如何高效的阅读hadoop源代码? 先看看这篇。
今天去广州图书馆办了证,借了几本关于大数据的书。老实说,国家提供的便民基础设施应该发挥她的价值,国家建那么多公共设施,还有很多人在后台让这些服务运作起来。借书是一种最高性价比学习的方式,第一:不能乱写乱画必须做笔记或者背下来,把最有价值的东西汇集;第二:有时间限制,好书逼着我们持续的去读;第三:自然是读到烂书也不用花钱,有价值的书必然也是最多人看的,看到翻的很旧的新书你就借了吧。
其中一个《Apache Spark源码剖析-徐鹏》,大致翻了一下,老实说作者很牛逼啊,从那么多的代码里面挑出和主题相关的,不比鸡蛋里面挑石头容易,跟着作者的思路去读应该不错。打算每天读点代码,同时把看书和看代码也记录下来,每天一小结,同时希望对别人有些参考作用。
Spark更新的很快,书本介绍的是 spark-1.0 ,不过书中介绍的主要是思路,我们这里选择比较新的版本 1.6.0 来读(生产用的是1.6)。
说到思路,如果你对Redis也感兴趣,强烈推荐读读 《Redis设计与实现-黄建宏》
使用环境说明
和作者不同,我选择直接在windows来读/调试代码,为了读个代码还得整一套linux的开发环境挺累的(原来也试过整linux开发环境后来放弃了),Windows 积累的经验已经可以让我自由调试和看代码了。
吐槽下sbt,很讨厌这玩意又慢还用ivy,我X,大数据不都用 maven 嘛,难道我还得为 spark 整一套完全一样的jar本地缓冲?不过还好 spark-1.6 已经是用 maven 来管理了。
- win10 + cygwin
- jdk8_x64(内存可以调到大于1G)
- maven3
- scala_2.10
- spark_1.6.0
- hive_1.2.1
- hadoop_2.6.3
- JetBrains idea 看代码确实不错
Spark开发环境搭建 - 对应书本的[附录A Spark源码调试]部分
配置 idea-scala
优化idea启动参数
安装 最新版idea (当前最新版本是15.0.5)。在程序安装的 bin 目录下,有x64配置文件 idea64.exe.vmoptions ,在配置文件开头添加jdk8内存配置:
-server
-Xms1g
-Xmx2g
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=256m
由于机器 eclipse 原来使用的 jdk_x86,为了兼容,单独编写 idea64.exe 的启动脚本 idea.bat :
set JAVA_HOME=D:\Java\jdk1.8.0_40
D:
cd "D:\Program Files\JetBrains\IntelliJ IDEA Community Edition 15.0.5\bin"
start idea64.exe"
exit
[IDEA的快键配置]:IDEA 适配 Eclipse 的快键集,通过 Settings -> Keymap -> Keymaps 配置。
安装scala插件
- 第一种方式:当然最好就是通过plugins的搜索框就能安装,但在中国这得看运气。
第二种方式:首先下载好插件,然后选择从硬盘安装插件。
从网络安装
打开 plugins 管理页面:(也可以通过 File -> Settings… -> Plugins 打开)
弹出的 Plugins 对话框显示了当前已经安装的插件:
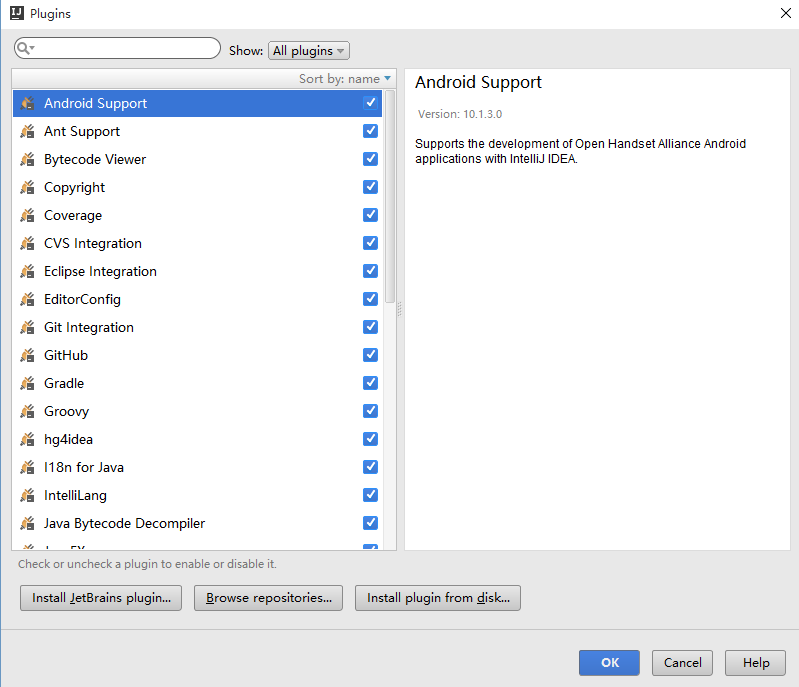
在 Plugins 对话框页面选择 [Browse repositories…] 按钮,再在弹出的对话框中查找 Scala 的插件:
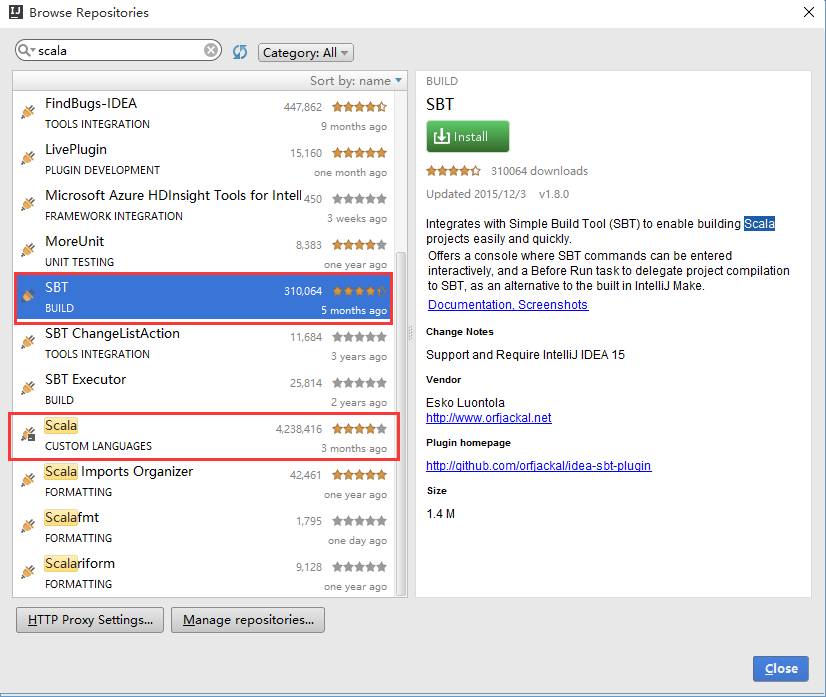
选择安装 Scala ,当然你也可以同时安装上 SBT 。
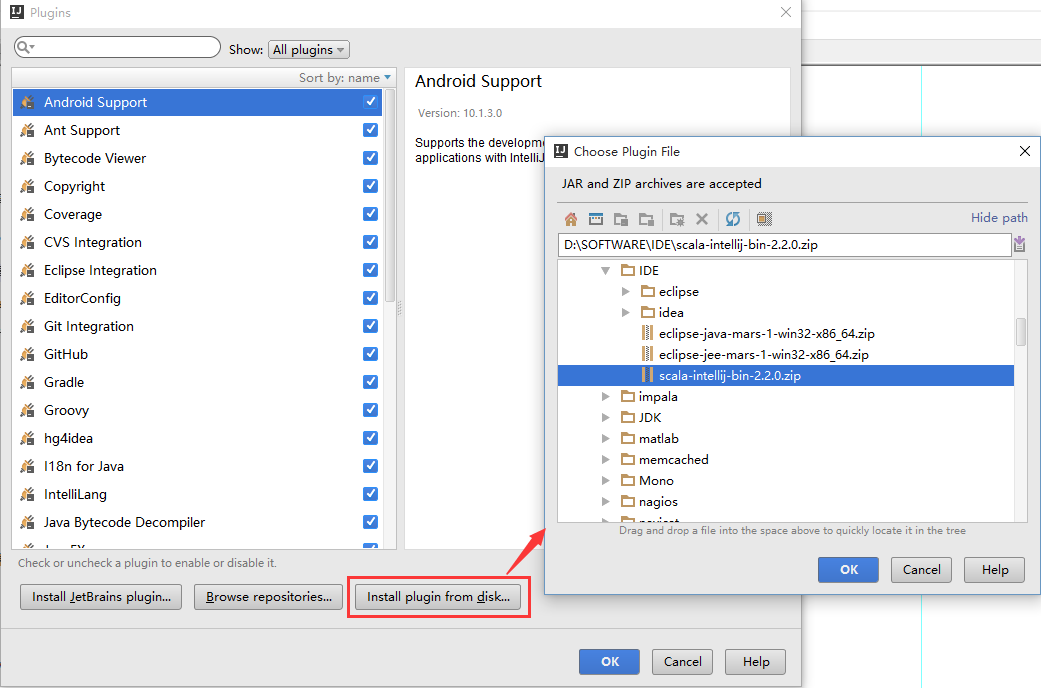
- 从硬盘安装
运气好就算可以直接从网络安装,但是下载过程其实也挺慢的。
我们还可以先自己下载好插件再安装(或者从其他同学获取、迅雷分分钟下完)。首先需要查看自己 idea 的版本,再在 https://plugins.jetbrains.com/?idea_ce 查找下载符合自己版本的 scala 插件,最后通过 [Install plugin from disk…] 安装,然后重启IDEA即可。
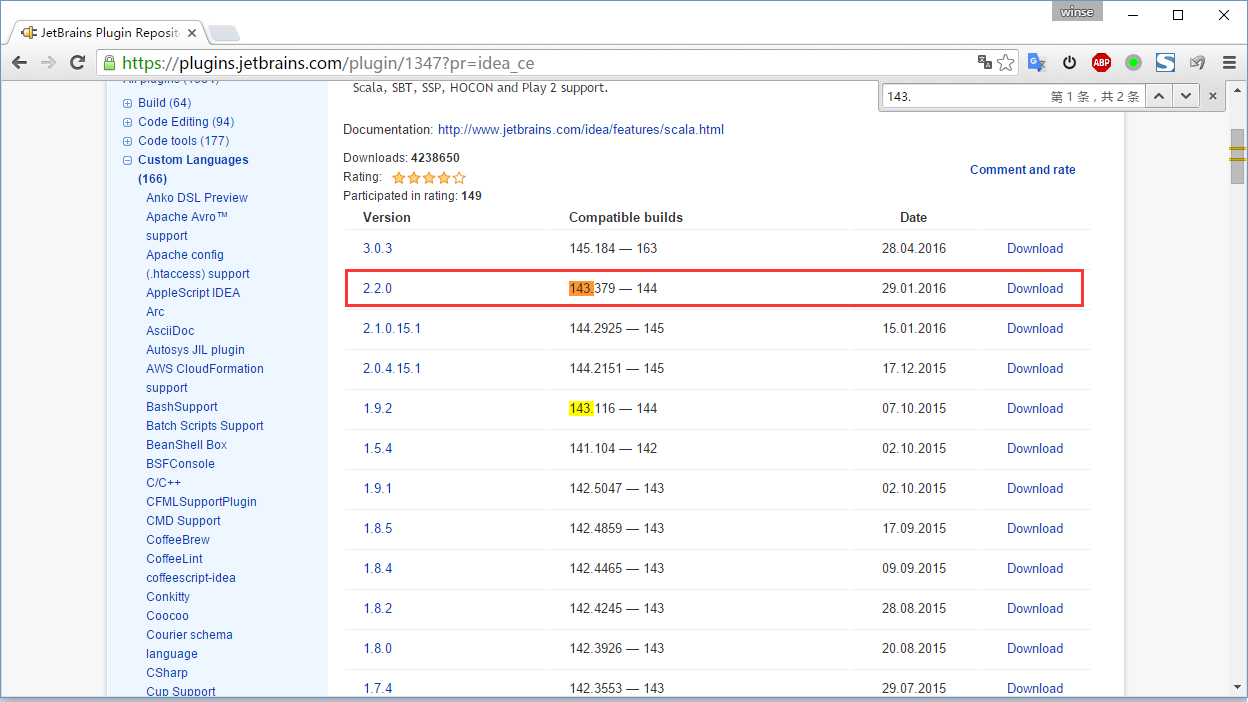
下载 spark 源码,并导入idea
- 下载源码,检出 1.6.0 版本
1 2 | |
如果你只想看 1.6.0 的内容,可以直接在clone命令添加参数指定版本:
$ git clone https://github.com/apache/spark.git -b v1.6.0
- 导入idea
导入之前先要生成arvo的java类(这里直接package编译一下):
E:\git\spark\external\flume-sink>mvn package -DskipTests
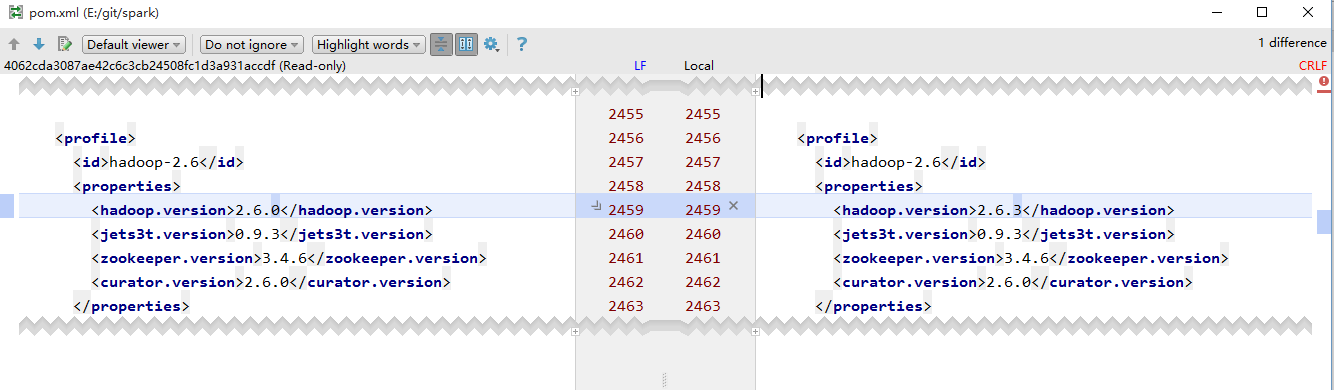
由于我使用 hadoop-2.6.3 ,并且导入过程中不能修改环境变量,直接修改 pom.xml 里面 hadoop.version 属性的值。
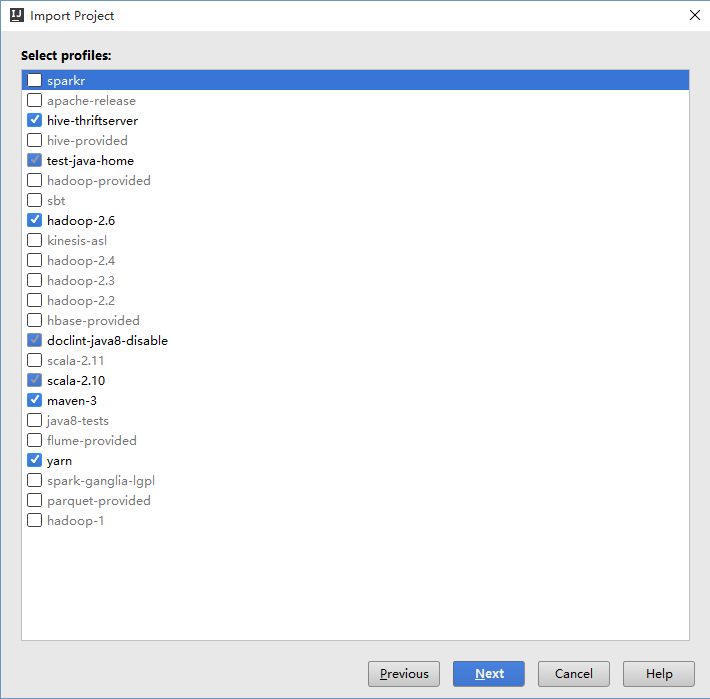
启动IDEA,使用 [Import Project] 导入源代码; 然后选择 E:/git/spark(刚刚下载的源码位置); 然后选择导入maven项目; 在 profile 页把必要的都选上(当然也可以后期通过 Maven Projects 面板来修改):
导入完成后,依赖关系maven已经处理好了,直接就能用了。也可以 Make Projects 再编译一次,并把运行application的make去掉,免得浪费编译时间)。
注意:mvn idea:idea 其实不咋的,生成的配置不兼容。最好不要用!!
- 调试/测试
在调试运行之前,先了解下并解决 idea maven-provided 的问题:
在idea里面直接运行 src/main/java 下面的类会被当做在生产环境运行,所以idea不会把这些 provided的依赖 加入到运行的classpath。
- https://youtrack.jetbrains.com/issue/IDEA-54595
- http://stackoverflow.com/questions/30453269/maven-provided-dependency-will-cause-noclassdeffounderror-in-intellij
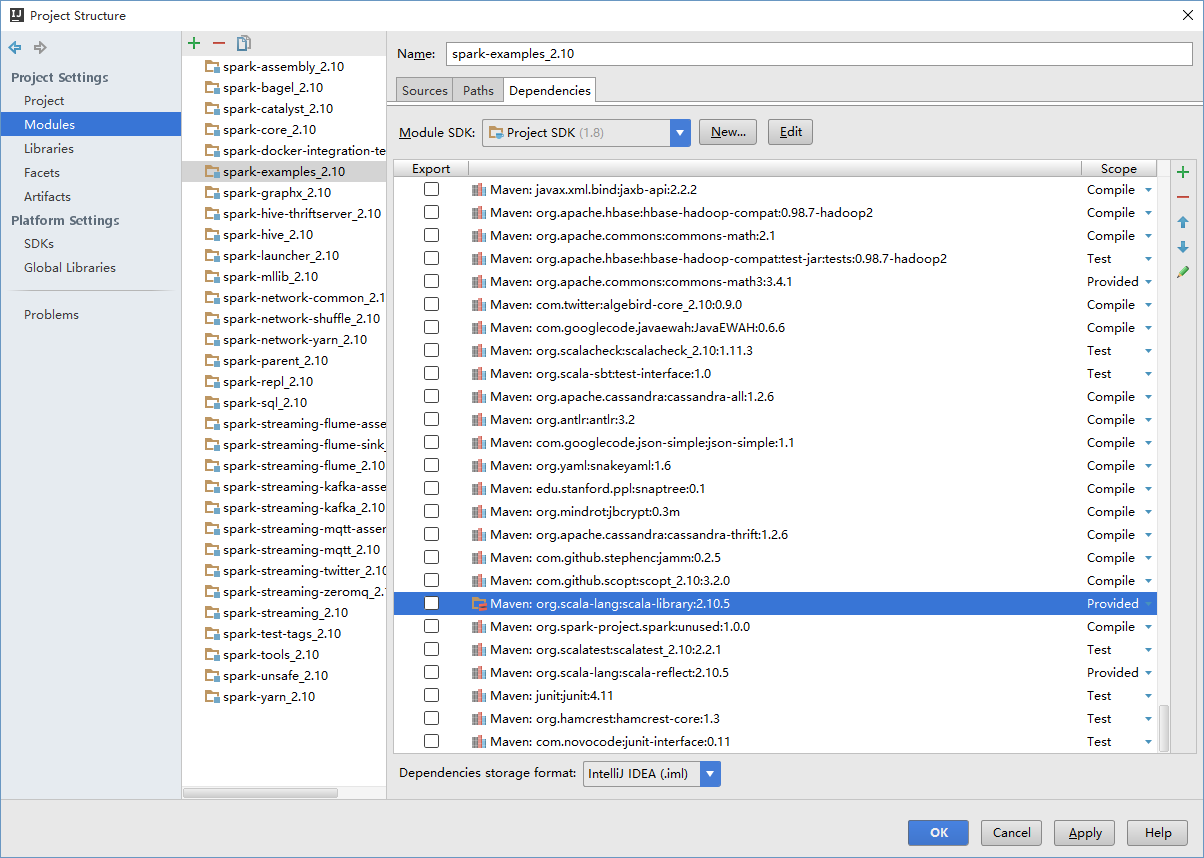
IDEA运行时是从 examples/spark-examples_2.10.iml 文件中读取classpath的配置,所以我们直接把 spark-examples_2.10.iml 的 scope="PROVIDED" 全部删掉即可。
1 2 3 | |
首先右键 [Run LogQuery] 运行(由于缺少master的配置会报错的),主要用于生成启动的 LogQuery Configuration:
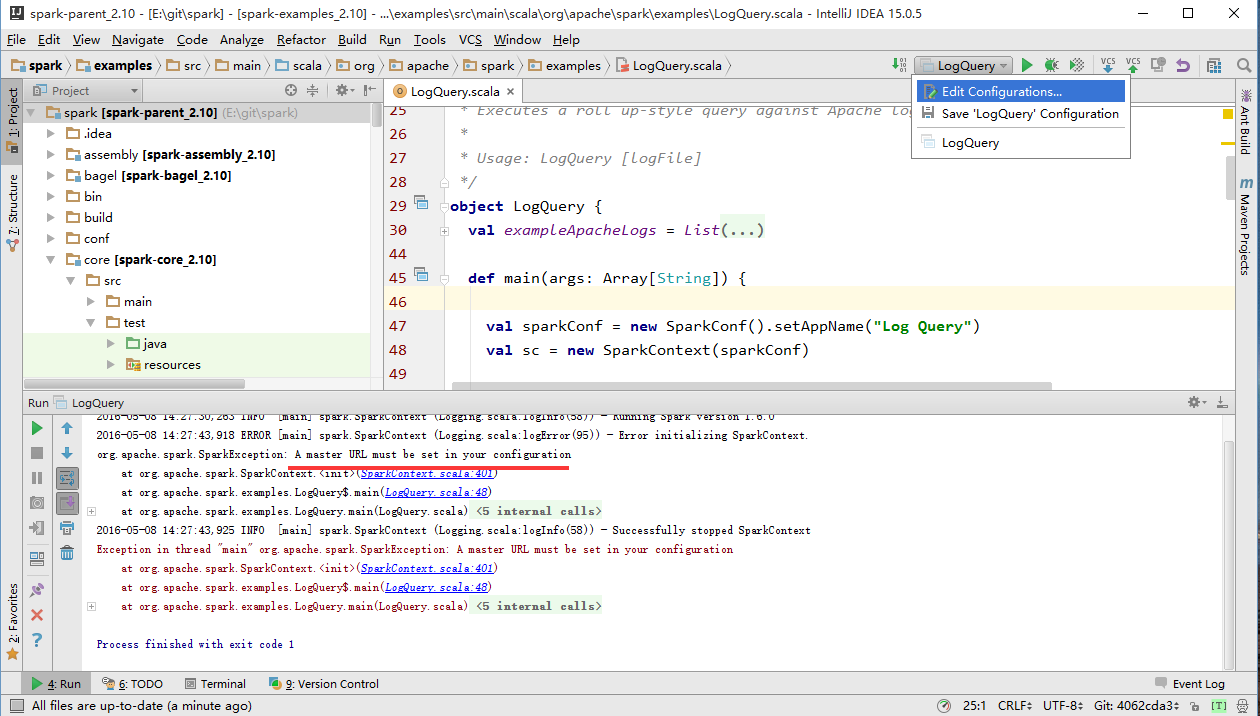
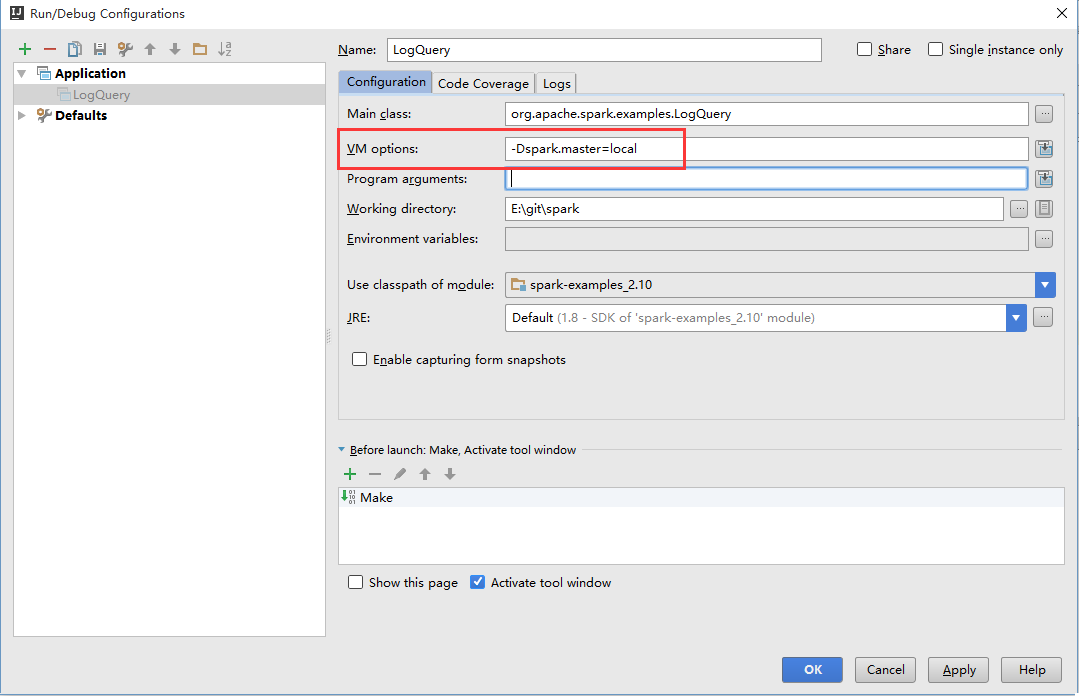
然后选择上图中下拉选项的 [Edit Configurations…] ,在弹出配置对话框为中为 LogQuery 添加 VM options 配置: -Dspark.master=local ,接下来我们就可以打断点,Debug调试了。
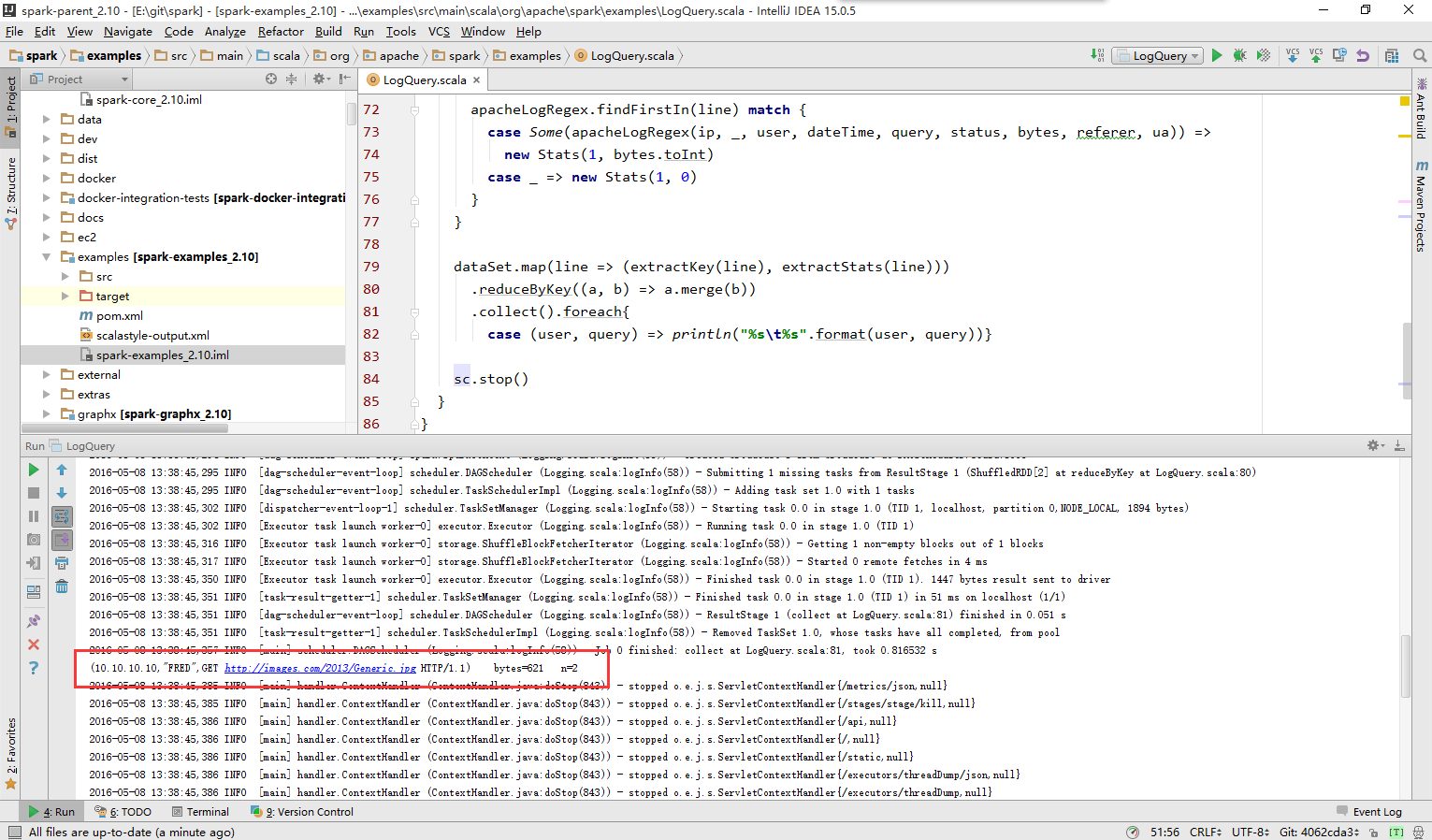
运行结果如下:
遇到IDEA导入maven依赖有问题的,可以参考下 Import Maven dependencies in IntelliJ IDEA 。
–END