本来第二篇应该是与 [第1章 初识Spark] 有关,但我们运行helloworld、以及提交任务都是通过脚本 bin/spark-shell ,完全不知道那些脚本是干啥的?而且,在开发环境运行shell来启动应用总觉得怪怪的,这篇先来简单了解脚本的功能、以及Launcher模块。
其实每个大数据的框架,shell脚本都是通用入口,也是研读源码的第一个突破口 。掌握脚本功能相当于熟悉了基本的API功能,把 spark/bin 目录下面的脚本理清楚,然后再去写搭建开发环境、编写调试helloworld就事半功倍了。
官网 Quick Start 提供的简短例子都是通过 bin/spark-shell 来运行的。Submit页面提供了 bin/spark-submit 提交jar发布任务的方式。 spark-shell,spark-submit 就是两个非常重要的脚本,这里就来看下这两个脚本。
spark-shell - 对应[3.1 spark-shell]章节
spark-shell 脚本的内容相对多一些,主要代码如下(其他代码都是为了兼容cygwin弄的,我们这里不关注):
1 2 3 4 5 | |
最终调用 bin/spark-submit 脚本。其实和我们自己提交 helloworld.jar 命令一样:
1 2 3 4 | |
不过通过 bin/spark-shell 提交运行的类是spark自带,没有附加(不需要)额外的jar。这个后面再讲,我们也可以通过这种方式类运行公共位置的jar,可以减少一些不必要的网络带宽。
spark-submit
submit脚本更简单。就是把 org.apache.spark.deploy.SparkSubmit 和 输入参数 全部传递给脚本 bin/spark-class 。
1
| |
spark-class
主要的功能都集中在 bin/spark-class。bin/spark-class脚本最终启动java、调用 Launcher模块 。而 Launcher模块 解析输入参数并输出 最终输出Driver启动的命令,然后shell再通过 exec 来运行Driver程序。
要讲清楚 bin/spark-class 相对复杂点:通过脚本传递参数,调用java处理参数,又输出脚本,最后运行脚本才真正运行了Driver。所以这里通过 脚本 和 程序 来进行说明。
脚本
- 先加载环境变量配置文件
- 再获取 assembly.jar 位置
- 然后调用
org.apache.spark.launcher.Main, Main类根据环境变量和传入参数算出真正执行的命令(具体在【程序】部分讲)。
下面是核心脚本的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
大部分内容都是准备环境变量,就最后几行代码比较复杂。这里设置DEBUG在脚本 while 循环打印每个输出的值看下输出的是什么。
1 2 3 4 5 6 7 8 | |
启动 bin/spark-shell(最终会调用 bin/spark-class,上面已经讲过脚本之间的关系),查看输出的调试信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
从上面的调试信息可以看出:
org.apache.spark.launcher.Main把传入参数整理后重新输出- 脚本把java输出内容保存到
CMD[@]数组中 - 最后使用exec来执行。
根据上面 bin/spark-class 产生的启动命令可以直接在idea里面运行,效果与直接运行 bin/spark-shell 一样:
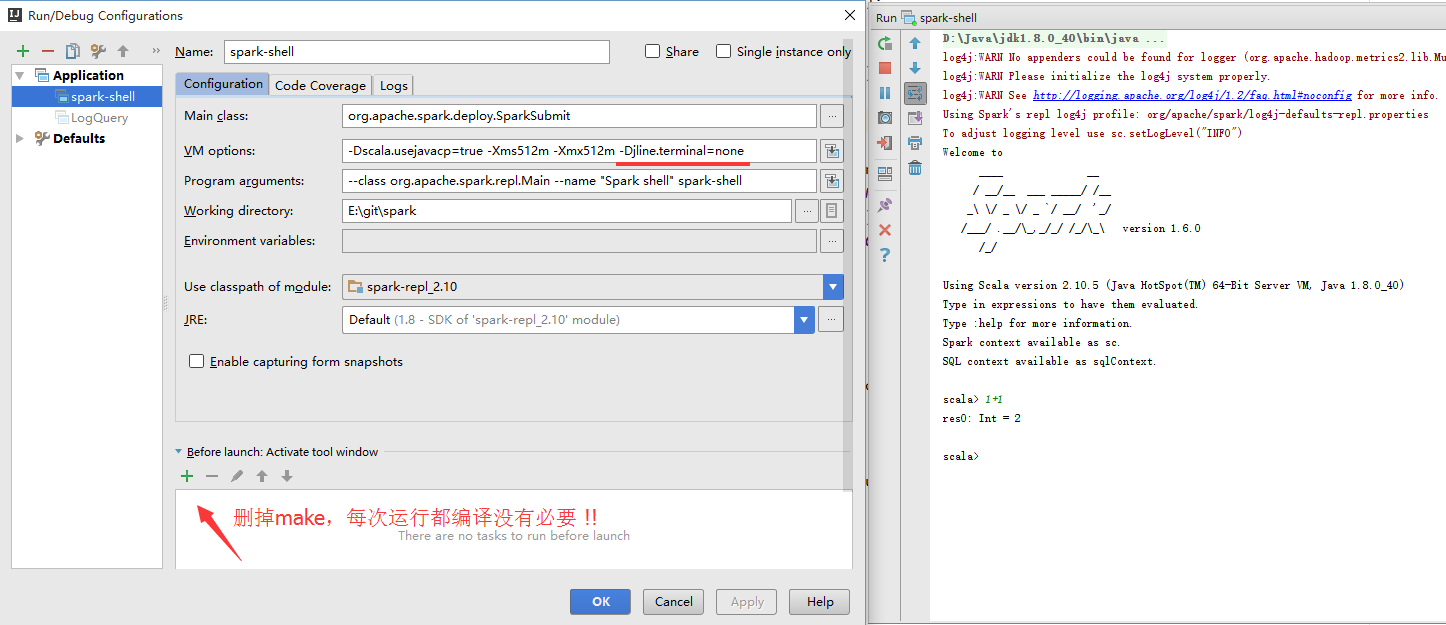
注意: 这里的 spark-shell 是一个特殊的字符串,代码中会对其进行特殊处理不额外加载jar。类似的字符串还有: pyspark-shell, sparkr-shell, spark-internal(参看SparkSubmit),如果调用类就在SPARK_CLASSPATH可以使用它们减少不必要的网络传输。
Launcher模块
发现 shell 和 launcher的java代码 功能逻辑非常类似。比如说获取java程序路径的代码:
1 2 3 4 5 6 7 8 9 10 11 | |
在shell脚本里面的处理是:
1 2 3 4 5 6 7 8 9 10 11 | |
对比两者,其实是用脚本更加直观。但是使用java编写一个模块更便于管理和扩展,稍微调整下就能复用代码。比如说要添加windows的cmd脚本、又或者为了兼容多个操作系统/多语言(python,r 等)。所以提取一个公共的 Launcher模块 出来其实是个挺不错的选择。同时对于不是很熟悉shell的程序员来说也更方便了解系统运作。
Launcher模块 按功能可以分为 CommandBuilder 和 SparkLauncher 两个部分。
CommandBuilder
SparkSubmitCommandBuilder: 解析用户输入的参数并输出命令给脚本使用
- SparkClassCommandBuilder: 主要为后台进程产生启动命令(sbin目录下面的脚本)。
1.1 公共类
- Main : 统一入口
- AbstractCommandBuilder : 提供构造命令的公共基类
- buildJavaCommand
- buildClassPath
- SPARK_CLASSPATH
- extraClassPath
- getConfDir : 等于环境变量 $SPARK_CONF_DIR 或者 $SPARK_HOME/conf 的值
- classes
- SPARK_PREPEND_CLASSES
- SPARK_TESTING
- findAssembly : 获取 spark-assembly-1.6.0-hadoop2.6.3.jar 的路径,lib 或者 assembly/target/scala-$SPARK_SCALA_VERSION 路径下
- _SPARK_ASSEMBLY
- datanucleus-* : 从 lib / lib_managed/jars 目录下获取
- HADOOP_CONF_DIR
- YARN_CONF_DIR
- SPARK_DIST_CLASSPATH
- buildClassPath
- getEffectiveConfig : 获取 spark-defaults.conf 的内容
- buildJavaCommand
1.2 SparkSubmitCommandBuilder
主要的类以及参数:
- SparkSubmitCommandBuilder
- 构造函数调用OptionParser解析参数,解析handle有处理specialClasses!
- buildSparkSubmitCommand
- getEffectiveConfig
- extraClassPath : spark.driver.extraClassPath
- SPARK_SUBMIT_OPTS
- SPARK_JAVA_OPTS
- client模式下加载配置
- spark.driver.memory / SPARK_DRIVER_MEMORY / SPARK_MEM / DEFAULT_MEM(1g)
- DRIVER_EXTRA_JAVA_OPTIONS
- DRIVER_EXTRA_LIBRARY_PATH
- buildSparkSubmitArgs
- SparkSubmitOptionParser(子类需要实现handle方法)
- SparkSubmitCommandBuilder$OptionParser 命令参数
bin/spark-submit -h查看可以设置的参数- 直接查看官网文档
1.3 SparkClassCommandBuilder
主要CommandBuilder的功能上面已经都覆盖了,SparkClassCommandBuilder主要关注命令行可以设置哪些环境变量:
- org.apache.spark.deploy.master.Master
- SPARK_DAEMON_JAVA_OPTS
- SPARK_MASTER_OPTS
- SPARK_DAEMON_MEMORY
- org.apache.spark.deploy.worker.Worker
- SPARK_DAEMON_JAVA_OPTS
- SPARK_WORKER_OPTS
- SPARK_DAEMON_MEMORY
- org.apache.spark.deploy.history.HistoryServer
- SPARK_DAEMON_JAVA_OPTS
- SPARK_HISTORY_OPTS
- SPARK_DAEMON_MEMORY
- org.apache.spark.executor.CoarseGrainedExecutorBackend
- SPARK_JAVA_OPTS
- SPARK_EXECUTOR_OPTS
- SPARK_EXECUTOR_MEMORY
- org.apache.spark.executor.MesosExecutorBackend
- SPARK_EXECUTOR_OPTS
- SPARK_EXECUTOR_MEMORY
- org.apache.spark.deploy.ExternalShuffleService / org.apache.spark.deploy.mesos.MesosExternalShuffleService
- SPARK_DAEMON_JAVA_OPTS
- SPARK_SHUFFLE_OPTS
- SPARK_DAEMON_MEMORY
- org.apache.spark.tools.
- extraClassPath : spark-tools_.*.jar
- SPARK_JAVA_OPTS
- DEFAULT_MEM(1g)
- other
- SPARK_JAVA_OPTS
- SPARK_DRIVER_MEMORY
SparkLauncher
SparkLauncher提供了在程序中提交任务的方式。通过Driver端的支持获取程序执行动态(通过socket与Driver交互),为实现后端管理应用提供一种可行的方式。
SparkLauncher提交任务其中一部分还是使用spark-submit脚本,绕一圈又回到上面的参数解析生成命令然后exec执行。另外SparkLauncher通过启动 SocketServer(LauncherServer)接收来自Driver(LauncherBackend)任务执行情况的最新状态。
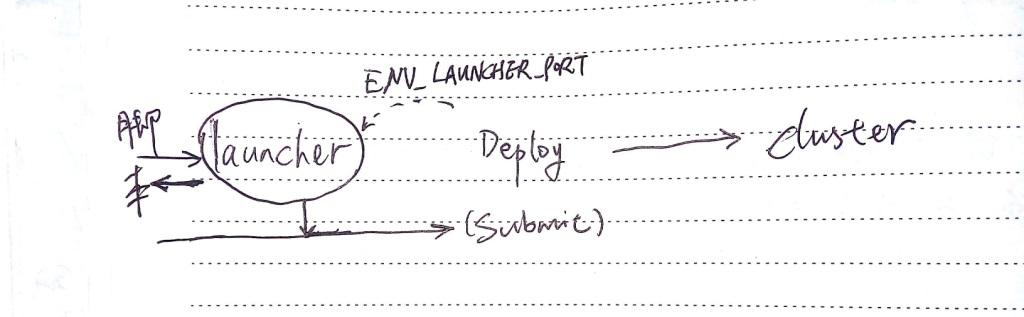
代码包括:
- SparkLauncher 主要是startApplication。其他都是解析设置参数,相当于把shell的工作用java重写了一遍
- LauncherServer 服务SocketServer类
- LauncherServer$ServerConnection 状态处理类
- LauncherConnection 通信基类:接收、发送消息
- LauncherProtocol 通信协议
- ChildProcAppHandle : SparkAppHandle 接收到Driver的状态后,请求分发类
具体功能的流转请下载代码 HelloWorldLauncher.scala ,然后本地调试一步步的追踪学习。
–END