2.4
./configure -h
export LDFLAGS="-L/home/hadoop/redis/lib"
export CPPFLAGS="-I/home/hadoop/redis/include"
./configure --prefix=/home/hadoop/redis
make && make install
[hadoop@master1 redis-2.8.13]$ export LD_LIBRARY_PATH=/home/hadoop/redis-2.8.13/src/lib
[hadoop@master1 redis-2.8.13]$ make MALLOC=tcmalloc
cd src && make all
make[1]: Entering directory `/home/hadoop/redis-2.8.13/src'
LINK redis-server
INSTALL redis-sentinel
CC redis-cli.o
In file included from zmalloc.h:40,
from redis-cli.c:50:
./include/google/tcmalloc.h:35:2: warning: #warning is a GCC extension
./include/google/tcmalloc.h:35:2: warning: #warning "google/tcmalloc.h is deprecated. Use gperftools/tcmalloc.h instead"
LINK redis-cli
CC redis-benchmark.o
In file included from zmalloc.h:40,
from redis-benchmark.c:47:
./include/google/tcmalloc.h:35:2: warning: #warning is a GCC extension
./include/google/tcmalloc.h:35:2: warning: #warning "google/tcmalloc.h is deprecated. Use gperftools/tcmalloc.h instead"
LINK redis-benchmark
CC redis-check-dump.o
LINK redis-check-dump
CC redis-check-aof.o
LINK redis-check-aof
Hint: To run 'make test' is a good idea ;)
make[1]: Leaving directory `/home/hadoop/redis-2.8.13/src'
[hadoop@master1 redis-2.8.13]$
rem 生产者
bin\windows>kafka-console-producer.bat --broker-list localhost:9092 --topic hello
rem 消费者(新开一个窗口)
bin\windows>kafka-console-consumer.bat --zookeeper localhost:2181 --topic hello --from-beginning
都启动后,在producer的窗口输入信息。同一时刻,consumer也会打印输入的内容。
这个两个命令都有很多参数,直接输入命令不加任何参数可以输出帮助,了解各个参数的含义及其用法。
Kafka集群
集群的配置和zookeeper的集群配置方式很类似。只要修改broker.id和数据存储目录即可。
拷贝server.properties,然后修改下面的三个属性:
123
broker.id=1
port=9192
log.dir=/tmp/kafka-logs-1
然后启动:
123456
set JMX_PORT=19999
start kafka-server-start.bat ..\..\config\server-1.properties
set JMX_PORT=29999
start kafka-server-start.bat ..\..\config\server-2.properties
set JMX_PORT=39999
start kafka-server-start.bat ..\..\config\server-3.properties