[root@localhost snappy-1.1.3]# ./autogen.sh
Remember to add `AC_PROG_LIBTOOL' to `configure.ac'.
You should update your `aclocal.m4' by running aclocal.
libtoolize: `config.guess' exists: use `--force' to overwrite
libtoolize: `config.sub' exists: use `--force' to overwrite
libtoolize: `ltmain.sh' exists: use `--force' to overwrite
Makefile.am:4: Libtool library used but `LIBTOOL' is undefined
Makefile.am:4:
Makefile.am:4: The usual way to define `LIBTOOL' is to add `AC_PROG_LIBTOOL'
Makefile.am:4: to `configure.ac' and run `aclocal' and `autoconf' again.
Makefile.am:20: `dist_doc_DATA' is used but `docdir' is undefined
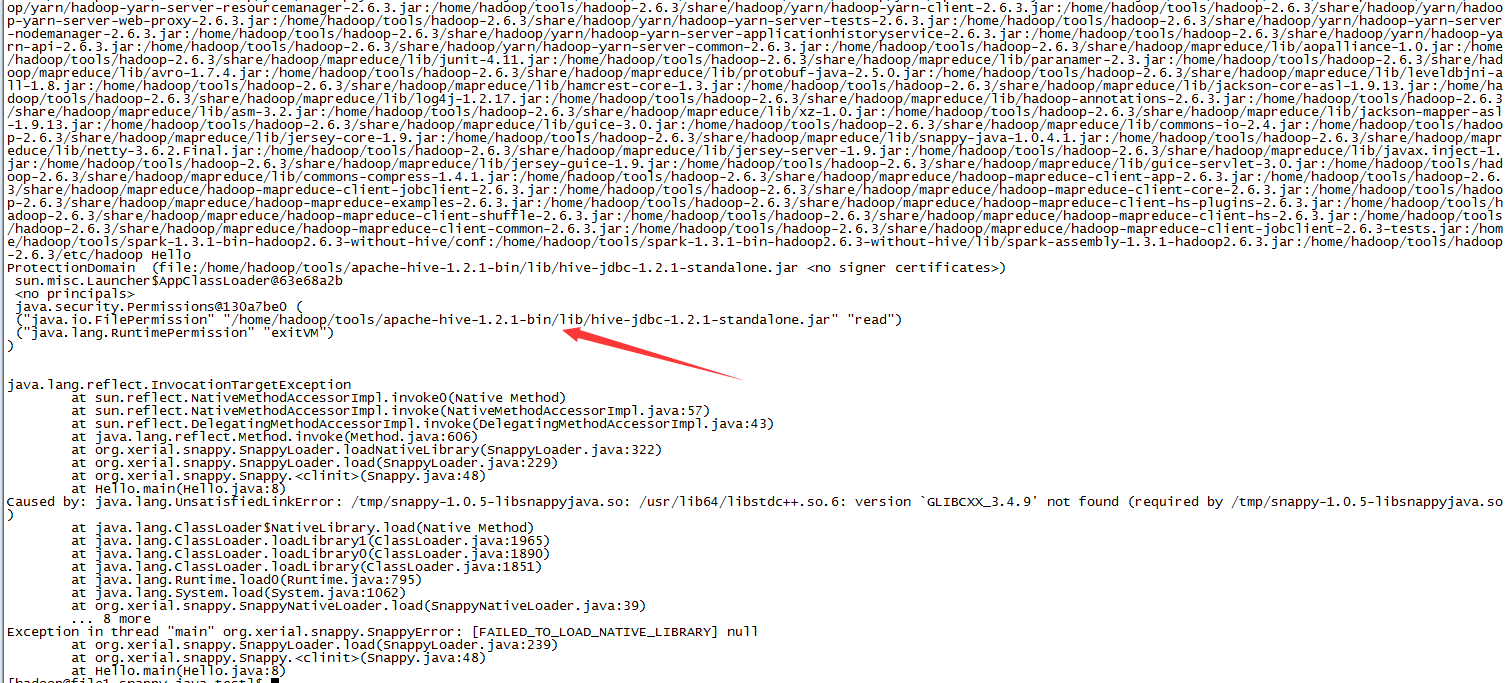
spark官网也没讲使用snappy需要做什么额外的配置(默认spark.io.compression.codec默认为snappy)。部署后设置 hive.execution.engine=spark 执行spark查询,立马就报错了 Caused by: java.lang.UnsatisfiedLinkError: /tmp/snappy-1.0.5-libsn
appyjava.so: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.9’ not found (required by /tmp/snappy-1.0.5-libsnappyjava.so) 从错误堆栈看与hadoop-native-snappy没关系,而是一个snappy-java的包。
- 16/04/12 20:20:08 INFO storage.BlockManagerMaster: Registered BlockManager
- java.lang.reflect.InvocationTargetException
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.xerial.snappy.SnappyLoader.loadNativeLibrary(SnappyLoader.java:322)
- at org.xerial.snappy.SnappyLoader.load(SnappyLoader.java:229)
- at org.xerial.snappy.Snappy.<clinit>(Snappy.java:48)
- at org.apache.spark.io.SnappyCompressionCodec.<init>(CompressionCodec.scala:150)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
- at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
- at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
- at org.apache.spark.io.CompressionCodec$.createCodec(CompressionCodec.scala:68)
- at org.apache.spark.io.CompressionCodec$.createCodec(CompressionCodec.scala:60)
- at org.apache.spark.scheduler.EventLoggingListener.<init>(EventLoggingListener.scala:67)
- at org.apache.spark.SparkContext.<init>(SparkContext.scala:400)
- at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:61)
- at org.apache.hive.spark.client.RemoteDriver.<init>(RemoteDriver.java:169)
- at org.apache.hive.spark.client.RemoteDriver.main(RemoteDriver.java:556)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:569)
- at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:166)
- at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:189)
- at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:110)
- at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
- Caused by: java.lang.UnsatisfiedLinkError: /tmp/snappy-1.0.5-libsnappyjava.so: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.9' not found (required by /tmp/snappy-1.0.5-libs
- at java.lang.ClassLoader$NativeLibrary.load(Native Method)
- at java.lang.ClassLoader.loadLibrary1(ClassLoader.java:1965)
- at java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1890)
- at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1851)
- at java.lang.Runtime.load0(Runtime.java:795)
- at java.lang.System.load(System.java:1062)
- at org.xerial.snappy.SnappyNativeLoader.load(SnappyNativeLoader.java:39)
- ... 28 more
[hadoop@file1 ~]$ hive
Logging initialized using configuration in file:/home/hadoop/tools/apache-hive-1.2.1-bin/conf/hive-log4j.properties
hive> set hive.execution.engine=spark;
hive> select count(*) from t_info where edate=20160411;
Query ID = hadoop_20160412205338_2c95c5fd-af50-42ba-8681-e154e4b74cb1
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Spark Job = 69afc030-fa1f-4fdf-81ef-12bdca411a4f
Query Hive on Spark job[0] stages:
0
1
Status: Running (Hive on Spark job[0])
Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount [StageCost]
2016-04-12 20:54:11,367 Stage-0_0: 0(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:14,421 Stage-0_0: 0(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:17,457 Stage-0_0: 0(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:19,486 Stage-0_0: 2(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:20,497 Stage-0_0: 3(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:21,509 Stage-0_0: 5(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:22,520 Stage-0_0: 6(+2)/234 Stage-1_0: 0/1
2016-04-12 20:54:23,532 Stage-0_0: 7(+2)/234 Stage-1_0: 0/1