本书讲了linux维护和管理过程中常用的命令。
分12个章节,分别将了目录切换、日期、SSH远程登录、常用linux命令、PS1-4操作提示符、解压缩、命令历史记录、系统管理、容器服务器Apache、脚本环境变量、性能监控等。
介绍的命令有:cd, dirs, pushd, popd, cdpath, alias , mkdir, eval, date, hwclock, ssh, grep, find, 输出重定向, join, tr, xargs, sort, uniq, cut, stat, diff, ac, ps1, ps2, ps3, ps4, PROMPT_COMMAND, zip, unzip, tar, gzip, bzip2, HISTTIMEFORMAT, HISTSIZE, HISTIGNORE, fdisk, mke2fsk, mount, tune2fs, useradd, adduser, passwd, groupadd, id, ssh-copy-id, ssh-agent, crontab, apachectl, httpd, .bash_rc , .bash_profile, 单引号, 双引号, free, top, ps, df, kill, du, lsof, sar, vmstat, netstat, sysctl, nice, renice等等。
下面结合工作中的一些实践,谈一谈
技巧一:登录服务器
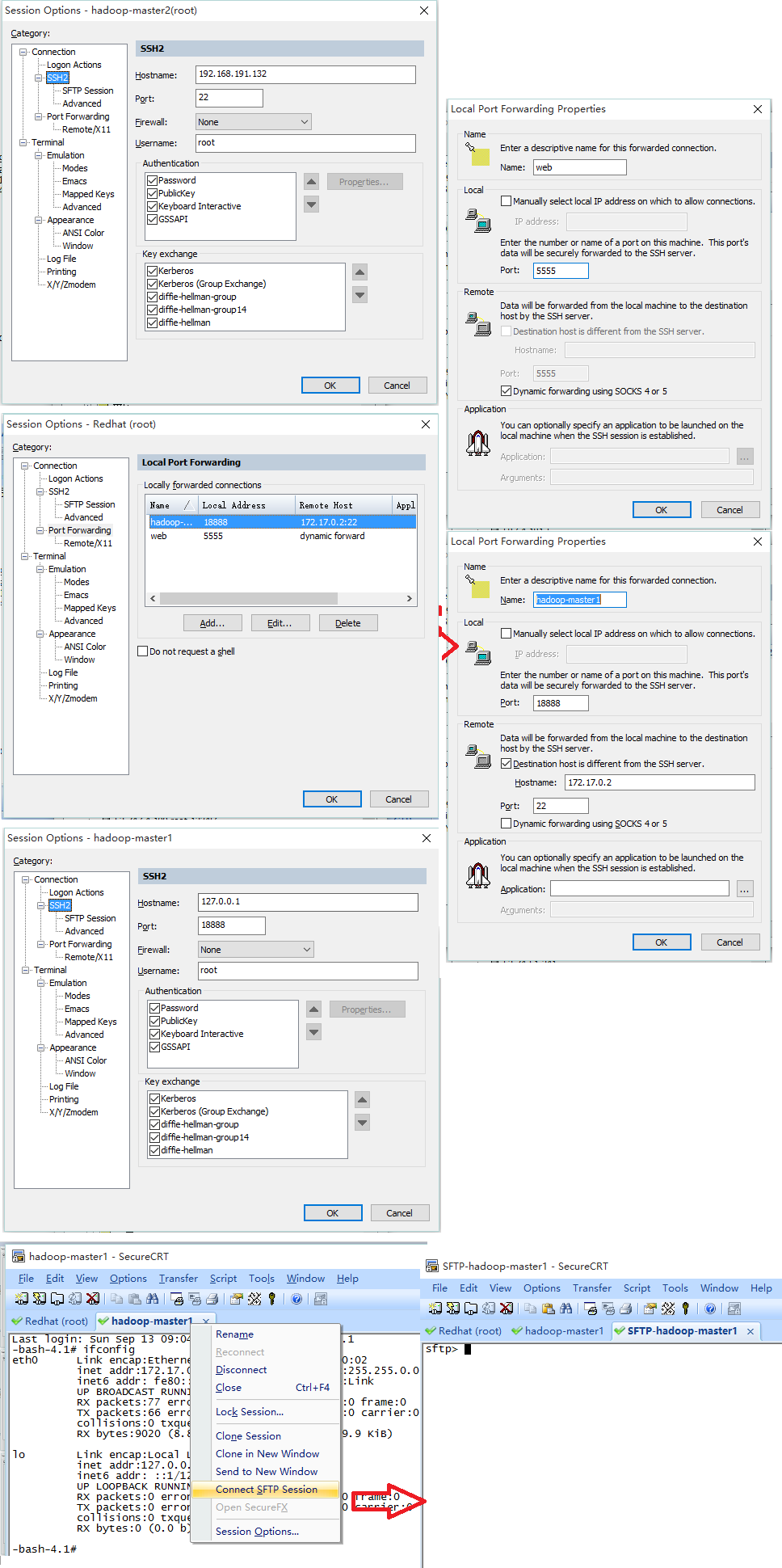
不管是正式环境还是云端的测试环境,一般提供给我们访问的只有一个入口(也就是常说的跳板机),登录跳板机后然后才能连接其他服务器。常用的工具有【SecureCRT】和【Xshell】,它们的使用方式基本相同。
最佳实践:连接跳板机的同时,建立自己机器和内网机器之间的隧道,即可以方便浏览器的访问,同时也可以使用sftp直接传输文件到内网机器。
技巧二:ssh-copy-id【hack 72】
想不通,现在的教程都使用【复制-添加-修改权限】公钥的方式来进行无密钥登录配置。
1
2
3
4
5
6
7
8
9
10
11
[hadoop@hadoop-master1 ~]$ scp .ssh/id_rsa.pub 172.17.0.3:~/master_id_rsa.pub
hadoop@172.17.0.3's password:
id_rsa.pub 100% 403 0.4KB/s 00:00
[hadoop@hadoop-master1 ~]$ ssh 172.17.0.3
hadoop@172.17.0.3's password:
Last login: Sun Sep 13 11:41:17 2015 from 172.17.0.2
[hadoop@hadoop-slaver1 ~]$ cat master_id_rsa.pub >> .ssh/authorized_keys
[hadoop@hadoop-slaver1 ~]$ ll -d .ssh
drwx------. 2 hadoop hadoop 4096 Mar 10 2015 .ssh
[hadoop@hadoop-slaver1 ~]$ ll .ssh/authorized_keys
-rw-------. 1 hadoop hadoop 403 Sep 13 11:58 .ssh/authorized_keys
处理一个ssh无密钥登录搞N多的步骤,还不一定能成功!其实使用ssh-copy-id的命令就行了,不知道各类书籍上面都使用老旧的方法,都是抄来的吗?!
1
2
3
4
5
6
7
8
9
10
11
[hadoop@hadoop-slaver1 ~]$ ssh-copy-id -i .ssh/id_rsa.pub 172.17.0.2
The authenticity of host '172.17.0.2 (172.17.0.2)' can't be established.
RSA key fingerprint is aa:41:79:6d:9d:c2:ec:f1:29:71:43:24:39:09:58:b6.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '172.17.0.2' (RSA) to the list of known hosts.
hadoop@172.17.0.2's password:
Now try logging into the machine, with "ssh '172.17.0.2'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
技巧三:查看机器
碰到不认识的人,我们都会上下打量。机器也一样,首先要了解机器,才能充分的发挥自己的性能。存储不够要么删点,要么加磁盘等等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
uname -a
cat /etc/redhat-release
ifconfig
date
df -h , df -Tha
free -m
uptime
top
ps aux , ps auxf
netstat -atp
du -h --max-depth=1
lsof -i:[PORT]
cat /etc/hosts
技巧四:管道
一个命令的结果直接输出给另一个命令。就像水从一个结头通过管子直接流向下一个结头一样。中间不需要落地,直接立即用于下一个命令,直到结果输出。
1
cat /etc/hosts | grep 'hadoop' | awk '{print $2}' | while read h ; do echo $h ; done
shell的命令那么多,简单功能的材料都准备好了,就像堆积木一样,叠加后总能实现你想得到的效果。
在进行一次性文件拷贝时,如果文件数量过多,可以先打包然后传到远程机器再解压:
1
tar zc nginx | ssh bigdata1 'tar zx'
技巧N:查看帮助
写java的没看过开源项目不要说自己会java,写shell没用过man不要说自己会shell!
1
2
3
4
5
man [CMD]
info [CMD]
[CMD] help
[CMD] -h
[CMD] -help
总有一款适合你,带着实践和问题的目的去学/写,能更好的把握它。(shell的命令太多,不要寄希望于看一个宝典就能写好!实践出真知,真正用到的才是实用的)
技巧N-1:调试Shell脚本
Shell脚本/命令在执行前会对变量进行解析、处理。查看最终执行的命令,能让我们了解到脚本不正确的地方,然后及时进行更正。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
set命令的参数说明
-v Print shell input lines as they are read.
-x After expanding each simple command, for command, case command, select command, or arithmetic for command,
display the expanded value of PS4, followed by the command and its expanded arguments or associated word list.
[hadoop@hadoop-master2 ~]$ set -x
[hadoop@hadoop-master2 1]$ cmd=*
+ cmd='*'
[hadoop@hadoop-master2 1]$ echo $cmd
+ echo 2 file
2 file
[hadoop@hadoop-master2 1]$ echo "$cmd" # 双引号
+ echo '*'
*
[hadoop@hadoop-master2 1]# echo '$cmd' # 单引号
+ echo '$cmd'
$cmd
调试脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[root@hadoop-master2 1]# vi run.sh
#!/bin/sh
bin=$(dir=`dirname $0`; cd $dir ; pwd)
cd $bin
ls -l
[root@hadoop-master2 1]# sh -x run.sh
+++ dirname run.sh
++ dir=.
++ cd .
++ pwd
+ bin=/tmp/1
+ cd /tmp/1
+ ls -l
total 8
drwxrwxr-x 2 hadoop hadoop 4096 Sep 13 20:33 2
-rw-rw-r-- 1 hadoop hadoop 0 Sep 13 20:33 file
-rw-r--r-- 1 root root 66 Sep 13 21:12 run.sh
技巧N-2:历史history
历史如足迹。如果你要学习前辈的经验,理着他的足迹,一步步的走!
很多书上说的,CTRL+R, !!, !-1, CTRL+P, ![CMD], !!:$, !^, ![CMD]:2, ![CMD]:$用于获取以后执行的命令或者参数,多半好看不实用。会写的也就前面1-2个命令重复用一下,上下方向键就可以了,不会写的用history查看全部慢慢学更实际点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
历史记录执行时间
export HISTTIMEFORMAT='%F %T '
输出最近10条历史
alias hist10='history 10'
持久化保存的历史记录数
vi ~/.bash_profile
HISTSIZE=450
HISTFILESIZE=450
# HISTFILE
忽略连续重复的命令
export HISTCONTROL=ignoredups
忽略重复的命令
export HISTCONTROL=erasedups
忽略指定的命令
export HISTIGNORE='pwd:ls'
技巧N-3:shell之grep awk sed vi
这些就不是看看man就能上手的,细嚼慢咽找几本书翻翻!!
推荐两本书: [sed与awk(第二版)], [Shell脚本学习指南]
技巧N-4:批量处理之神:expect/for/while
传入用户(与ssh的用户一致)密码,进行SSH无密钥认证:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[root@hadoop-master2 1]# vi ssh-copy-id.expect
#!/usr/bin/expect
## Usage $0 [user@]host password
set host [lrange $argv 0 0];
set password [lrange $argv 1 1] ;
set timeout 30;
spawn ssh-copy-id $host ;
expect {
"(yes/no)?" { send yes\n; exp_continue; }
"password:" { send $password\n; exp_continue; }
}
exec sleep 1;
批量处理
[root@hadoop-master2 1]# for h in `cat /etc/hosts | grep hadoop | awk '{print $2}' ` ; do ./ssh-copy-id.expect $h root-password ; done
传入新用户名称和密码,新建用户:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
[root@hadoop-master2 1]# vi passwd.expect
#!/usr/bin/expect
## Usage $0 host username password
set host [lrange $argv 0 0];
set username [lrange $argv 1 1];
set password [lrange $argv 2 2] ;
set timeout 30;
##
spawn ssh $host useradd $username ;
exec sleep 1;
##
spawn ssh $host passwd $username ;
## password and repasswd all use this
expect {
"password:" { send $password\n; exp_continue; }
}
exec sleep 1;
批量处理
[root@hadoop-master2 1]# for h in `cat /etc/hosts | grep hadoop | awk '{print $2}' ` ; do ./passwd.expect $h hadoop hadoop-password ; done
最后
当然还有很多命令,xargs, if等需要在实践中慢慢积累,shell博大精深继续码字!cdpath眼前一亮,alias还可以这么用!!
在linux把xml转成properties键值对形式的命令,觉得也挺有意思的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
[hadoop@hadoop-master2 ~]$ vi format.xslt
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" encoding="iso-8859-1"/>
<xsl:strip-space elements="*" />
<xsl:template match="/*/child::*">
<xsl:for-each select="child::*">
<xsl:if test="position() != last()"><xsl:value-of select="normalize-space(.)"/>=</xsl:if>
<xsl:if test="position() = last()"><xsl:value-of select="normalize-space(.)"/> <xsl:text>
</xsl:text> </xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
[hadoop@hadoop-master2 ~]$ xsltproc format.xslt ~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services=mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class=org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address=hadoop-master1:8032
yarn.resourcemanager.scheduler.address=hadoop-master1:8030
yarn.resourcemanager.resource-tracker.address=hadoop-master1:8031
yarn.resourcemanager.admin.address=hadoop-master1:8033
yarn.resourcemanager.webapp.address=hadoop-master1:8088
yarn.nodemanager.resource.memory-mb=51200=yarn-default.xml
yarn.scheduler.minimum-allocation-mb=1024=yarn-default.xml
–END