Article
深入剖析Carota源码:从问题出发
本来早些时刻已经下载了新的 canvas-editor 源代码,想通过对比更快的了解代码整体框架,但还没过一月,发现已经把 Carota 忘的差不多了。
为了加深记忆,决定再把Carota梳理一遍,写一篇 Carota 回忆总结,本文从开发环境搭建,将通过一下几个核心问题,逐层梳理Carota的整体框架:
1、数据修改后,如何一步步反映到最后界面上?
2、编辑器的html元素是如何建构的?
3、光标是如何实现的?
4、增量更新,怎么更新渲染?
环境搭建
首先,我们需要搭建一个可调试的开发环境。将源码下载到本地:https://gitcode.com/winseII/carota-ts ,这是我基于原版 https://github.com/danielearwicker/carota 改写的 Typescript + Webpack 版本,有了类型系统,可以让阅读代码更方便一些。
开发环境搭建非常简单,只需三步:
1、安装 Nodejs 20+,然后安装 yarn。
2、运行 yarn,下载项目的依赖。
3、运行 yarn dev 启动,打开浏览器查看。
接下来,为了方便调试和查看源码,在 VS Code 中配置调试器,主要是调试的时刻也可以在代码之间来回导航。
1、新建一个 Web App 调试配置,应用端口就是8080,全部默认即可。
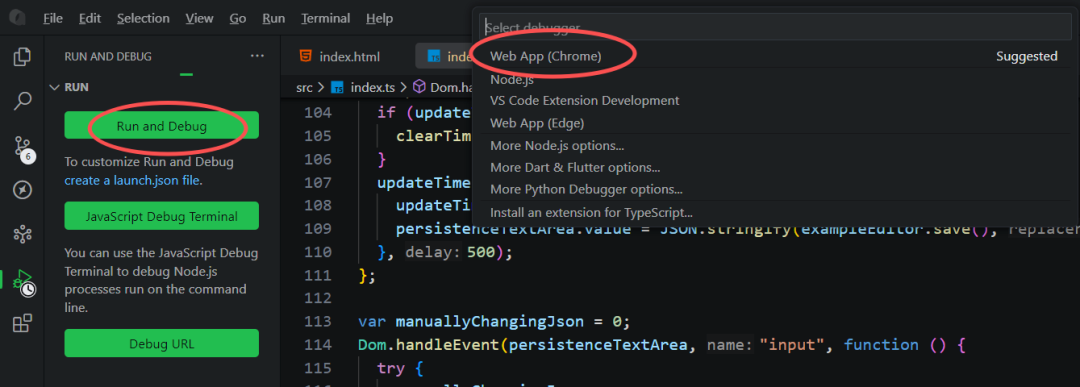
2、点击左侧面板的绿色播放按钮,会自动打开浏览器访问 localhost:8080。
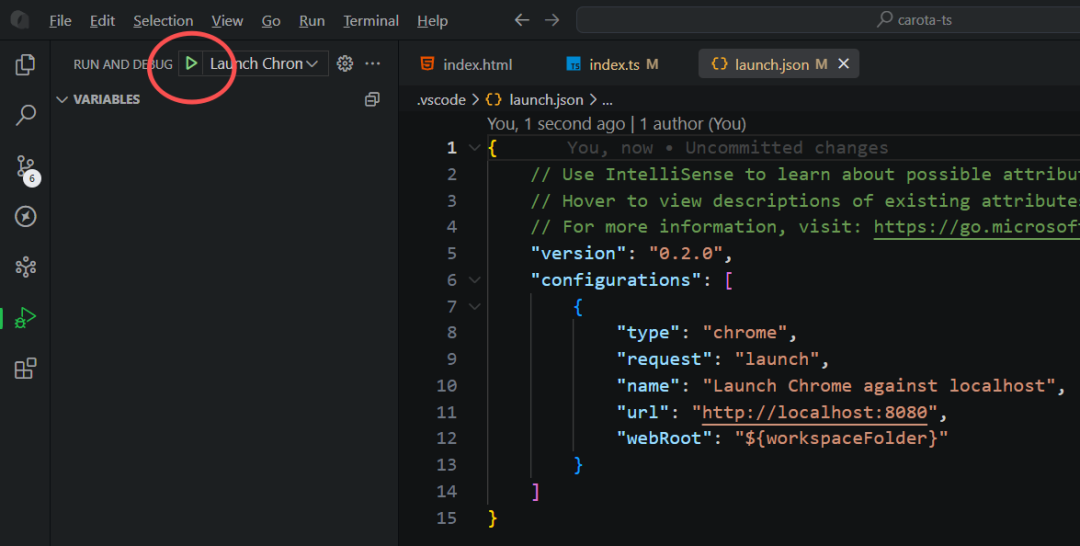
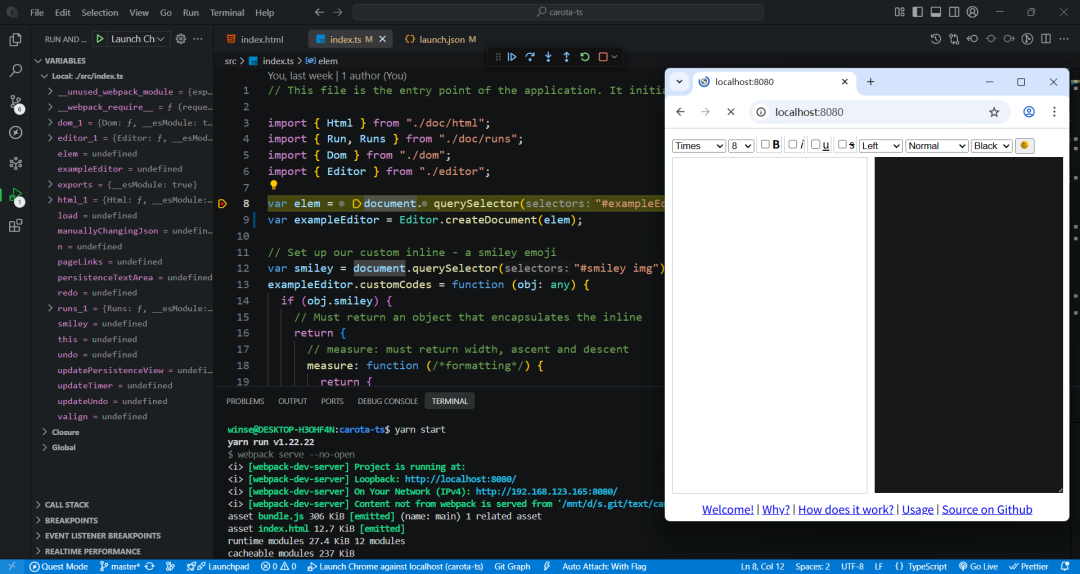
3、在 index.ts 源码设置断点,然后刷新页面就可以进到断点,开始调试了。
问一:修改 Run 数据后,如何渲染到界面?
子问题:
1、Run 为编辑器的核心数据结构,它如何定义文本和样式?如何序列化保存,又如何反序列化为内存中的数据结构去使用的?
2、当用户输入、删除或修改样式时,它是如何更新保存的?
3、布局时,依据哪些条件(如 Word 宽度、画布宽度)来判断断行的?保存了哪些关键信息(如 y 坐标、baseline、行高)以支持渲染?
4、渲染时,如何只绘制可视区域?
5、如何应用 Run 的格式(字体、颜色等)的来绘制文字的?
要弄清这些问题,首先要找出用户输入事件的入口,然后再逐步的跟踪代码。
1、寻找输入事件入口
在不太熟悉代码 的情况下,浏览器自带的开发者工具是我们的得力助手。
1)选择文本框元素。
2)在开发者工具面板的 Event Listeners 页签中,找到我们关心的 input 事件。
3)点击右边的文件链接,定位到监听器的代码。
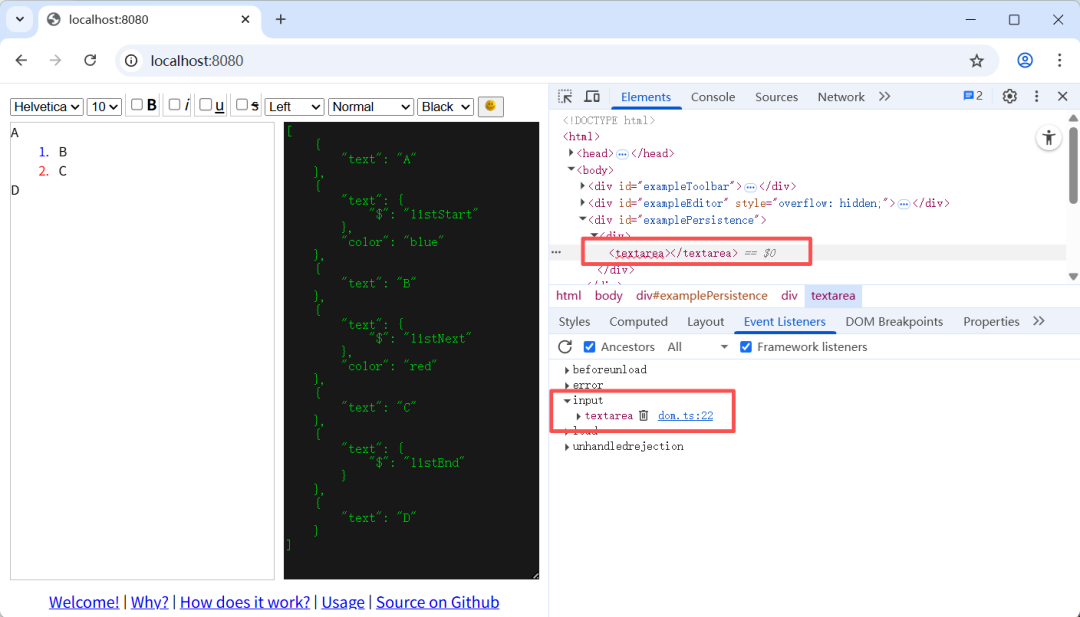
打开代码后,这是一个通用的事件注册方法。为了找到实际调用的代码,我们加个条件断点:只在我们关心的 input 事件进来才停下来。
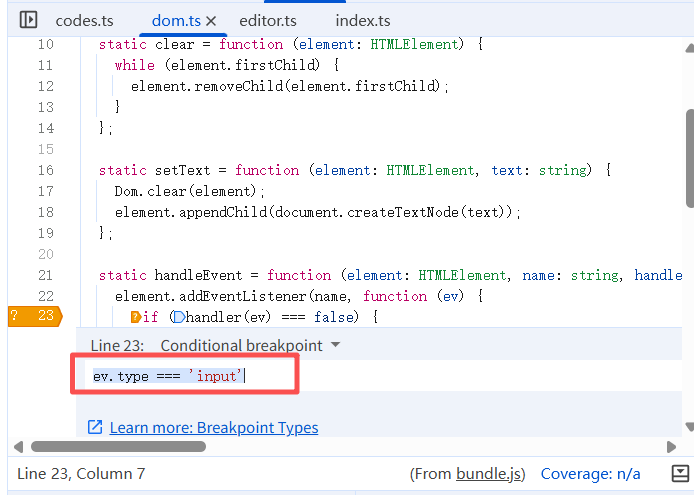
在文本框中输入一个字符,触发输入事件:
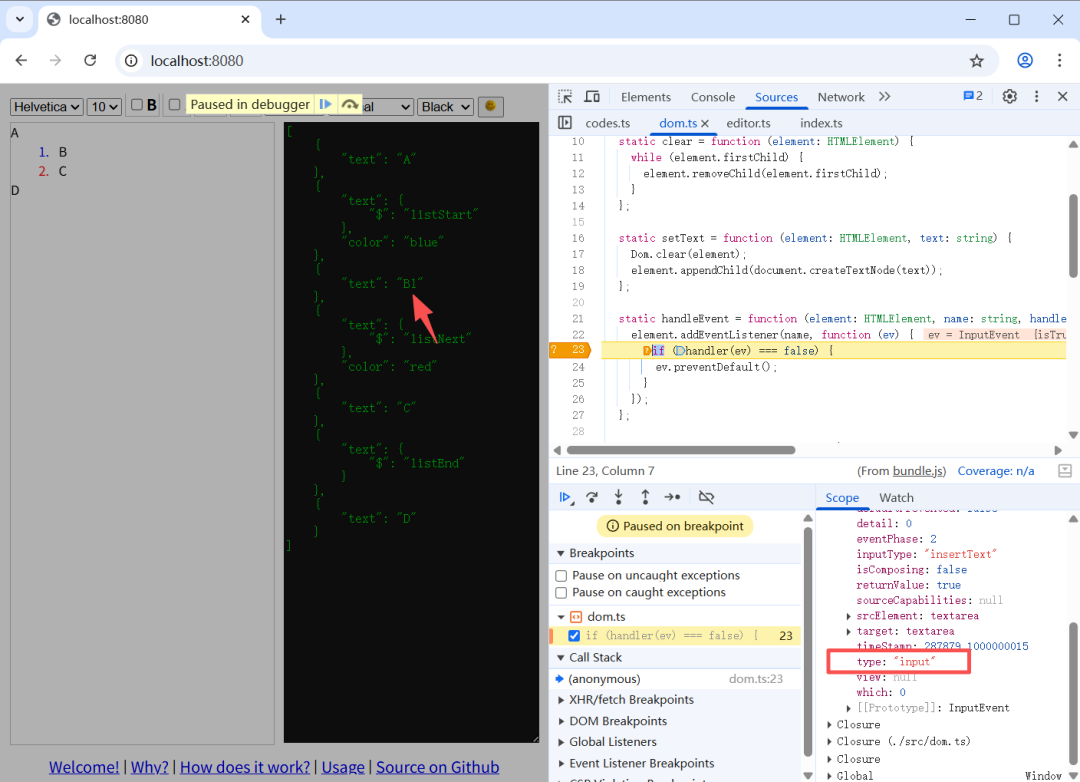
然后就会进到条件断点,我们再按 F11 单步跟进去,跳转到 handler 实际处理代码的位置。
在不熟悉代码的情况,最好的方式就是,通过运行时,沿着调用链跟踪代码来找到事件入口。这样能快速的定位到目标。
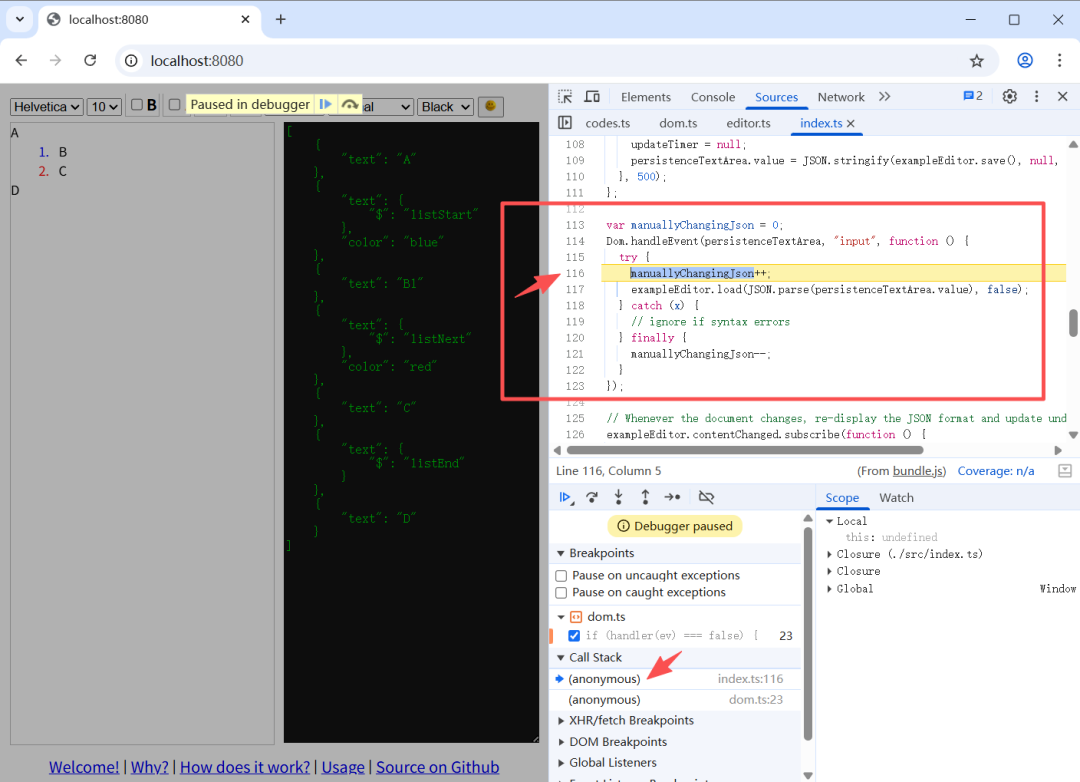
当然,如果熟悉 代码,也可以直接通过事件名 input,结合 html 元素快速的定位到输入事件的处理代码。
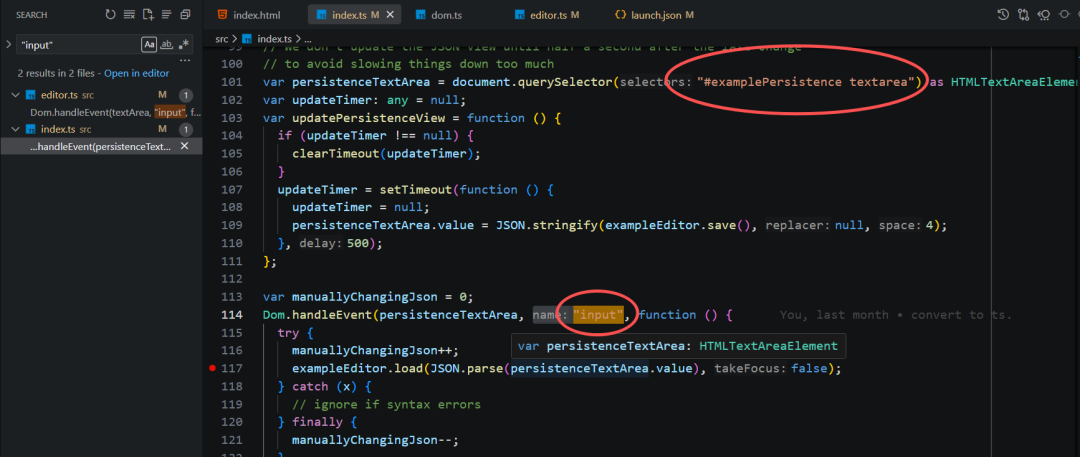
2、数据加载和解析
进入事件后,调用 load 方法加载和转换 文本框的 Run 数据。
按 F5 单步调试进入。(VS Code有各种的 IDE 编辑器快捷键插件,选择一个你熟悉的快键,我这里用的是Eclipse Keymap。)
load 方法涉及了编辑器的核心:包括了数据加载、布局、内容和选区事件的处理。
如果逐个方法深入阅读,很容易迷失其中。在不是主线的代码,我们可以先通过变量名、方法名了解其作用点到为止,或者选择代码块按 Ctrl+L 让AI帮我们解释它的作用。
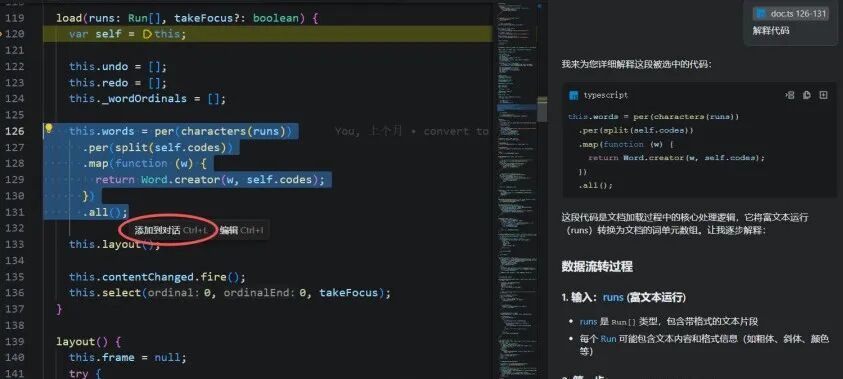
上图中选中代码块作用是:Carota 将存储数据 Run 数组转换为单词 Word 数组。

不要奢望一遍就理解就懂所有代码,做好准备看多次、看多遍,在这样的心态下,就不会偏执、不会去钻牛角尖,做到有的放失。后面真正需要用到的时候,再研究具体的代码。
需要注意的是,Carota大量使用了 emit 函数和 callback 回调的方式,这是一种基于事件的、逆向追溯的编程范式。逆着往回溯的方式,看着难受和别扭。
如果更习惯同步的数据流,我们用Dart的Stream来改写,按顺序的数据流向就容易去理解了。

3、理解Word对象
要理解后续的布局,必须先弄懂 Word 的结构。Run 是带格式的片段,实现方便的存储,而Word 则承上启下,是布局的基础,是编辑器的另一核心元素。
split 方法计算得到单词的开始字符、空格开始字符和下一个单词的开始字符,即单词和空格的边界,用来生成 Word。
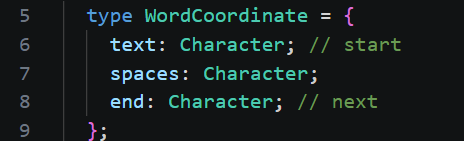
Word 对象包含两部分:text 和 space。每部分由一个或多个由 TextRun 测量后的 Box 对象构成。多个 Box 聚合汇总形成了 Group 对象、总高度、ascent、descent等信息。如下图的结构:
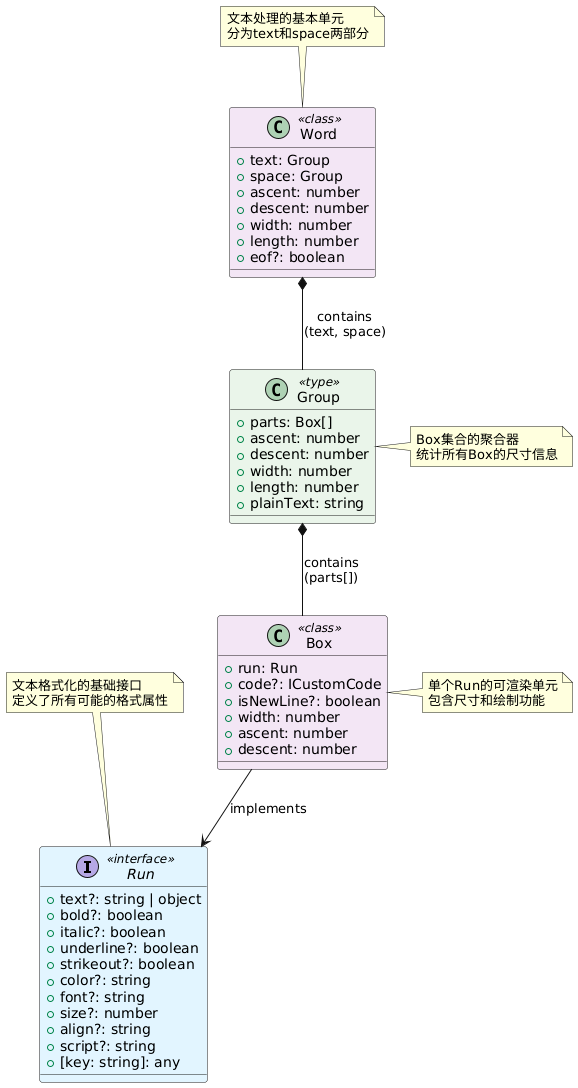
理解了 Word 是由连续字符和空格组成,是理解换行、对齐等复杂布局的前提。
4、布局
把数据解析为 Word 数组后,下一步就是进行布局 layout。
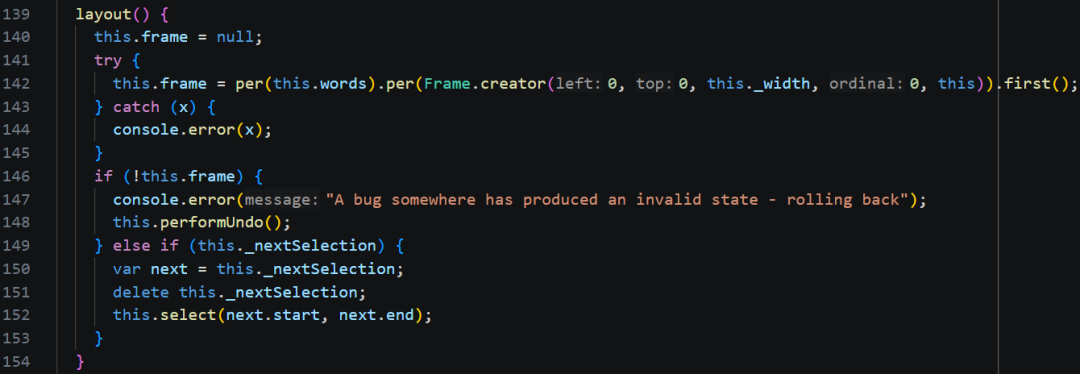
Frame 对象可以理解为文档中的一个块 。构造函数参数为:块在屏幕坐标 (0, 0) 开始,文档索引从 0 开始,它的父节点是 doc。
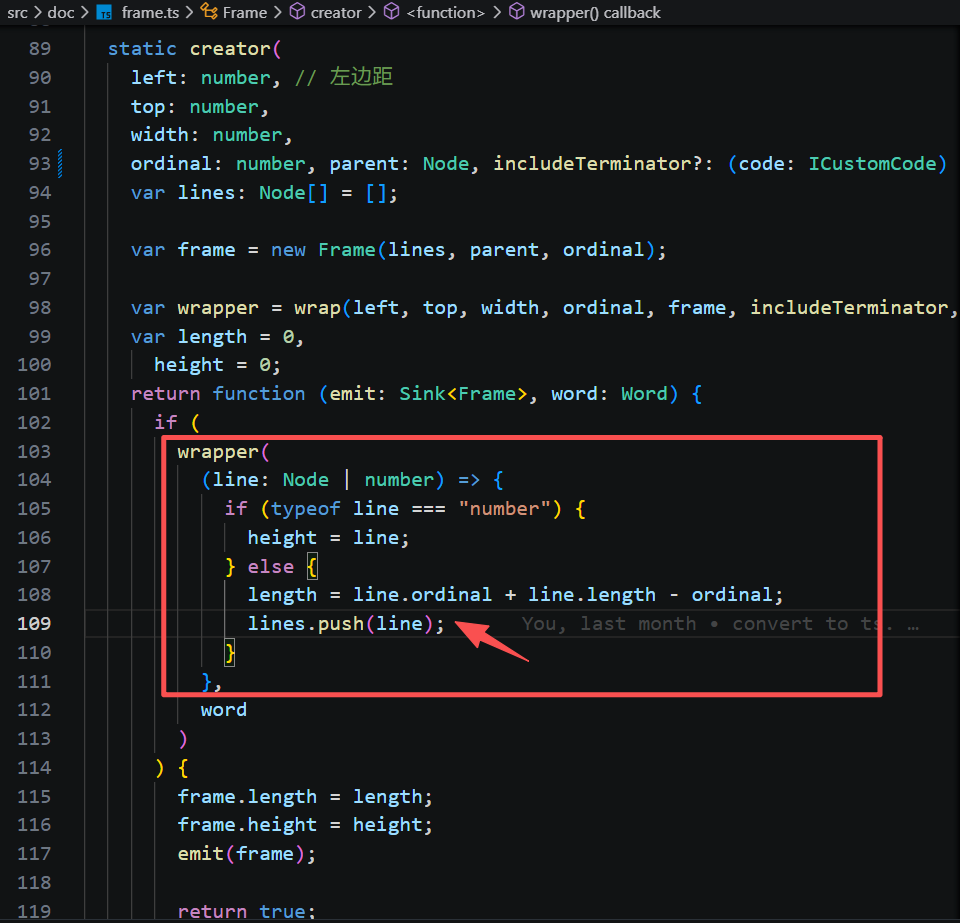
处理传入的 Word,调用 store 不断累加它们的宽度,当宽度大于编辑器宽度width后、或者遇到单词是换行符时,就会调用 send 触发断行操作。创建新的行,保存了行的宽度、基线、行高、起始索引等信息;
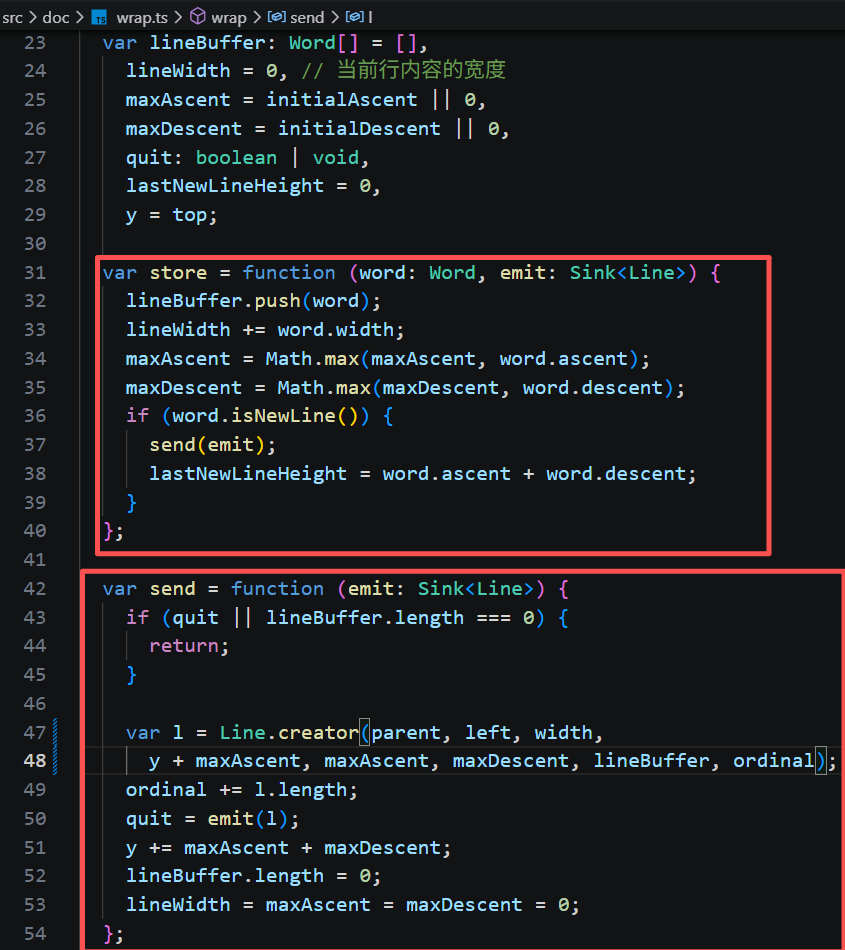
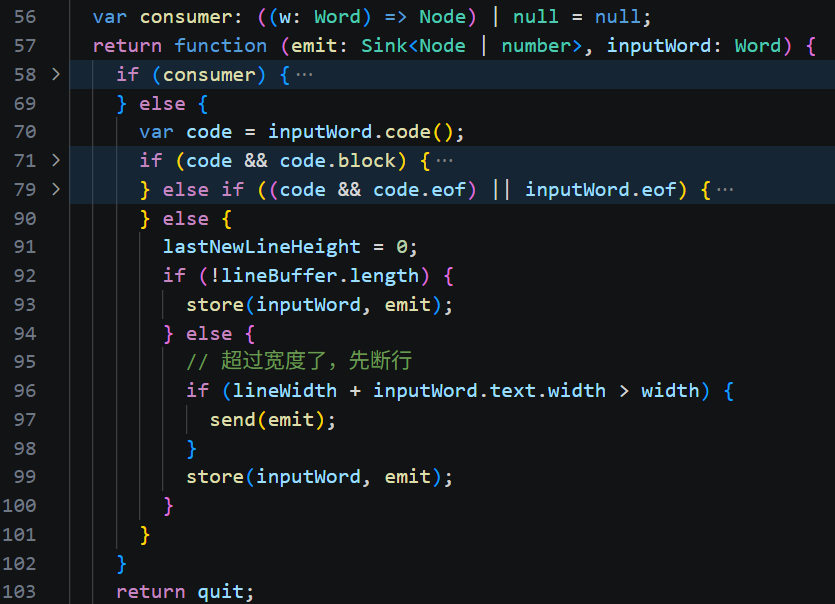
然后,新的 Line 被保存到 Frame 的 lines 数组中。
最终遇到结束符 eof,整个文档结构树就构建完成了。
5、渲染重绘
在模型和布局完成后,就进入渲染了。通过内容事件 contentChanged 和选区事件 selectionChanged 来触发 paint 重新渲染。
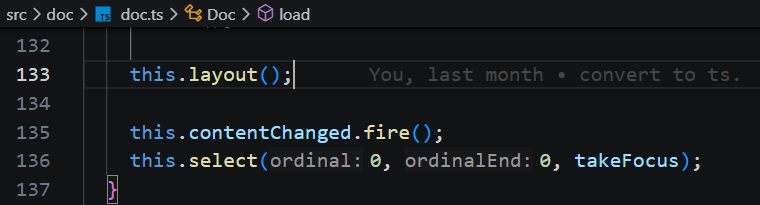
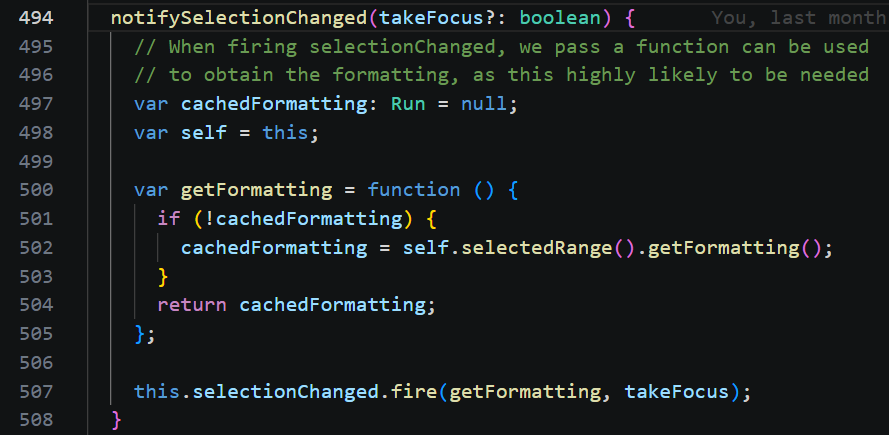
通过全局查找 selectionChanged。
在 editor 创建文档 createDocument 时,监听了选区变化事件。当选中区域发生变化时,编辑器会调用 paint 方法进行重新渲染。
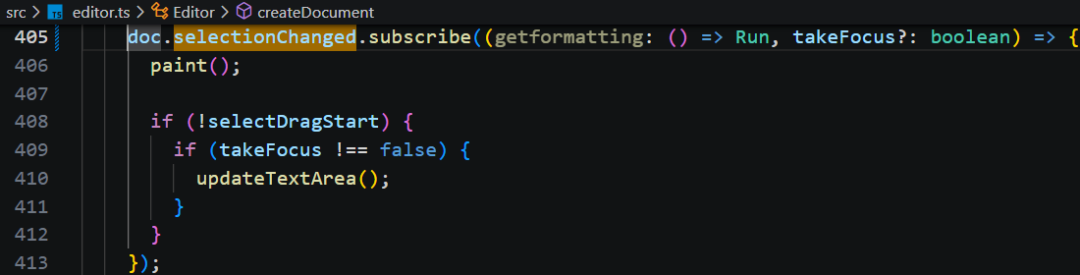
在 paint 方法中,[1]重新计算画布的宽高,画布 Canvas 高度只等于可见区域高度clientHeight,而整个文档内容的高度则由外面包裹的 spacer 元素来处理。[2]同时处理好DPR:设置canvas html元素的宽高,同时canvas 绘图对象也要进行等比例的缩放。[3]把画布 canvas 移动到视口,调用 document 的 draw 和 drawSelection 方法。
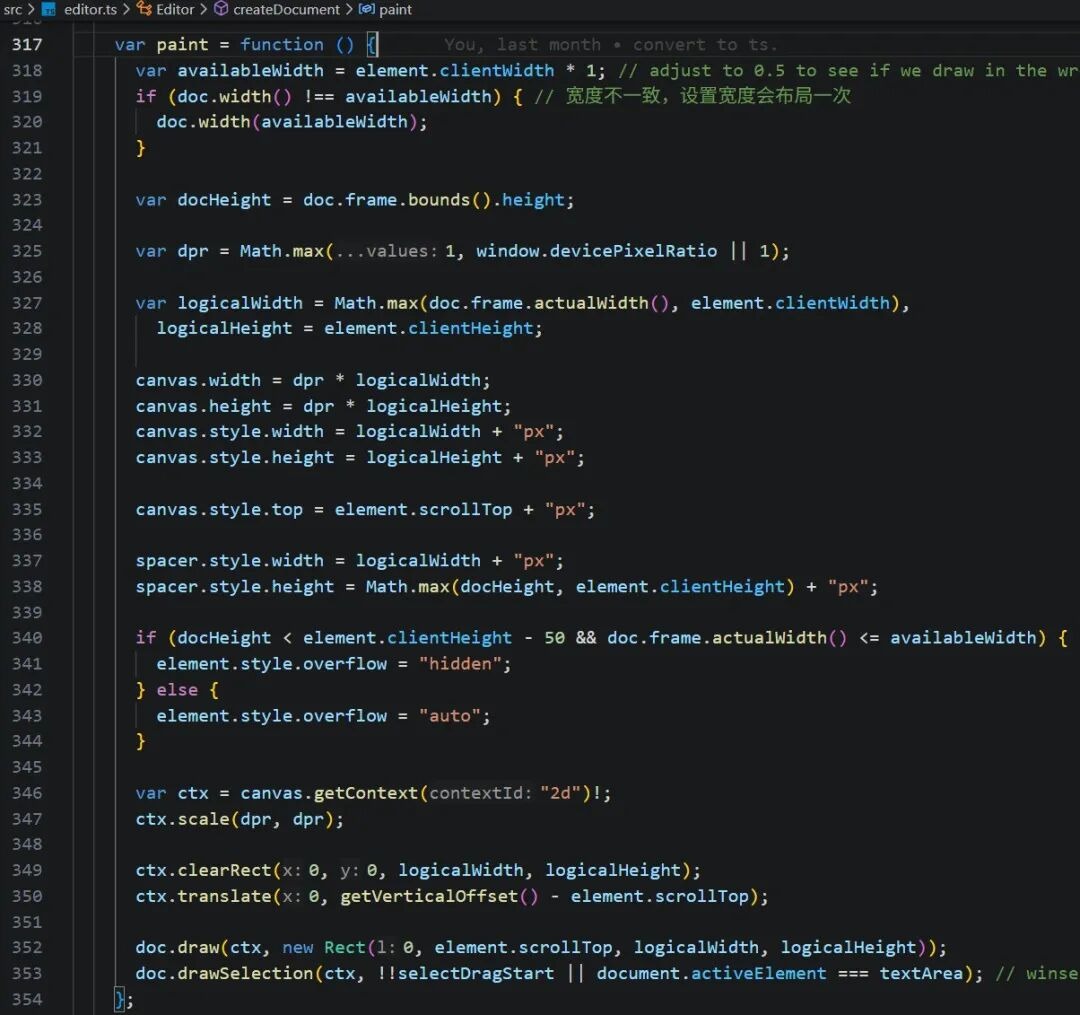
前面布局时,已经算好了每个节点的位置,绘制相对是比较简单的,根据元素位置,判断当前视口 viewport,然后进行绘制。渲染是分层次的。
1)绘制文档树: 调用 document.draw,直接使用父类 Node 的绘制方法。调用其子节点的 Frame.draw。
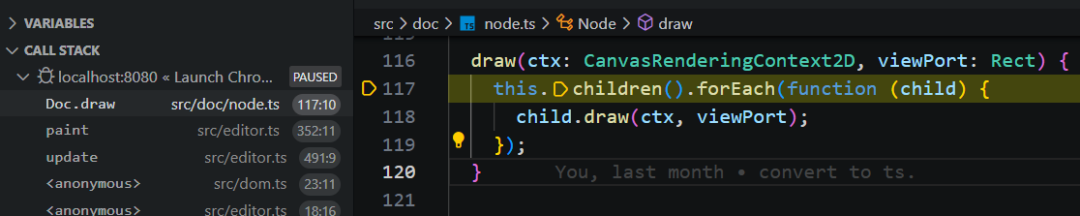
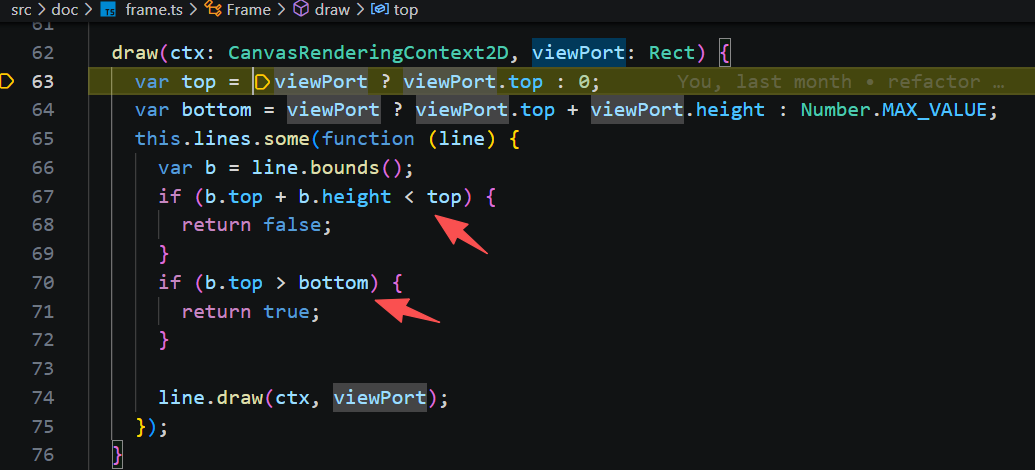
2)绘制行: Frame 会遍历其子元素 lines 。这里进行一些优化,仅绘制在当前视口 viewPort 内的行。
3)绘制单词: Line 对象会调用其子节点 PositionedWord.draw 方法。
注意:PositionedWord 没有直接调用其子节点 PositionedChar 一个一个字符的去绘制,而是调用模型 Word.draw,实现相同样式的 Box 块一起绘制。
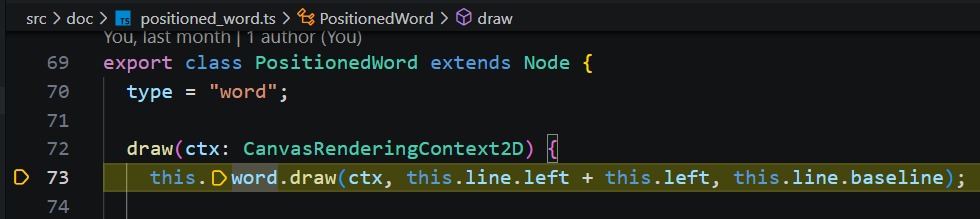
在 Word.draw 方法,参数中已经确定文字的位置,内部的 Box 只需要根据样式与传入的位置直接绘制就行了。
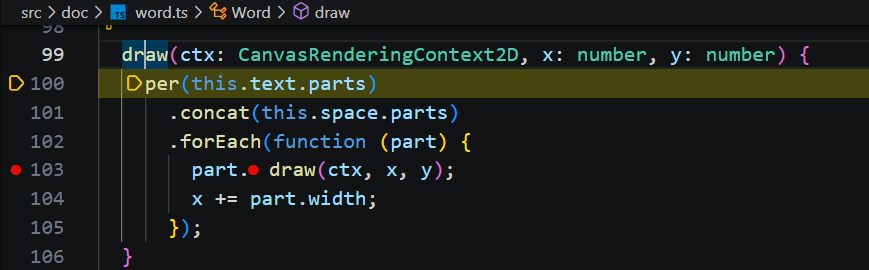

设置画布样式为Box样式(颜色、字体、大小、斜体),根据其位置(left、baseline)调用画布的 fillText 来绘制文字。其中下划线和中划线则通过高度为1的矩形来模拟。
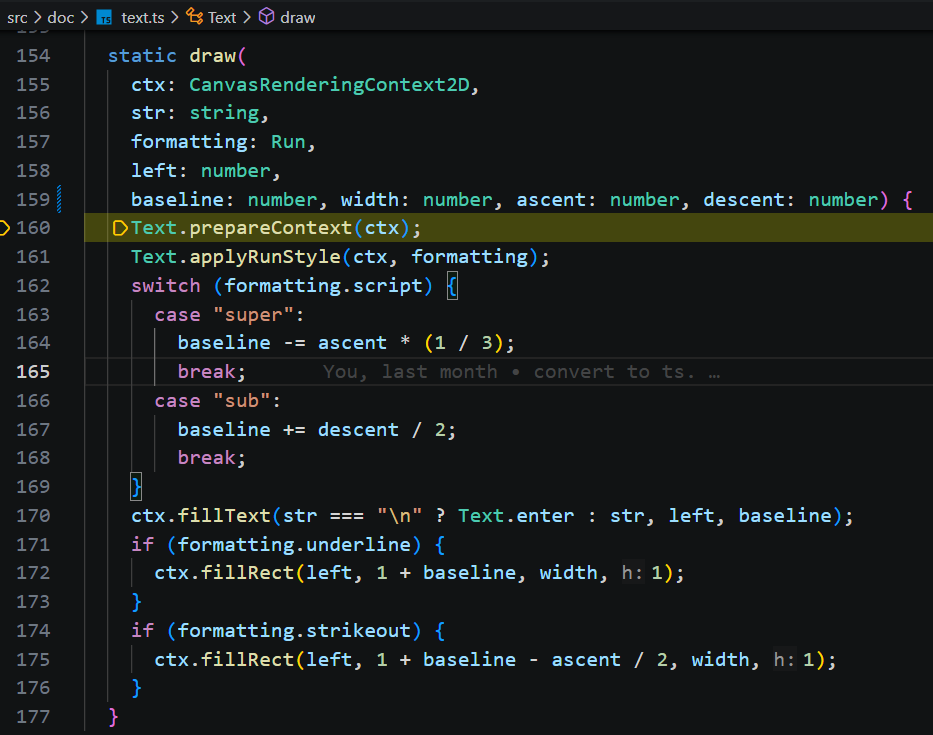
4)渲染选取: 如果单点绘制为Caret光标,如果是区间则绘制矩形。(光标位置后面再研究。)
通过数据解析、布局、最后选区变化事件触发,以及分层渲染,实现了从模型数据变化到屏幕界面的实时同步更新。
问二:编辑器HTML元素是如何建构的?
子问题:
1、初始化传入的是一个普通的div元素,画布元素什么时刻,怎么创建的?
2、当文档内容较长时,滚动是如何实现的?spacer 元素与 canvas 高度如何保持同步?
3、如何实现输入,复制粘贴怎么处理?为什么必须使用 textarea 而不是直接监听 canvas 的键盘事件?
在初始化的时刻,只传入了一个空的div,但运行时动态生成了许多的子元素。这些节点究竟在什么时刻创建的?
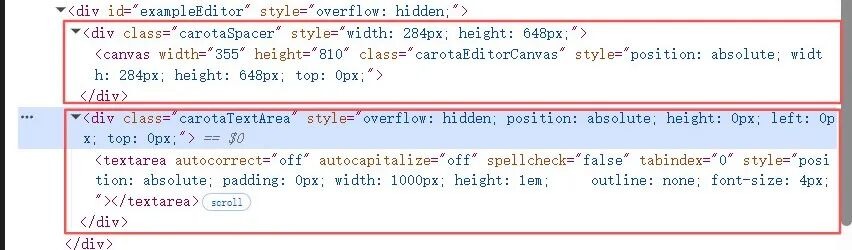
1、动态生成元素
在创建 document 的时刻,它设置了 element 的 innerHTML。这些交互元素是后续操作的基础。
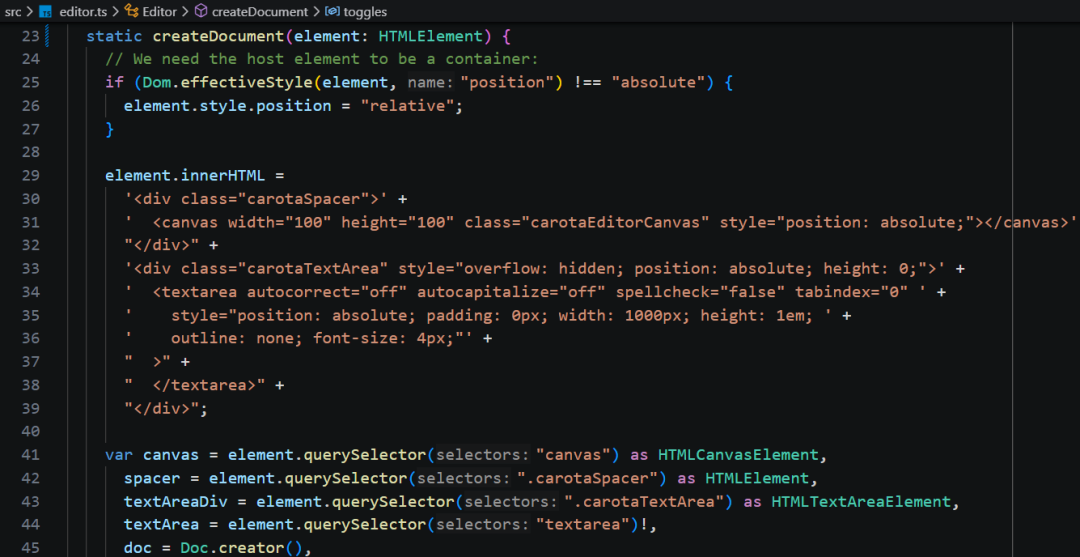
在上一个问题的中,讨论了 paint 方法,它在渲染内容之前调整了 canvas 和 spacer 的高度。这两个元素就是在这里动态创建的,使用两层结构,即做到按需渲染优化性能,同时又保留内容滚动显示:
1)spacer高度与内容高度一致,当超出窗口时实现滚动。
2)canvas高度则设置为可视区域,仅绘制可见区域,性能最优。
元素 textarea 创建用于用户输入,canvas 上无法处理输入 input、处理输入法事件 compositionstart 等。
1)监听 textarea 的 input 事件,输入字符调用 document.insert 方法插入字符。
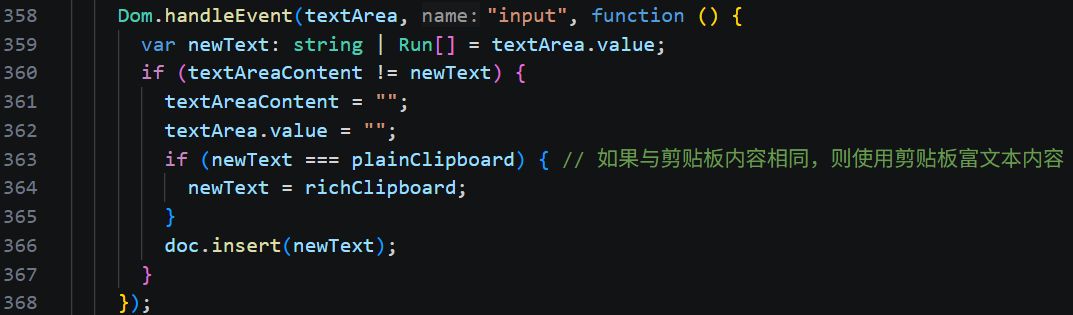
2)当选区变化时,[1]修改 textarea 的位置到光标所在位置,如果有滚动条,则自动滚动到光标处。[2]把选中内容同步到 textarea,这样就可以直接复用浏览器原生的复制/粘贴功能。
总而言之,Carota 编辑器作为一个组件,通过元素动态生成和调整,实现了与用户交互的桥梁。
问三:光标是如何实现的?
在实现编辑器之前,心里始终有几个疑惑:
1、屏幕上光标一闪一闪怎么实现的?
2、点击屏幕,编辑器如何定位到具体的文本为止的?拖拽选择时,屏幕上的矩形区域又是怎么映射到文本区间的?
3、前面看到很多次的 byOrdinal、byCoordinate 方法的作用。
在编辑器中,前端的任何操作都离不开这个“光标”,这是编辑器的灵魂。无论是输入、删除还是选取操作,光标是这一切的开始。
1、动画光标
Carota 并没有依赖浏览器的输入光标,textarea 是一个对用户不可见的元素,它是自己画的。[1]在 paint 的方法中的 doc.drawSelection 中绘制成一条竖线。[2]闪烁效果则通过定时器 周期性的切换“是否绘制”状态来实现。
1)每 200ms 发送一次 carotaEditorSharedTimer 事件。
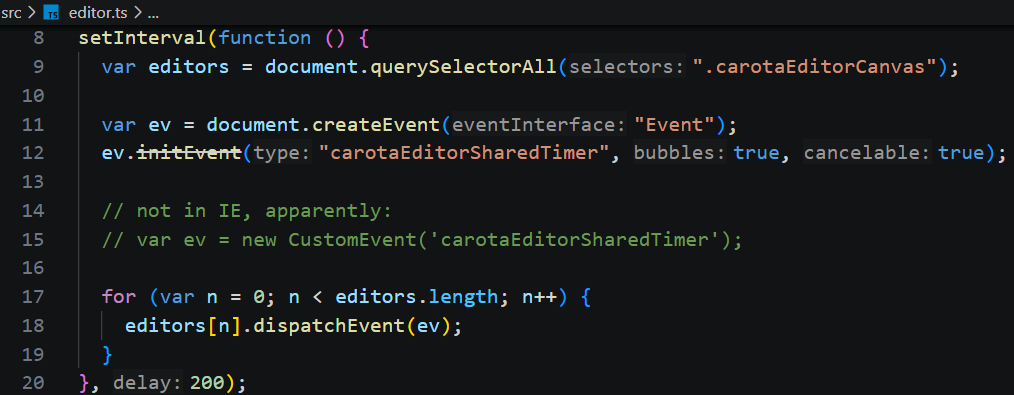
2)监听到事件后,每 500ms 切换一次光标显示状态。
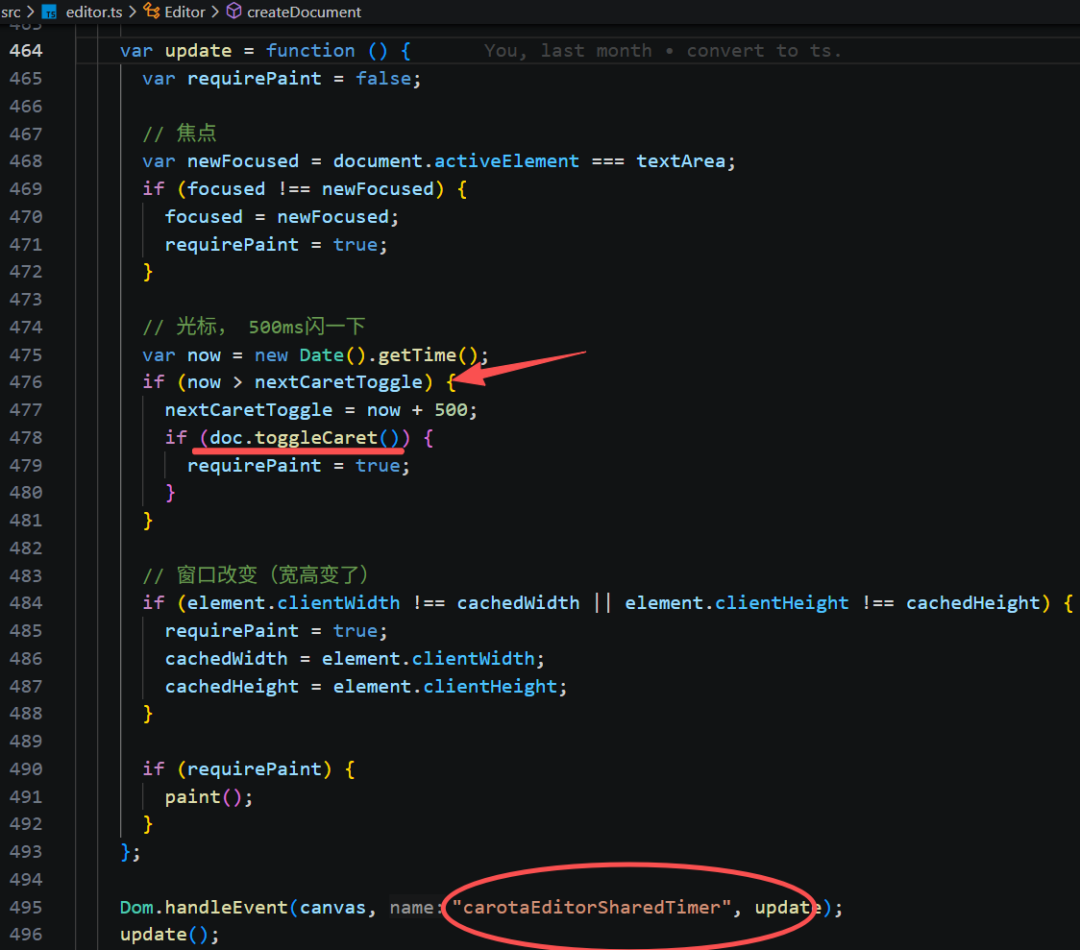
3)切换光标显示状态 caretVisible 的布尔值。
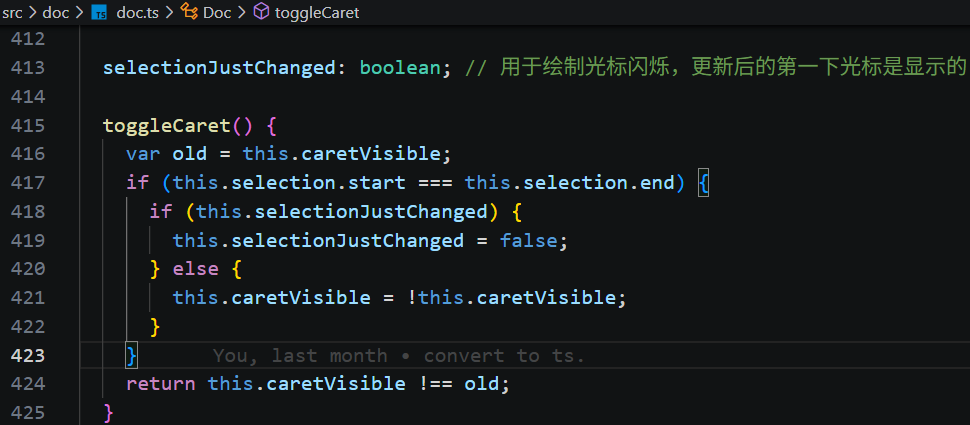
4)在 drawSelection 渲染时,根据 caretVisible 来决定是否绘制光标。
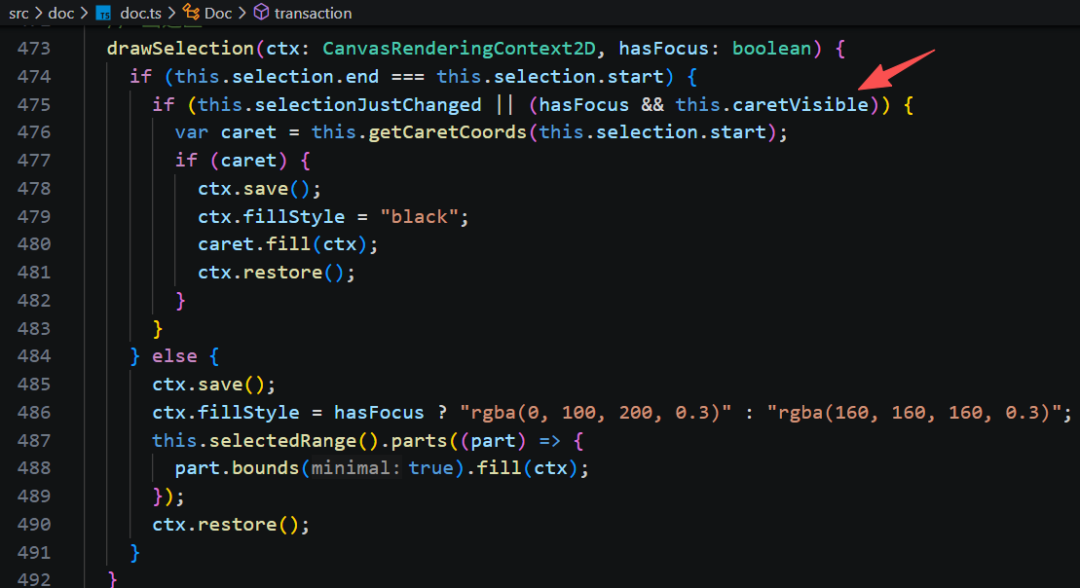
这样就实现了类似系统输入框的闪烁光标效果。
2、坐标和索引的转换
计算光标的位置前,需要先理解选中模型。
在文档存储模型中,不可能把屏幕坐标 作为模型来存储,因为窗口宽高不同、分辨率、缩放比不同,一个因素不同坐标就会完全不同。而文档字符索引独立于显示,以保证光标始终指向那段文本,所以选取中保存的就是文档字符索引ordinal。
尽管存储用文档字符索引,但是,交互和渲染用的是屏幕坐标。这就需要实现二者之间的转换。
1)文档索引 -> 屏幕坐标 (byOrdinal)
从文档树根节点递归,到达字符节点 PositionedChar 对象,字符节点的bounds 可以直接当做光标的位置。
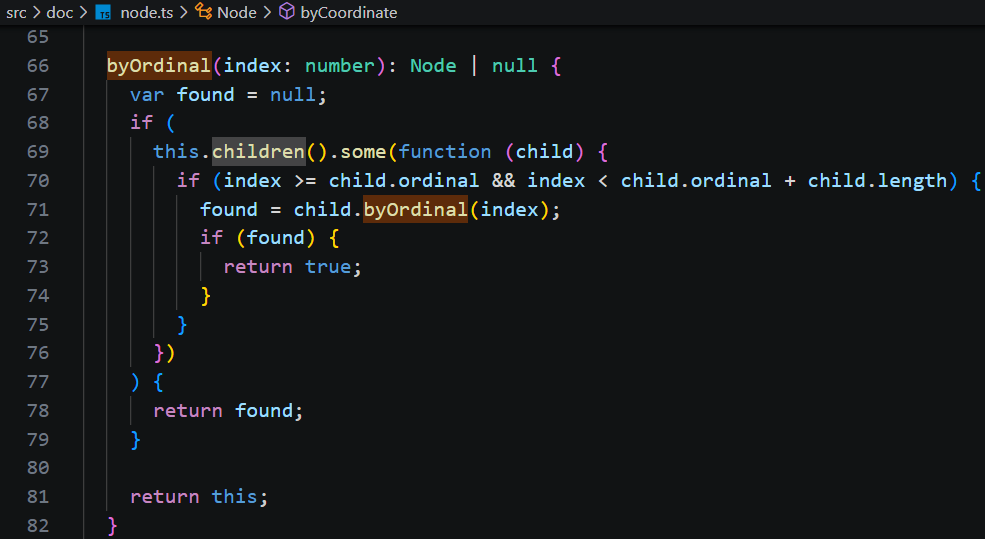

2)屏幕坐标 -> 文档字符索引 (byCoordinate)
其实也是在文档树递归的查找,因为节点在布局的时刻,既保存了节点对应的文档索引,又保存了节点的屏幕位置。
相比来说,屏幕坐标转文档索引需要多考虑一些边界情况:鼠标点到行间空白、文档边缘,要平移贴合到边界的位置。
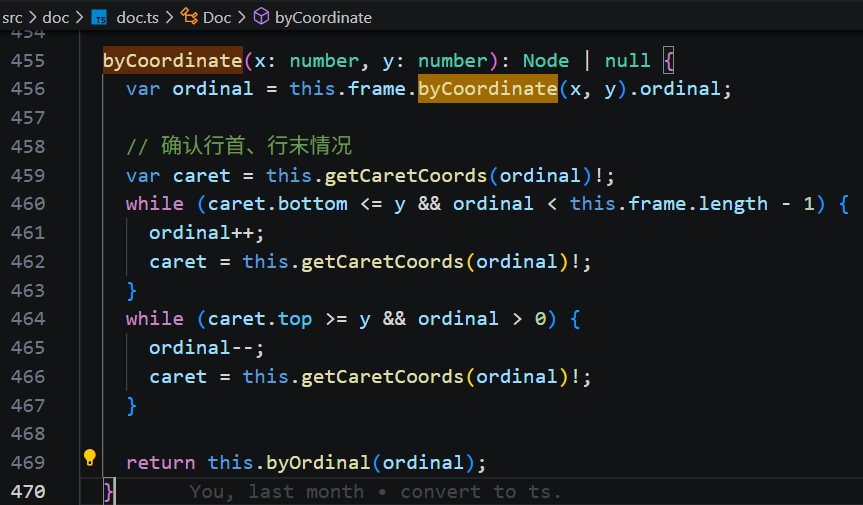
进入到节点的 byCoordinate 方法,就说明这个节点需要处理返回位置信息。(暂不考虑浮动的情况)
注:Carota具体实现略有区别,它是在找不到时,取最后或者下一个节点(最近的)。然后在document层再做检查修正。
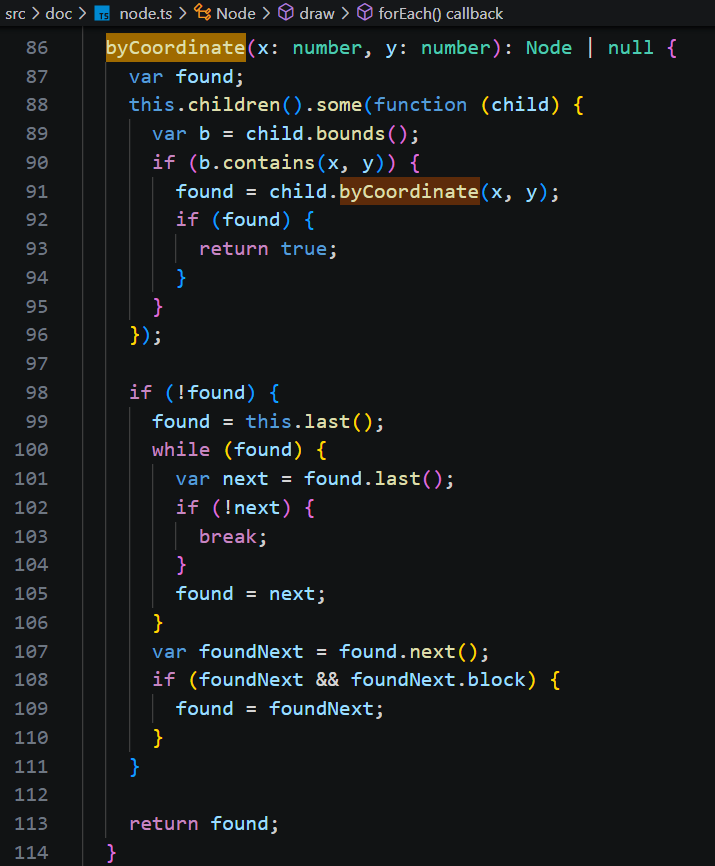
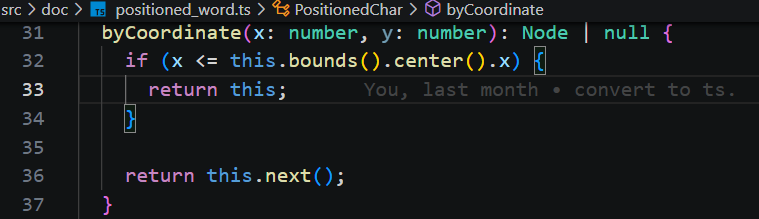
3、光标的位置更新
当我们在编辑器中点击鼠标时,会触发鼠标事件,把鼠标的 屏幕位置 转变成 文档字符索引,更新编辑器的选区。
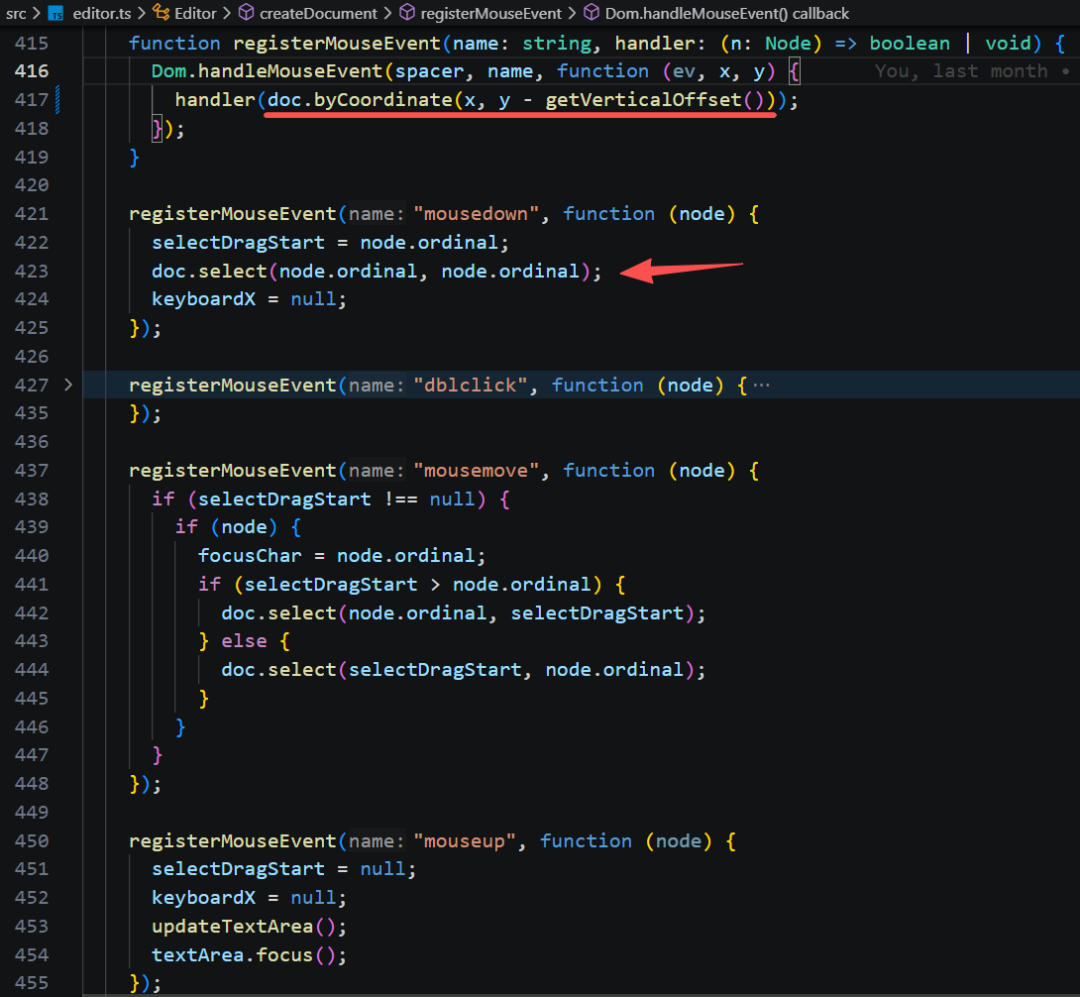
在渲染的时刻,drawSelection 画光标时调用 getCaretCoords 来获取光标位置,其本质就是调用 byOrdinal 得到节点 bounds,并绘制宽度为1的竖线。
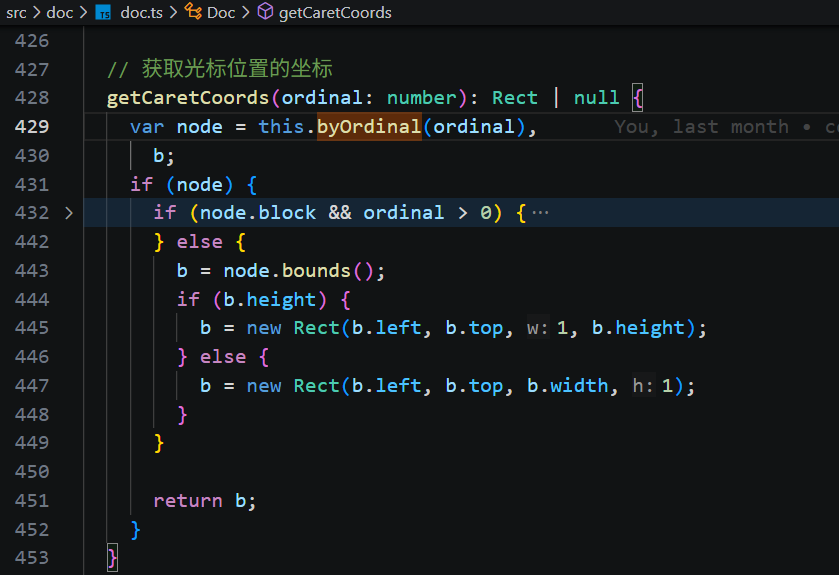
存储基于文档索引,渲染使用屏幕坐标,然后通过定时器实现闪烁显示,实现了完全由自己绘制的动画光标。
问四:增量修改,如何更新渲染
本来没想着写修改的,前面文章已经挺长的了。但是,没有修改Carota的内容就不是完整的。所以,最后还是加上,这个里面也包括比较难理解的事务。
1、插入
前面已经了解,通过不可见的 textarea,监听它的 input 事件,每当有输入,调用 document.insert 插入输入文本。
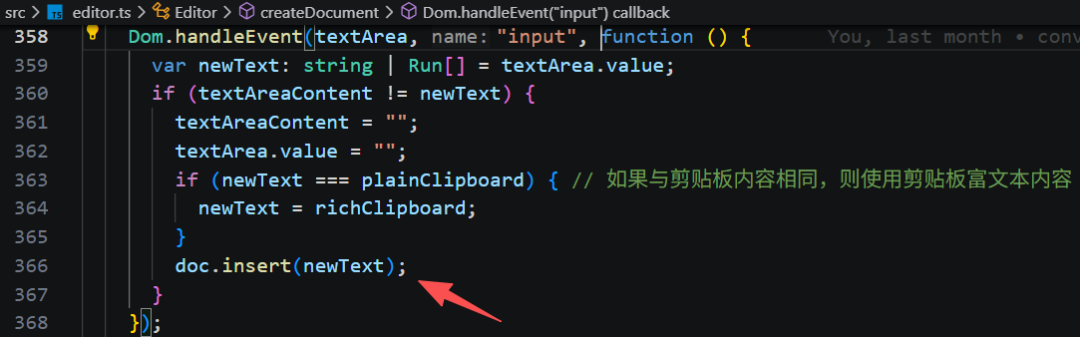
先调用 range.setText 更新当前选取的文本内容,然后更新选区到插入文本之后。
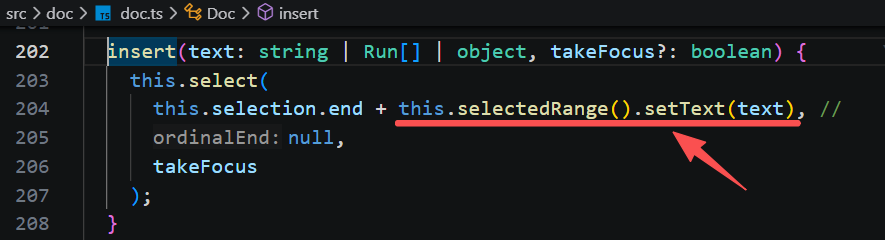
最终调用 document.splice 方法,替换 [start, end)之间的内容为text。
结合前面的知识,数据转换和布局都是围绕 words 去展开的。在此基础上,再理解splice就容易很多。先找出 start,end 所在的 word 的索引,将 run 切分成三部分:start 之前的部分,插入的新文本(转成run)和 end 之后的部分,组成新的 run 数组调用 spliceWordsWithRuns。

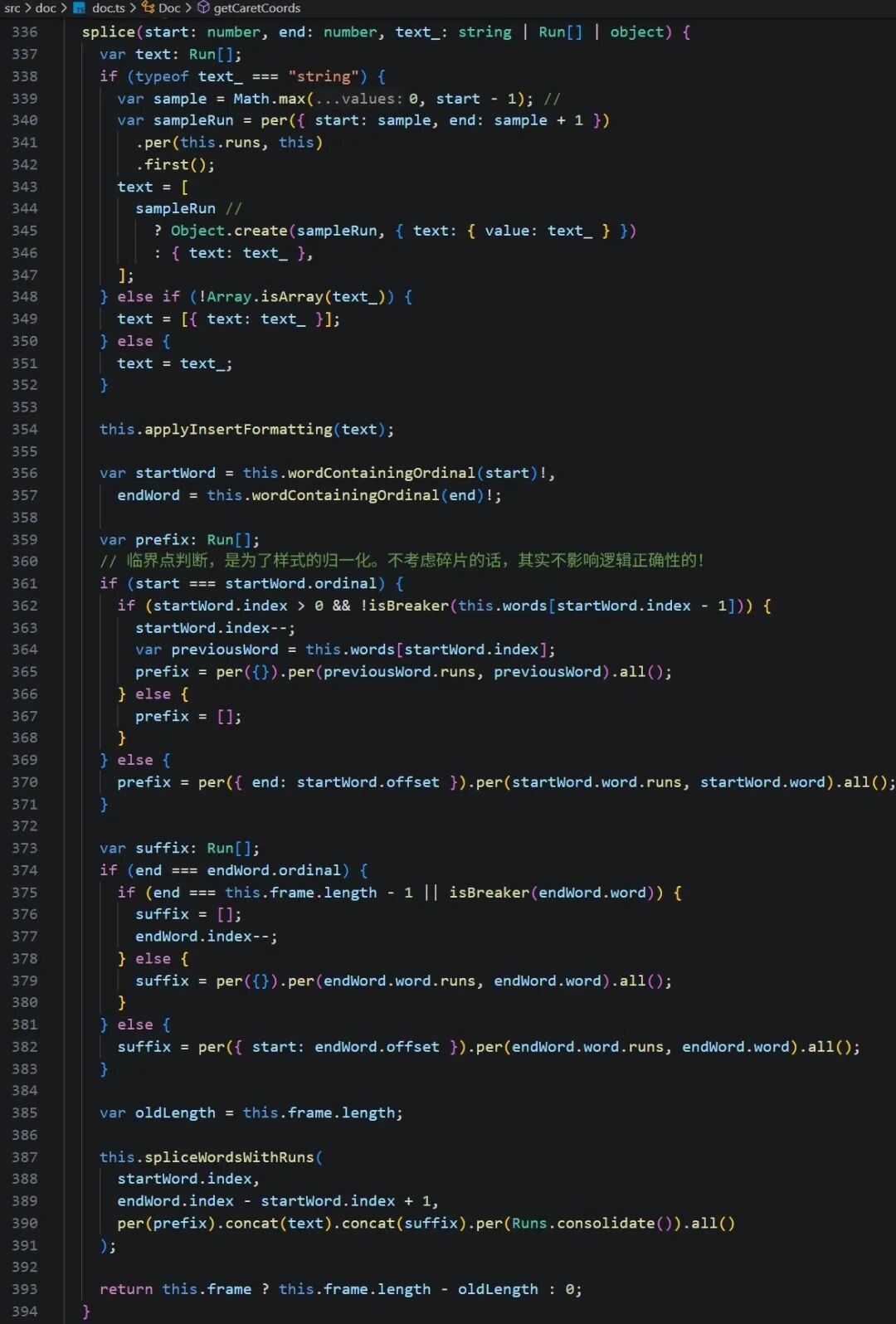
又看到似曾相识的转换:把 run 数组转成 word 数组。替换掉文档的 words 的 wordIndex 开始的 count 区间替换为新的单词。然后,重新布局,更新选区来触发重新渲染,这样就实现了实时修改。
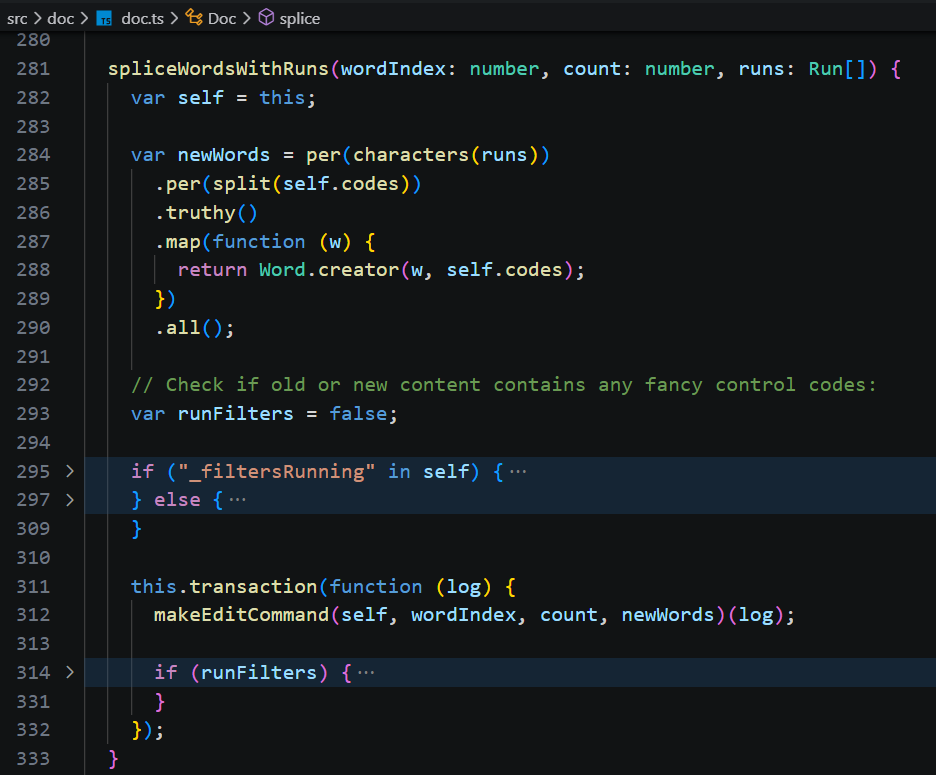
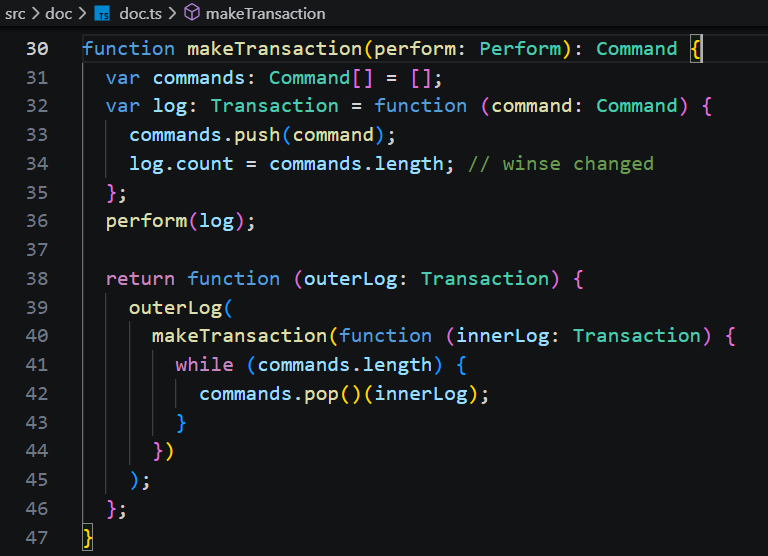
事务的实现并不复杂,但写的比较晦涩。在 makeTransaction 中,会新建一个带命令数组的事务对象,执行当前修改命令的同时,也把对应的“恢复旧words”的命令加入到undo堆栈中。
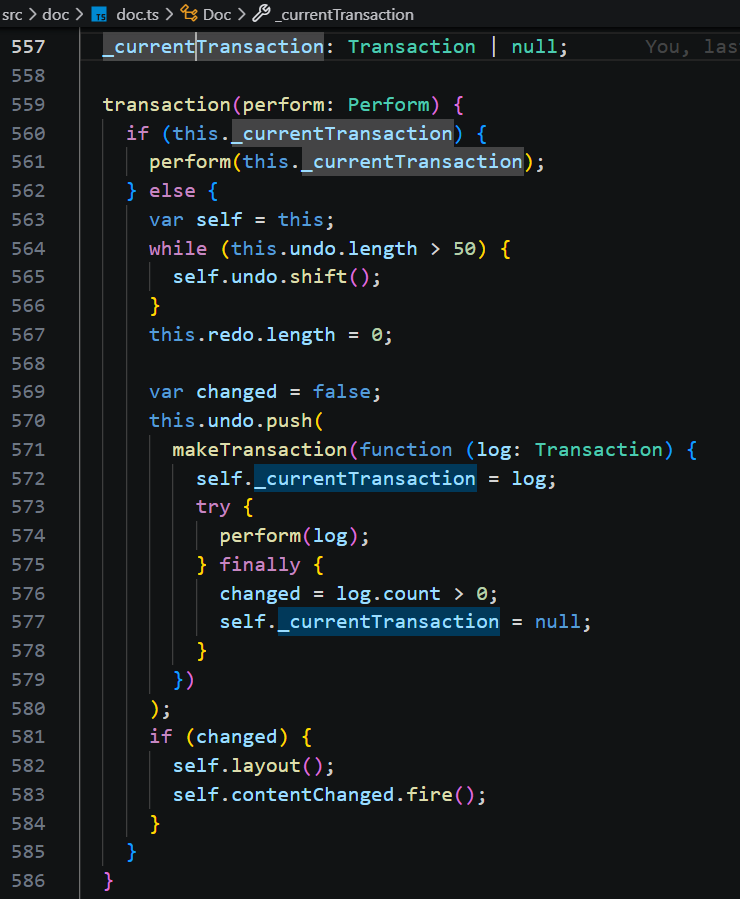
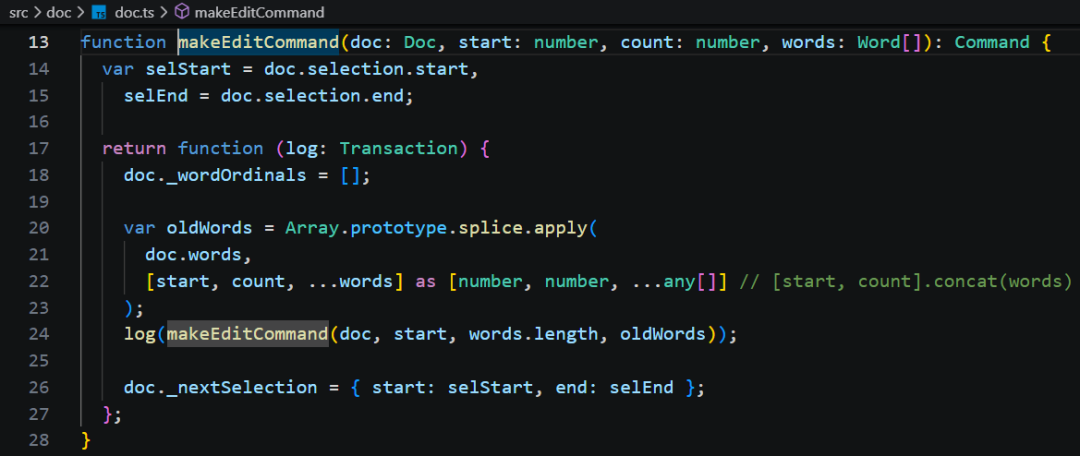
makeEditCommand 核心部分是:数组的 splice 操作。实现替换当前文档的 doc.words 中,把从 start 开始、长度为 count 的区间替换为新的 words,从而完成修改。
2、删除
删除逻辑与插入字符一样的,其实质就是把选区的内容替换为空字符。
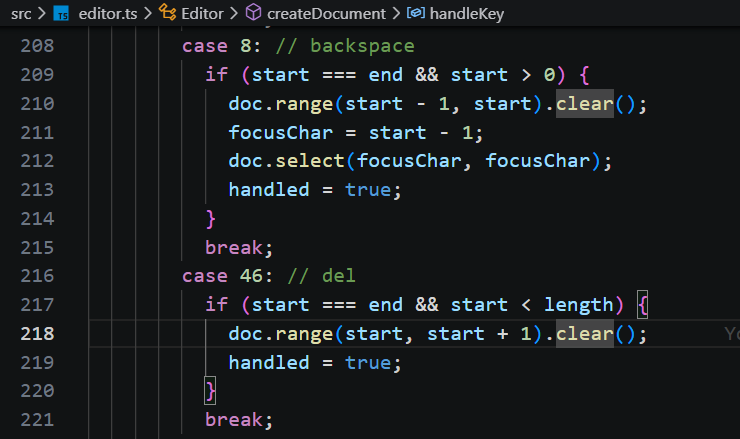

3、更新样式
样式更新的逻辑也与插入类似,最终也是替换选区的“文本”,不过这里的“文本”是带样式的 run 数组。
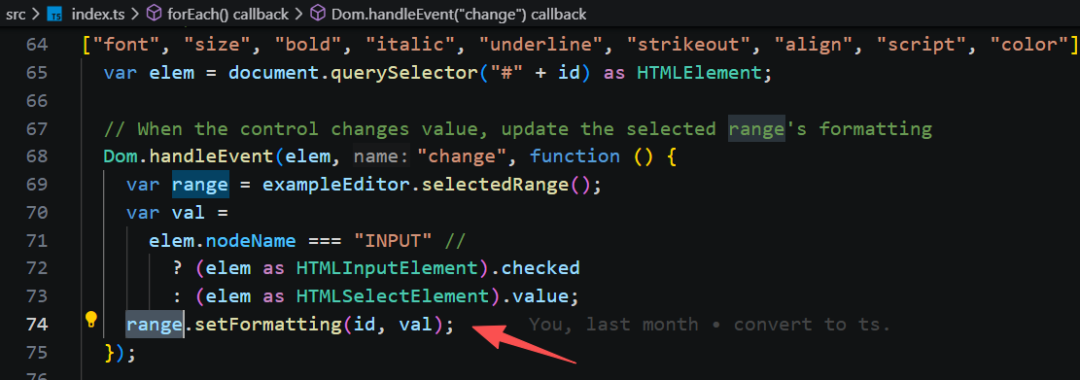
先提取出选区内的 run 数组,然后将设置的样式与旧样式进行合并,得到新样式的 run 数组,然后调用 range.setText 替换区间的内容为最新的run。后面的逻辑就都一样。
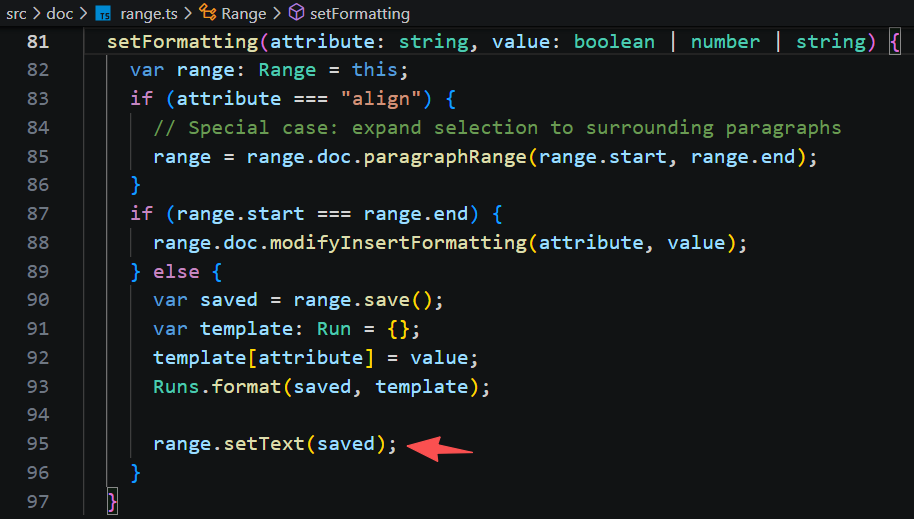
Carota 的修改逻辑,其核心就是:找出选区两端对应 word 的 run,将中间区间替换为新内容的 run,再转换为 words 替换掉旧的,从而完成文档的更新。整个过程被包装在事务中,事务会记录修改起点的 wordIndex、被替换的 count、以及原始的 oldWords,以便在撤销时恢复。
总结
Carota 的核心在于:用最小的抽象,串联起数据、布局、渲染和交互。
-
数据层:以 Run 为基础,承载文本与格式,再逐步转化为 Word、Line、Frame,形成文档树。
-
渲染层:通过布局和视口优化,高效映射到屏幕。
-
交互层:通过隐藏的 textarea 处理输入,光标与选区是连接用户操作与内部模型的桥梁,由 byOrdinal 与 byCoordinate 完成索引与坐标的双向转换。
-
修改统一在事务模型下,完成插入、删除、样式变更,并通过命令与 undo 栈保持可逆操作。
从输入事件到最终的绘制,可以看到 Carota 是完整实现了一套自洽的编辑器引擎。它的价值不只是一个富文本控件,更是一个清晰的范例:如何从数据结构出发,构建出一个可维护、可扩展、可交互的编辑系统。
Related
Related posts
-
从使用者到创造者:用 AI 构建你的专属 VS Code 工具链
2026-02-27
-
富文本编辑器开发学习笔记:跟踪canvas-editor有感,是金子终会发光
2025-09-07
-
深入解析 Nano Banana:Google 技术博客四篇精华翻译
2025-08-30
-
富文本编辑器开发学习笔记:Carota插件
2025-08-27